 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2X-DSC: Multi-Agent Collaborative Perception with Distributed Source Coding Guided Communication
Jan 31, 2026Collaborative perception improves 3D understanding by fusing multi-agent observations, yet intermediate-feature sharing faces strict bandwidth constraints as dense BEV features saturate V2X links. We observe that collaborators view the same physical world, making their features strongly correlated; thus receivers only need innovation beyond their local context. Revisiting this from a distributed source coding perspective, we propose V2X-DSC, a framework with a Conditional Codec (DCC) for bandwidth-constrained fusion. The sender compresses BEV features into compact codes, while the receiver performs conditional reconstruction using its local features as side information, allocating bits to complementary cues rather than redundant content. This conditional structure regularizes learning, encouraging incremental representation and yielding lower-noise features. Experiments on DAIR-V2X, OPV2V, and V2X-Real demonstrate state-of-the-art accuracy-bandwidth trade-offs under KB-level communication, and generalizes as a plug-and-play communication layer across multiple fusion backbones.
From Observations to Events: Event-Aware World Model for Reinforcement Learning
Jan 27, 2026While model-based reinforcement learning (MBRL) improves sample efficiency by learning world models from raw observations, existing methods struggle to generalize across structurally similar scenes and remain vulnerable to spurious variations such as textures or color shifts. From a cognitive science perspective, humans segment continuous sensory streams into discrete events and rely on these key events for decision-making. Motivated by this principle, we propose the Event-Aware World Model (EAWM), a general framework that learns event-aware representations to streamline policy learning without requiring handcrafted labels. EAWM employs an automated event generator to derive events from raw observations and introduces a Generic Event Segmentor (GES) to identify event boundaries, which mark the start and end time of event segments. Through event prediction, the representation space is shaped to capture meaningful spatio-temporal transitions. Beyond this, we present a unified formulation of seemingly distinct world model architectures and show the broad applicability of our methods. Experiments on Atari 100K, Craftax 1M, and DeepMind Control 500K, DMC-GB2 500K demonstrate that EAWM consistently boosts the performance of strong MBRL baselines by 10%-45%, setting new state-of-the-art results across benchmarks. Our code is released at https://github.com/MarquisDarwin/EAWM.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025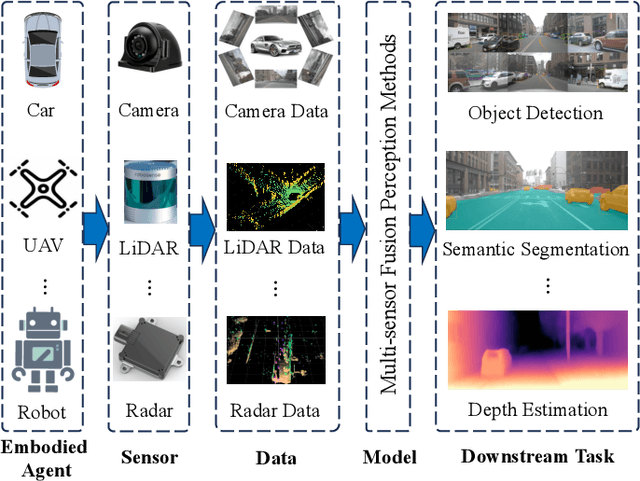
