 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Accuracy-Based Active Learning for Medical Image Segmentation
May 01, 2024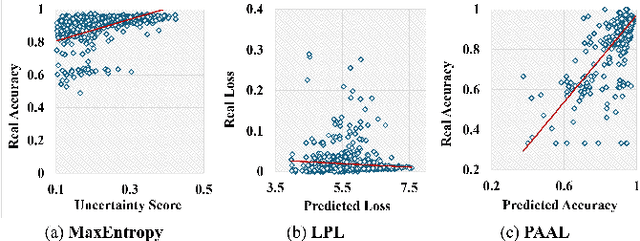
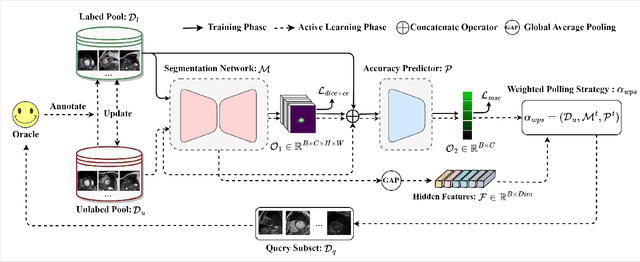
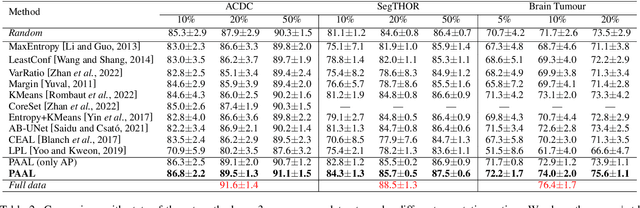
Active learning is considered a viable solution to alleviate the contradiction between the high dependency of deep learning-based segmentation methods on annotated data and the expensive pixel-level annotation cost of medical images. However, most existing methods suffer from unreliable uncertainty assessment and the struggle to balance diversity and informativeness, leading to poor performance in segmentation tasks. In response, we propose an efficient Predictive Accuracy-based Active Learning (PAAL) method for medical image segmentation, first introducing predictive accuracy to define uncertainty. Specifically, PAAL mainly consists of an Accuracy Predictor (AP) and a Weighted Polling Strategy (WPS). The former is an attached learnable module that can accurately predict the segmentation accuracy of unlabeled samples relative to the target model with the predicted posterior probability. The latter provides an efficient hybrid querying scheme by combining predicted accuracy and feature representation, aiming to ensure the uncertainty and diversity of the acquired samples. Extensive experiment results on multiple datasets demonstrate the superiority of PAAL. PAAL achieves comparable accuracy to fully annotated data while reducing annotation costs by approximately 50% to 80%, showcasing significant potential in clinical applications. The code is available at https://github.com/shijun18/PAAL-MedSeg.
H-DenseFormer: An Efficient Hybrid Densely Connected Transformer for Multimodal Tumor Segmentation
Jul 04, 2023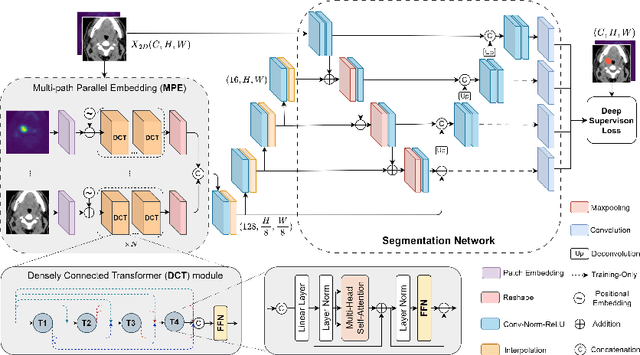

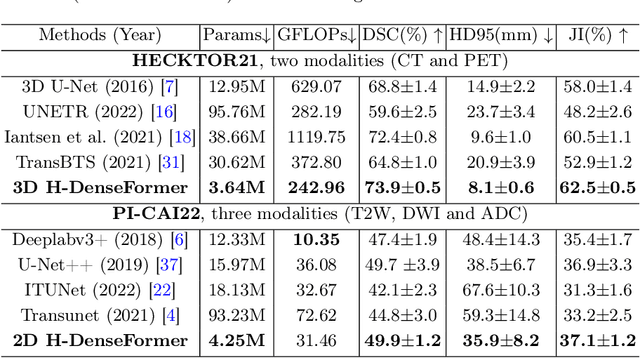
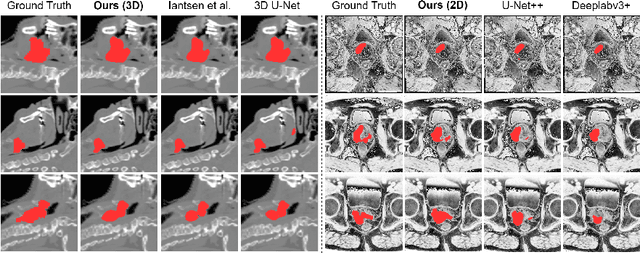
Recently, deep learning methods have been widely used for tumor segmentation of multimodal medical images with promising results. However, most existing methods are limited by insufficient representational ability, specific modality number and high computational complexity. In this paper, we propose a hybrid densely connected network for tumor segmentation, named H-DenseFormer, which combines the representational power of the Convolutional Neural Network (CNN) and the Transformer structures. Specifically, H-DenseFormer integrates a Transformer-based Multi-path Parallel Embedding (MPE) module that can take an arbitrary number of modalities as input to extract the fusion features from different modalities. Then, the multimodal fusion features are delivered to different levels of the encoder to enhance multimodal learning representation. Besides, we design a lightweight Densely Connected Transformer (DCT) block to replace the standard Transformer block, thus significantly reducing computational complexity. We conduct extensive experiments on two public multimodal datasets, HECKTOR21 and PI-CAI22. The experimental results show that our proposed method outperforms the existing state-of-the-art methods while having lower computational complexity. The source code is available at https://github.com/shijun18/H-DenseFormer.