 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamel: Frame-Level Bandwidth Estimation for Low-Latency Live Streaming under Video Bitrate Undershooting
Feb 10, 2026Low-latency live streaming (LLS) has emerged as a popular web application, with many platforms adopting real-time protocols such as WebRTC to minimize end-to-end latency. However, we observe a counter-intuitive phenomenon: even when the actual encoded bitrate does not fully utilize the available bandwidth, stalling events remain frequent. This insufficient bandwidth utilization arises from the intrinsic temporal variations of real-time video encoding, which cause conventional packet-level congestion control algorithms to misestimate available bandwidth. When a high-bitrate frame is suddenly produced, sending at the wrong rate can either trigger packet loss or increase queueing delay, resulting in playback stalls. To address these issues, we present Camel, a novel frame-level congestion control algorithm (CCA) tailored for LLS. Our insight is to use frame-level network feedback to capture the true network capacity, immune to the irregular sending pattern caused by encoding. Camel comprises three key modules: the Bandwidth and Delay Estimator and the Congestion Detector, which jointly determine the average sending rate, and the Bursting Length Controller, which governs the emission pattern to prevent packet loss. We evaluate Camel on both large-scale real-world deployments and controlled simulations. In the real-world platform with 250M users and 2B sessions across 150+ countries, Camel achieves up to a 70.8% increase in 1080P resolution ratio, a 14.4% increase in media bitrate, and up to a 14.1% reduction in stalling ratio. In simulations under undershooting, shallow buffers, and network jitter, Camel outperforms existing congestion control algorithms, with up to 19.8% higher bitrate, 93.0% lower stalling ratio, and 23.9% improvement in bandwidth estimation accuracy.
* 8 pages, 20 figures, to appear in WWW 2026
Adjoint Sampling: Highly Scalable Diffusion Samplers via Adjoint Matching
Apr 16, 2025We introduce Adjoint Sampling, a highly scalable and efficient algorithm for learning diffusion processes that sample from unnormalized densities, or energy functions. It is the first on-policy approach that allows significantly more gradient updates than the number of energy evaluations and model samples, allowing us to scale to much larger problem settings than previously explored by similar methods. Our framework is theoretically grounded in stochastic optimal control and shares the same theoretical guarantees as Adjoint Matching, being able to train without the need for corrective measures that push samples towards the target distribution. We show how to incorporate key symmetries, as well as periodic boundary conditions, for modeling molecules in both cartesian and torsional coordinates. We demonstrate the effectiveness of our approach through extensive experiments on classical energy functions, and further scale up to neural network-based energy models where we perform amortized conformer generation across many molecular systems. To encourage further research in developing highly scalable sampling methods, we plan to open source these challenging benchmarks, where successful methods can directly impact progress in computational chemistry.
MInCo: Mitigating Information Conflicts in Distracted Visual Model-based Reinforcement Learning
Apr 05, 2025



Existing visual model-based reinforcement learning (MBRL) algorithms with observation reconstruction often suffer from information conflicts, making it difficult to learn compact representations and hence result in less robust policies, especially in the presence of task-irrelevant visual distractions. In this paper, we first reveal that the information conflicts in current visual MBRL algorithms stem from visual representation learning and latent dynamics modeling with an information-theoretic perspective. Based on this finding, we present a new algorithm to resolve information conflicts for visual MBRL, named MInCo, which mitigates information conflicts by leveraging negative-free contrastive learning, aiding in learning invariant representation and robust policies despite noisy observations. To prevent the dominance of visual representation learning, we introduce time-varying reweighting to bias the learning towards dynamics modeling as training proceeds. We evaluate our method on several robotic control tasks with dynamic background distractions. Our experiments demonstrate that MInCo learns invariant representations against background noise and consistently outperforms current state-of-the-art visual MBRL methods. Code is available at https://github.com/ShiguangSun/minco.