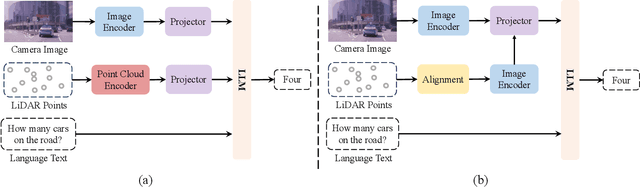
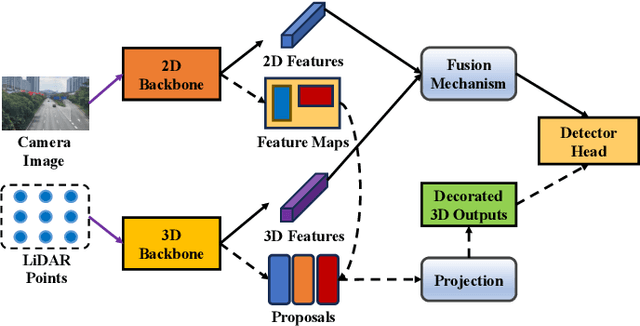
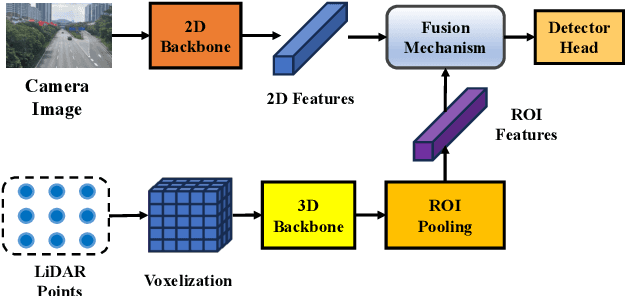
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
SentiFormer: Metadata Enhanced Transformer for Image Sentiment Analysis
Feb 21, 2025As more and more internet users post images online to express their daily emotions, image sentiment analysis has attracted increasing attention. Recently, researchers generally tend to design different neural networks to extract visual features from images for sentiment analysis. Despite the significant progress, metadata, the data (e.g., text descriptions and keyword tags) for describing the image, has not been sufficiently explored in this task. In this paper, we propose a novel Metadata Enhanced Transformer for sentiment analysis (SentiFormer) to fuse multiple metadata and the corresponding image into a unified framework. Specifically, we first obtain multiple metadata of the image and unify the representations of diverse data. To adaptively learn the appropriate weights for each metadata, we then design an adaptive relevance learning module to highlight more effective information while suppressing weaker ones. Moreover, we further develop a cross-modal fusion module to fuse the adaptively learned representations and make the final prediction. Extensive experiments on three publicly available datasets demonstrate the superiority and rationality of our proposed method.
Refining Sentence Embedding Model through Ranking Sentences Generation with Large Language Models
Feb 19, 2025Sentence embedding is essential for many NLP tasks, with contrastive learning methods achieving strong performance using annotated datasets like NLI. Yet, the reliance on manual labels limits scalability. Recent studies leverage large language models (LLMs) to generate sentence pairs, reducing annotation dependency. However, they overlook ranking information crucial for fine-grained semantic distinctions. To tackle this challenge, we propose a method for controlling the generation direction of LLMs in the latent space. Unlike unconstrained generation, the controlled approach ensures meaningful semantic divergence. Then, we refine exist sentence embedding model by integrating ranking information and semantic information. Experiments on multiple benchmarks demonstrate that our method achieves new SOTA performance with a modest cost in ranking sentence synthesis.
Predictive Accuracy-Based Active Learning for Medical Image Segmentation
May 01, 2024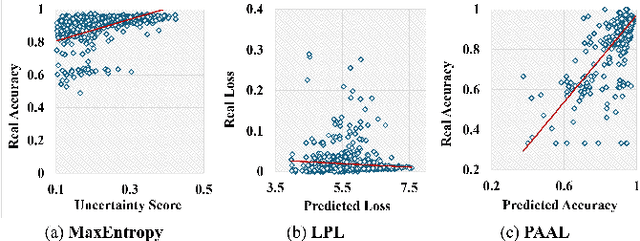
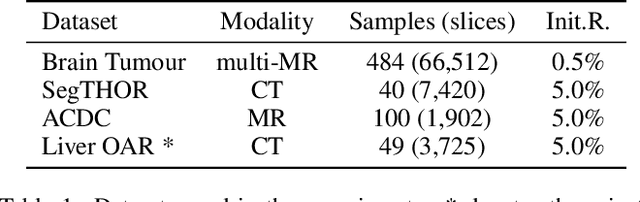
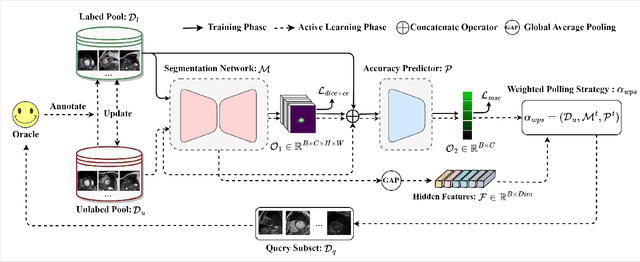
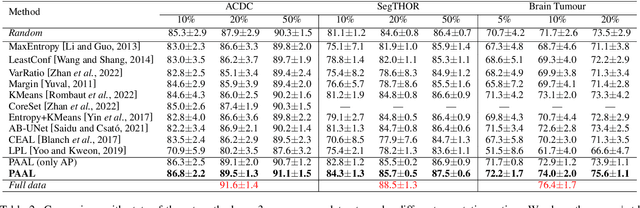
