 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjoint Sampling: Highly Scalable Diffusion Samplers via Adjoint Matching
Apr 16, 2025We introduce Adjoint Sampling, a highly scalable and efficient algorithm for learning diffusion processes that sample from unnormalized densities, or energy functions. It is the first on-policy approach that allows significantly more gradient updates than the number of energy evaluations and model samples, allowing us to scale to much larger problem settings than previously explored by similar methods. Our framework is theoretically grounded in stochastic optimal control and shares the same theoretical guarantees as Adjoint Matching, being able to train without the need for corrective measures that push samples towards the target distribution. We show how to incorporate key symmetries, as well as periodic boundary conditions, for modeling molecules in both cartesian and torsional coordinates. We demonstrate the effectiveness of our approach through extensive experiments on classical energy functions, and further scale up to neural network-based energy models where we perform amortized conformer generation across many molecular systems. To encourage further research in developing highly scalable sampling methods, we plan to open source these challenging benchmarks, where successful methods can directly impact progress in computational chemistry.
All-atom Diffusion Transformers: Unified generative modelling of molecules and materials
Mar 05, 2025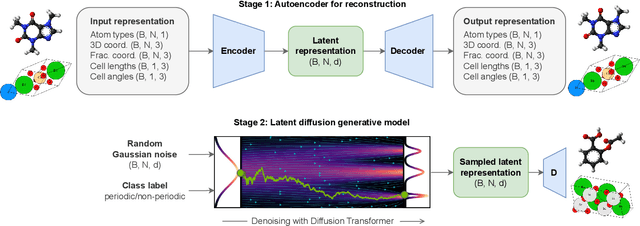

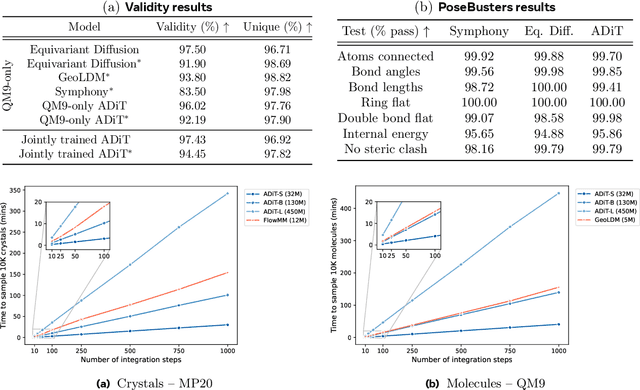
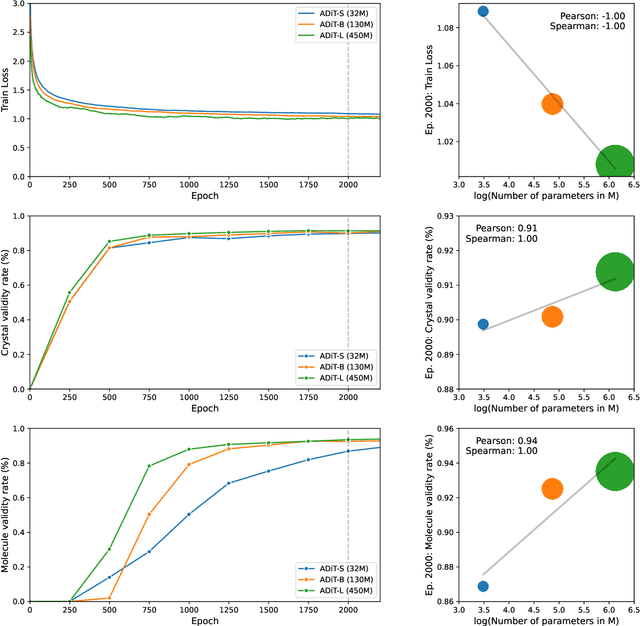
Diffusion models are the standard toolkit for generative modelling of 3D atomic systems. However, for different types of atomic systems - such as molecules and materials - the generative processes are usually highly specific to the target system despite the underlying physics being the same. We introduce the All-atom Diffusion Transformer (ADiT), a unified latent diffusion framework for jointly generating both periodic materials and non-periodic molecular systems using the same model: (1) An autoencoder maps a unified, all-atom representations of molecules and materials to a shared latent embedding space; and (2) A diffusion model is trained to generate new latent embeddings that the autoencoder can decode to sample new molecules or materials. Experiments on QM9 and MP20 datasets demonstrate that jointly trained ADiT generates realistic and valid molecules as well as materials, exceeding state-of-the-art results from molecule and crystal-specific models. ADiT uses standard Transformers for both the autoencoder and diffusion model, resulting in significant speedups during training and inference compared to equivariant diffusion models. Scaling ADiT up to half a billion parameters predictably improves performance, representing a step towards broadly generalizable foundation models for generative chemistry. Open source code: https://github.com/facebookresearch/all-atom-diffusion-transformer
sbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
FlowLLM: Flow Matching for Material Generation with Large Language Models as Base Distributions