Predictive Accuracy-Based Active Learning for Medical Image Segmentation
May 01, 2024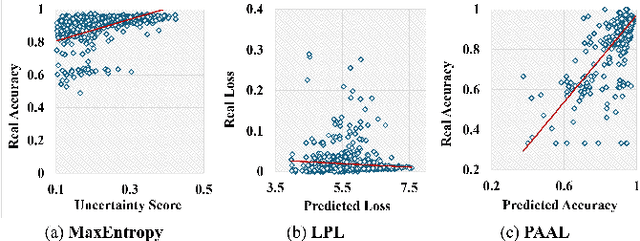
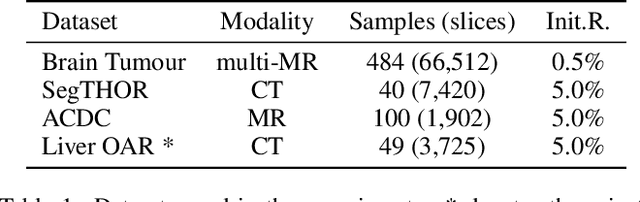
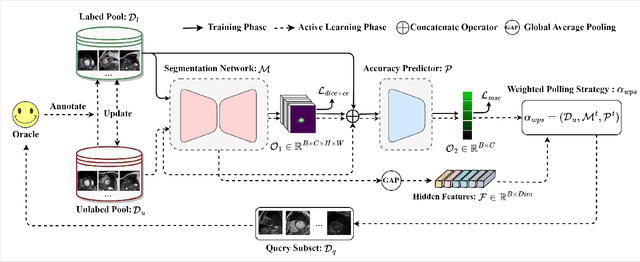
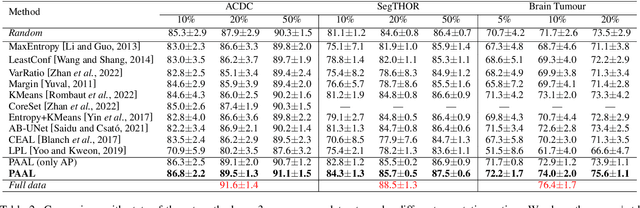
Active learning is considered a viable solution to alleviate the contradiction between the high dependency of deep learning-based segmentation methods on annotated data and the expensive pixel-level annotation cost of medical images. However, most existing methods suffer from unreliable uncertainty assessment and the struggle to balance diversity and informativeness, leading to poor performance in segmentation tasks. In response, we propose an efficient Predictive Accuracy-based Active Learning (PAAL) method for medical image segmentation, first introducing predictive accuracy to define uncertainty. Specifically, PAAL mainly consists of an Accuracy Predictor (AP) and a Weighted Polling Strategy (WPS). The former is an attached learnable module that can accurately predict the segmentation accuracy of unlabeled samples relative to the target model with the predicted posterior probability. The latter provides an efficient hybrid querying scheme by combining predicted accuracy and feature representation, aiming to ensure the uncertainty and diversity of the acquired samples. Extensive experiment results on multiple datasets demonstrate the superiority of PAAL. PAAL achieves comparable accuracy to fully annotated data while reducing annotation costs by approximately 50% to 80%, showcasing significant potential in clinical applications. The code is available at https://github.com/shijun18/PAAL-MedSeg.
Structured Chemistry Reasoning with Large Language Models
Nov 16, 2023This paper studies the problem of solving complex chemistry problems with large language models (LLMs). Despite the extensive general knowledge in LLMs (such as GPT-4), they struggle with chemistry reasoning that requires faithful grounded reasoning with diverse chemical knowledge and an integrative understanding of chemical interactions. We propose InstructChem, a new structured reasoning approach that substantially boosts the LLMs' chemical reasoning capabilities. InstructChem explicitly decomposes the reasoning into three critical phrases, including chemical formulae generation by LLMs that offers the basis for subsequent grounded reasoning, step-by-step reasoning that makes multi-step derivations with the identified formulae for a preliminary answer, and iterative review-and-refinement that steers LLMs to progressively revise the previous phases for increasing confidence, leading to the final high-confidence answer. We conduct extensive experiments on four different chemistry challenges, including quantum chemistry, quantum mechanics, physical chemistry, and chemistry kinetics. Our approach significantly enhances GPT-4 on chemistry reasoning, yielding an 8% average absolute improvement and a 30% peak improvement. We further use the generated reasoning by GPT-4 to fine-tune smaller LMs (e.g., Vicuna) and observe strong improvement of the smaller LMs. This validates our approach and enables LLMs to generate high-quality reasoning.