Active learning is considered a viable solution to alleviate the contradiction between the high dependency of deep learning-based segmentation methods on annotated data and the expensive pixel-level annotation cost of medical images. However, most existing methods suffer from unreliable uncertainty assessment and the struggle to balance diversity and informativeness, leading to poor performance in segmentation tasks. In response, we propose an efficient Predictive Accuracy-based Active Learning (PAAL) method for medical image segmentation, first introducing predictive accuracy to define uncertainty. Specifically, PAAL mainly consists of an Accuracy Predictor (AP) and a Weighted Polling Strategy (WPS). The former is an attached learnable module that can accurately predict the segmentation accuracy of unlabeled samples relative to the target model with the predicted posterior probability. The latter provides an efficient hybrid querying scheme by combining predicted accuracy and feature representation, aiming to ensure the uncertainty and diversity of the acquired samples. Extensive experiment results on multiple datasets demonstrate the superiority of PAAL. PAAL achieves comparable accuracy to fully annotated data while reducing annotation costs by approximately 50% to 80%, showcasing significant potential in clinical applications. The code is available at https://github.com/shijun18/PAAL-MedSeg.
H-DenseFormer: An Efficient Hybrid Densely Connected Transformer for Multimodal Tumor Segmentation
Jul 04, 2023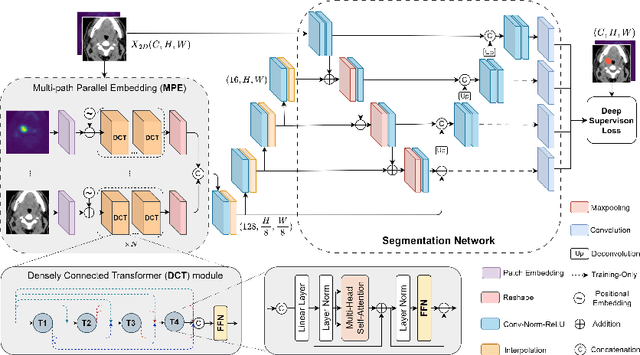

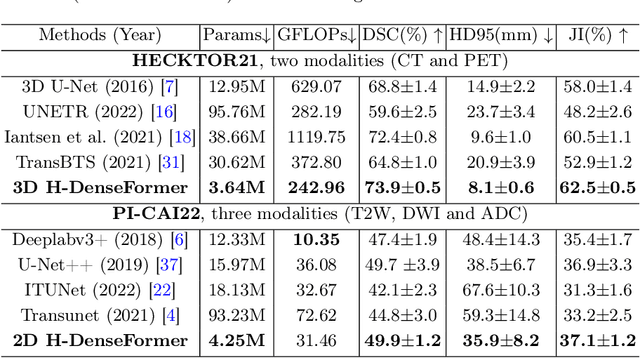
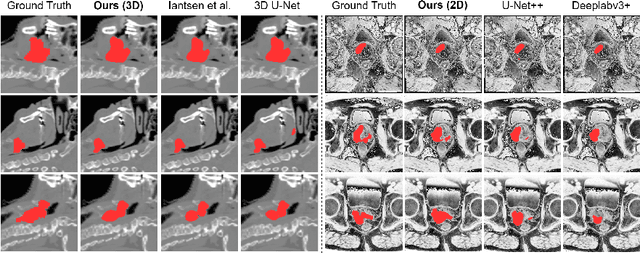
Recently, deep learning methods have been widely used for tumor segmentation of multimodal medical images with promising results. However, most existing methods are limited by insufficient representational ability, specific modality number and high computational complexity. In this paper, we propose a hybrid densely connected network for tumor segmentation, named H-DenseFormer, which combines the representational power of the Convolutional Neural Network (CNN) and the Transformer structures. Specifically, H-DenseFormer integrates a Transformer-based Multi-path Parallel Embedding (MPE) module that can take an arbitrary number of modalities as input to extract the fusion features from different modalities. Then, the multimodal fusion features are delivered to different levels of the encoder to enhance multimodal learning representation. Besides, we design a lightweight Densely Connected Transformer (DCT) block to replace the standard Transformer block, thus significantly reducing computational complexity. We conduct extensive experiments on two public multimodal datasets, HECKTOR21 and PI-CAI22. The experimental results show that our proposed method outperforms the existing state-of-the-art methods while having lower computational complexity. The source code is available at https://github.com/shijun18/H-DenseFormer.