Oct 30, 2024Material discovery is a critical area of research with the potential to revolutionize various fields, including carbon capture, renewable energy, and electronics. However, the immense scale of the chemical space makes it challenging to explore all possible materials experimentally. In this paper, we introduce FlowLLM, a novel generative model that combines large language models (LLMs) and Riemannian flow matching (RFM) to design novel crystalline materials. FlowLLM first fine-tunes an LLM to learn an effective base distribution of meta-stable crystals in a text representation. After converting to a graph representation, the RFM model takes samples from the LLM and iteratively refines the coordinates and lattice parameters. Our approach significantly outperforms state-of-the-art methods, increasing the generation rate of stable materials by over three times and increasing the rate for stable, unique, and novel crystals by $\sim50\%$ - a huge improvement on a difficult problem. Additionally, the crystals generated by FlowLLM are much closer to their relaxed state when compared with another leading model, significantly reducing post-hoc computational cost.
FlowMM: Generating Materials with Riemannian Flow Matching
Jun 07, 2024Crystalline materials are a fundamental component in next-generation technologies, yet modeling their distribution presents unique computational challenges. Of the plausible arrangements of atoms in a periodic lattice only a vanishingly small percentage are thermodynamically stable, which is a key indicator of the materials that can be experimentally realized. Two fundamental tasks in this area are to (a) predict the stable crystal structure of a known composition of elements and (b) propose novel compositions along with their stable structures. We present FlowMM, a pair of generative models that achieve state-of-the-art performance on both tasks while being more efficient and more flexible than competing methods. We generalize Riemannian Flow Matching to suit the symmetries inherent to crystals: translation, rotation, permutation, and periodic boundary conditions. Our framework enables the freedom to choose the flow base distributions, drastically simplifying the problem of learning crystal structures compared with diffusion models. In addition to standard benchmarks, we validate FlowMM's generated structures with quantum chemistry calculations, demonstrating that it is about 3x more efficient, in terms of integration steps, at finding stable materials compared to previous open methods.
* https://github.com/facebookresearch/flowmm
Simulation-based Inference with the Generalized Kullback-Leibler Divergence
Oct 03, 2023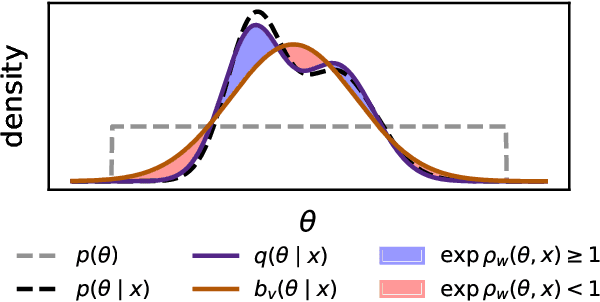
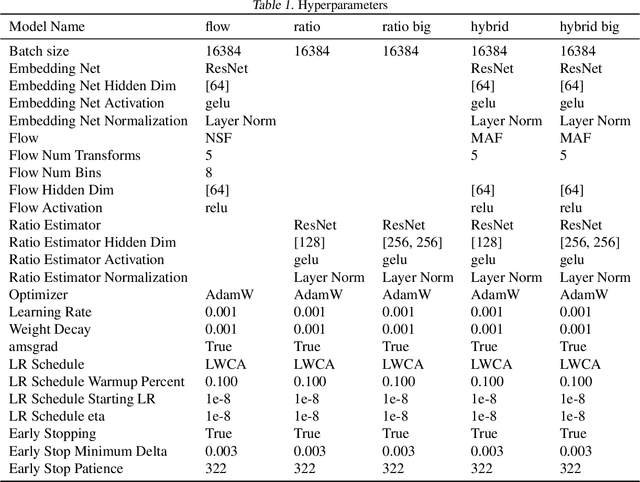
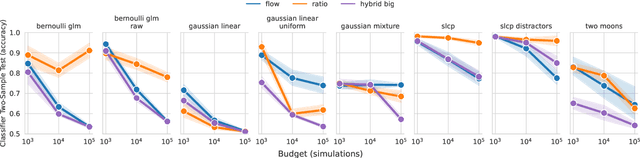
In Simulation-based Inference, the goal is to solve the inverse problem when the likelihood is only known implicitly. Neural Posterior Estimation commonly fits a normalized density estimator as a surrogate model for the posterior. This formulation cannot easily fit unnormalized surrogates because it optimizes the Kullback-Leibler divergence. We propose to optimize a generalized Kullback-Leibler divergence that accounts for the normalization constant in unnormalized distributions. The objective recovers Neural Posterior Estimation when the model class is normalized and unifies it with Neural Ratio Estimation, combining both into a single objective. We investigate a hybrid model that offers the best of both worlds by learning a normalized base distribution and a learned ratio. We also present benchmark results.
Balancing Simulation-based Inference for Conservative Posteriors
Apr 21, 2023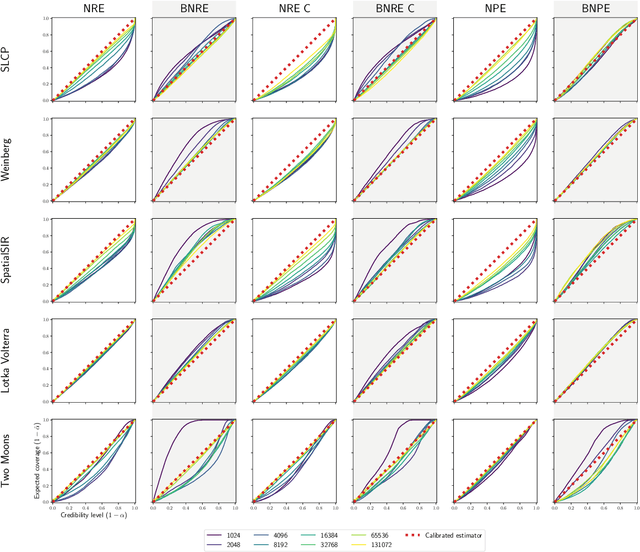
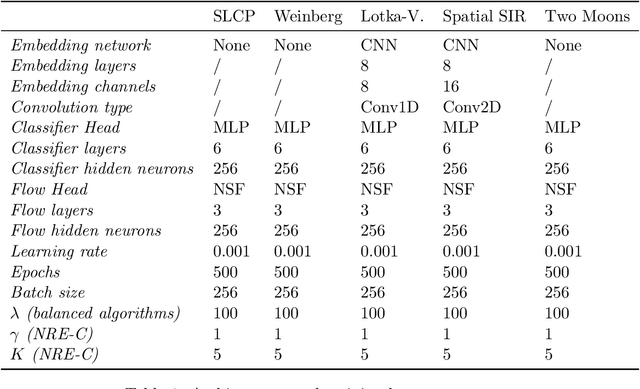
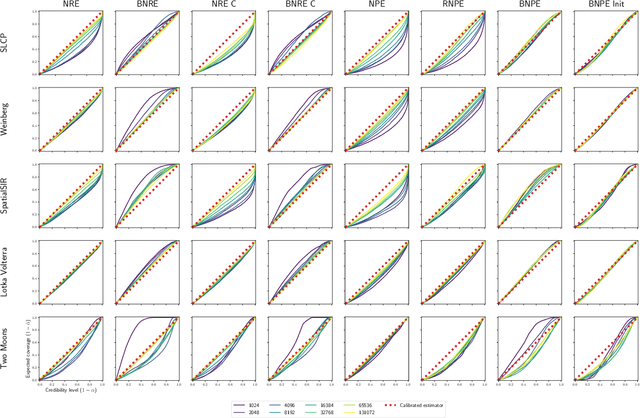
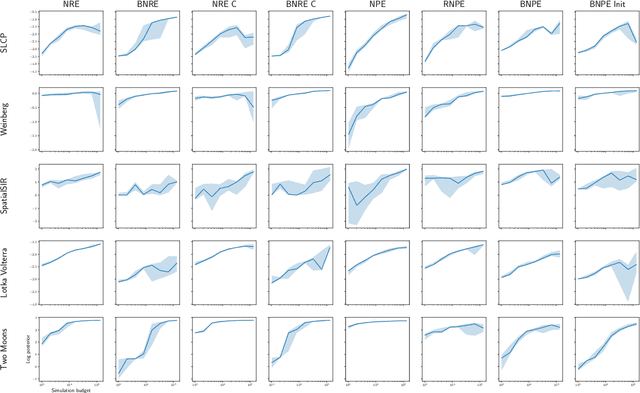
Conservative inference is a major concern in simulation-based inference. It has been shown that commonly used algorithms can produce overconfident posterior approximations. Balancing has empirically proven to be an effective way to mitigate this issue. However, its application remains limited to neural ratio estimation. In this work, we extend balancing to any algorithm that provides a posterior density. In particular, we introduce a balanced version of both neural posterior estimation and contrastive neural ratio estimation. We show empirically that the balanced versions tend to produce conservative posterior approximations on a wide variety of benchmarks. In addition, we provide an alternative interpretation of the balancing condition in terms of the $\chi^2$ divergence.