Multi-View Attention Learning for Residual Disease Prediction of Ovarian Cancer
Jun 26, 2023In the treatment of ovarian cancer, precise residual disease prediction is significant for clinical and surgical decision-making. However, traditional methods are either invasive (e.g., laparoscopy) or time-consuming (e.g., manual analysis). Recently, deep learning methods make many efforts in automatic analysis of medical images. Despite the remarkable progress, most of them underestimated the importance of 3D image information of disease, which might brings a limited performance for residual disease prediction, especially in small-scale datasets. To this end, in this paper, we propose a novel Multi-View Attention Learning (MuVAL) method for residual disease prediction, which focuses on the comprehensive learning of 3D Computed Tomography (CT) images in a multi-view manner. Specifically, we first obtain multi-view of 3D CT images from transverse, coronal and sagittal views. To better represent the image features in a multi-view manner, we further leverage attention mechanism to help find the more relevant slices in each view. Extensive experiments on a dataset of 111 patients show that our method outperforms existing deep-learning methods.
Description-Enhanced Label Embedding Contrastive Learning for Text Classification
Jun 15, 2023



Text Classification is one of the fundamental tasks in natural language processing, which requires an agent to determine the most appropriate category for input sentences. Recently, deep neural networks have achieved impressive performance in this area, especially Pre-trained Language Models (PLMs). Usually, these methods concentrate on input sentences and corresponding semantic embedding generation. However, for another essential component: labels, most existing works either treat them as meaningless one-hot vectors or use vanilla embedding methods to learn label representations along with model training, underestimating the semantic information and guidance that these labels reveal. To alleviate this problem and better exploit label information, in this paper, we employ Self-Supervised Learning (SSL) in model learning process and design a novel self-supervised Relation of Relation (R2) classification task for label utilization from a one-hot manner perspective. Then, we propose a novel Relation of Relation Learning Network (R2-Net) for text classification, in which text classification and R2 classification are treated as optimization targets. Meanwhile, triplet loss is employed to enhance the analysis of differences and connections among labels. Moreover, considering that one-hot usage is still short of exploiting label information, we incorporate external knowledge from WordNet to obtain multi-aspect descriptions for label semantic learning and extend R2-Net to a novel Description-Enhanced Label Embedding network (DELE) from a label embedding perspective. ...
DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
Aug 27, 2021



Text-to-image synthesis refers to generating an image from a given text description, the key goal of which lies in photo realism and semantic consistency. Previous methods usually generate an initial image with sentence embedding and then refine it with fine-grained word embedding. Despite the significant progress, the 'aspect' information (e.g., red eyes) contained in the text, referring to several words rather than a word that depicts 'a particular part or feature of something', is often ignored, which is highly helpful for synthesizing image details. How to make better utilization of aspect information in text-to-image synthesis still remains an unresolved challenge. To address this problem, in this paper, we propose a Dynamic Aspect-awarE GAN (DAE-GAN) that represents text information comprehensively from multiple granularities, including sentence-level, word-level, and aspect-level. Moreover, inspired by human learning behaviors, we develop a novel Aspect-aware Dynamic Re-drawer (ADR) for image refinement, in which an Attended Global Refinement (AGR) module and an Aspect-aware Local Refinement (ALR) module are alternately employed. AGR utilizes word-level embedding to globally enhance the previously generated image, while ALR dynamically employs aspect-level embedding to refine image details from a local perspective. Finally, a corresponding matching loss function is designed to ensure the text-image semantic consistency at different levels. Extensive experiments on two well-studied and publicly available datasets (i.e., CUB-200 and COCO) demonstrate the superiority and rationality of our method.