Contrastive Neural Ratio Estimation
Oct 11, 2022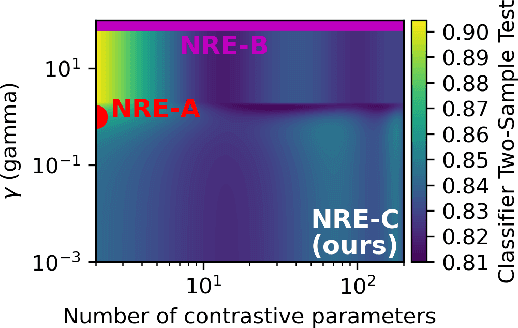
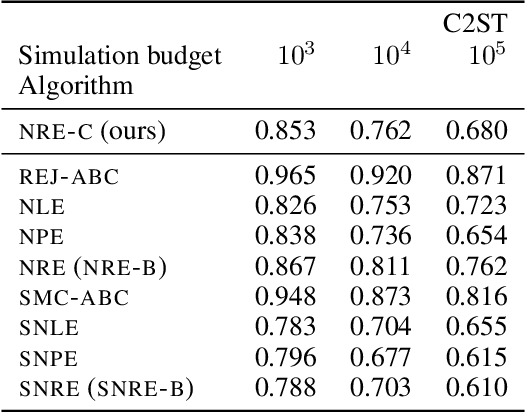
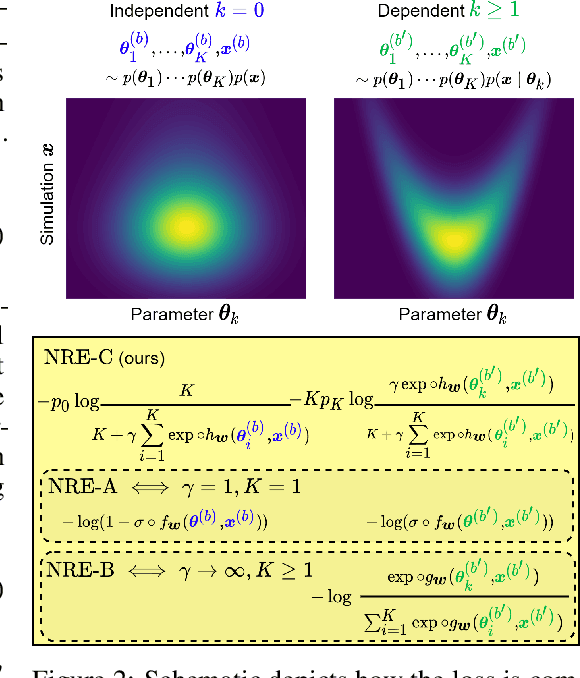
Likelihood-to-evidence ratio estimation is usually cast as either a binary (NRE-A) or a multiclass (NRE-B) classification task. In contrast to the binary classification framework, the current formulation of the multiclass version has an intrinsic and unknown bias term, making otherwise informative diagnostics unreliable. We propose a multiclass framework free from the bias inherent to NRE-B at optimum, leaving us in the position to run diagnostics that practitioners depend on. It also recovers NRE-A in one corner case and NRE-B in the limiting case. For fair comparison, we benchmark the behavior of all algorithms in both familiar and novel training regimes: when jointly drawn data is unlimited, when data is fixed but prior draws are unlimited, and in the commonplace fixed data and parameters setting. Our investigations reveal that the highest performing models are distant from the competitors (NRE-A, NRE-B) in hyperparameter space. We make a recommendation for hyperparameters distinct from the previous models. We suggest a bound on the mutual information as a performance metric for simulation-based inference methods, without the need for posterior samples, and provide experimental results.
Generative Coarse-Graining of Molecular Conformations
Jan 28, 2022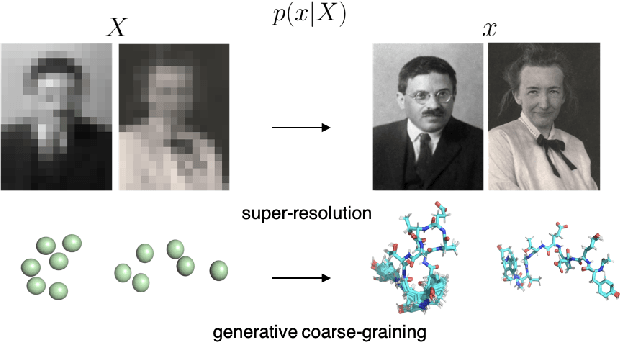

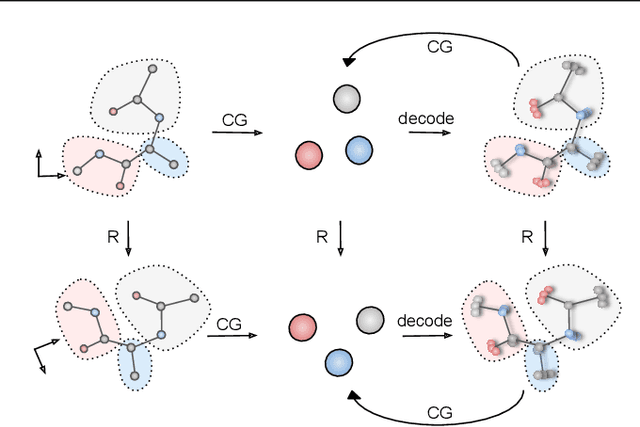
Coarse-graining (CG) of molecular simulations simplifies the particle representation by grouping selected atoms into pseudo-beads and therefore drastically accelerates simulation. However, such CG procedure induces information losses, which makes accurate backmapping, i.e., restoring fine-grained (FG) coordinates from CG coordinates, a long-standing challenge. Inspired by the recent progress in generative models and equivariant networks, we propose a novel model that rigorously embeds the vital probabilistic nature and geometric consistency requirements of the backmapping transformation. Our model encodes the FG uncertainties into an invariant latent space and decodes them back to FG geometries via equivariant convolutions. To standardize the evaluation of this domain, we further provide three comprehensive benchmarks based on molecular dynamics trajectories. Extensive experiments show that our approach always recovers more realistic structures and outperforms existing data-driven methods with a significant margin.
Automatically detecting anomalous exoplanet transits
Nov 16, 2021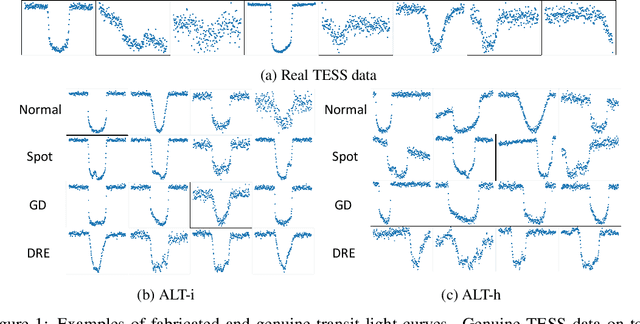



Raw light curve data from exoplanet transits is too complex to naively apply traditional outlier detection methods. We propose an architecture which estimates a latent representation of both the main transit and residual deviations with a pair of variational autoencoders. We show, using two fabricated datasets, that our latent representations of anomalous transit residuals are significantly more amenable to outlier detection than raw data or the latent representation of a traditional variational autoencoder. We then apply our method to real exoplanet transit data. Our study is the first which automatically identifies anomalous exoplanet transit light curves. We additionally release three first-of-their-kind datasets to enable further research.