 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
MINAR: Mechanistic Interpretability for Neural Algorithmic Reasoning
Feb 24, 2026The recent field of neural algorithmic reasoning (NAR) studies the ability of graph neural networks (GNNs) to emulate classical algorithms like Bellman-Ford, a phenomenon known as algorithmic alignment. At the same time, recent advances in large language models (LLMs) have spawned the study of mechanistic interpretability, which aims to identify granular model components like circuits that perform specific computations. In this work, we introduce Mechanistic Interpretability for Neural Algorithmic Reasoning (MINAR), an efficient circuit discovery toolbox that adapts attribution patching methods from mechanistic interpretability to the GNN setting. We show through two case studies that MINAR recovers faithful neuron-level circuits from GNNs trained on algorithmic tasks. Our study sheds new light on the process of circuit formation and pruning during training, as well as giving new insight into how GNNs trained to perform multiple tasks in parallel reuse circuit components for related tasks. Our code is available at https://github.com/pnnl/MINAR.
Which Algorithms Can Graph Neural Networks Learn?
Feb 13, 2026In recent years, there has been growing interest in understanding neural architectures' ability to learn to execute discrete algorithms, a line of work often referred to as neural algorithmic reasoning. The goal is to integrate algorithmic reasoning capabilities into larger neural pipelines. Many such architectures are based on (message-passing) graph neural networks (MPNNs), owing to their permutation equivariance and ability to deal with sparsity and variable-sized inputs. However, existing work is either largely empirical and lacks formal guarantees or it focuses solely on expressivity, leaving open the question of when and how such architectures generalize beyond a finite training set. In this work, we propose a general theoretical framework that characterizes the sufficient conditions under which MPNNs can learn an algorithm from a training set of small instances and provably approximate its behavior on inputs of arbitrary size. Our framework applies to a broad class of algorithms, including single-source shortest paths, minimum spanning trees, and general dynamic programming problems, such as the $0$-$1$ knapsack problem. In addition, we establish impossibility results for a wide range of algorithmic tasks, showing that standard MPNNs cannot learn them, and we derive more expressive MPNN-like architectures that overcome these limitations. Finally, we refine our analysis for the Bellman-Ford algorithm, yielding a substantially smaller required training set and significantly extending the recent work of Nerem et al. [2025] by allowing for a differentiable regularization loss. Empirical results largely support our theoretical findings.
General and Efficient Steering of Unconditional Diffusion
Feb 11, 2026Guiding unconditional diffusion models typically requires either retraining with conditional inputs or per-step gradient computations (e.g., classifier-based guidance), both of which incur substantial computational overhead. We present a general recipe for efficiently steering unconditional diffusion {without gradient guidance during inference}, enabling fast controllable generation. Our approach is built on two observations about diffusion model structure: Noise Alignment: even in early, highly corrupted stages, coarse semantic steering is possible using a lightweight, offline-computed guidance signal, avoiding any per-step or per-sample gradients. Transferable concept vectors: a concept direction in activation space once learned transfers across both {timesteps} and {samples}; the same fixed steering vector learned near low noise level remains effective when injected at intermediate noise levels for every generation trajectory, providing refined conditional control with efficiency. Such concept directions can be efficiently and reliably identified via Recursive Feature Machine (RFM), a light-weight backpropagation-free feature learning method. Experiments on CIFAR-10, ImageNet, and CelebA demonstrate improved accuracy/quality over gradient-based guidance, while achieving significant inference speedups.
Skeletonization of neuronal processes using Discrete Morse techniques from computational topology
May 12, 2025



To understand biological intelligence we need to map neuronal networks in vertebrate brains. Mapping mesoscale neural circuitry is done using injections of tracers that label groups of neurons whose axons project to different brain regions. Since many neurons are labeled, it is difficult to follow individual axons. Previous approaches have instead quantified the regional projections using the total label intensity within a region. However, such a quantification is not biologically meaningful. We propose a new approach better connected to the underlying neurons by skeletonizing labeled axon fragments and then estimating a volumetric length density. Our approach uses a combination of deep nets and the Discrete Morse (DM) technique from computational topology. This technique takes into account nonlocal connectivity information and therefore provides noise-robustness. We demonstrate the utility and scalability of the approach on whole-brain tracer injected data. We also define and illustrate an information theoretic measure that quantifies the additional information obtained, compared to the skeletonized tracer injection fragments, when individual axon morphologies are available. Our approach is the first application of the DM technique to computational neuroanatomy. It can help bridge between single-axon skeletons and tracer injections, two important data types in mapping neural networks in vertebrates.
Graph neural networks extrapolate out-of-distribution for shortest paths
Mar 24, 2025



Neural networks (NNs), despite their success and wide adoption, still struggle to extrapolate out-of-distribution (OOD), i.e., to inputs that are not well-represented by their training dataset. Addressing the OOD generalization gap is crucial when models are deployed in environments significantly different from the training set, such as applying Graph Neural Networks (GNNs) trained on small graphs to large, real-world graphs. One promising approach for achieving robust OOD generalization is the framework of neural algorithmic alignment, which incorporates ideas from classical algorithms by designing neural architectures that resemble specific algorithmic paradigms (e.g. dynamic programming). The hope is that trained models of this form would have superior OOD capabilities, in much the same way that classical algorithms work for all instances. We rigorously analyze the role of algorithmic alignment in achieving OOD generalization, focusing on graph neural networks (GNNs) applied to the canonical shortest path problem. We prove that GNNs, trained to minimize a sparsity-regularized loss over a small set of shortest path instances, exactly implement the Bellman-Ford (BF) algorithm for shortest paths. In fact, if a GNN minimizes this loss within an error of $\epsilon$, it implements the BF algorithm with an error of $O(\epsilon)$. Consequently, despite limited training data, these GNNs are guaranteed to extrapolate to arbitrary shortest-path problems, including instances of any size. Our empirical results support our theory by showing that NNs trained by gradient descent are able to minimize this loss and extrapolate in practice.
Elucidating Flow Matching ODE Dynamics with respect to Data Geometries
Dec 25, 2024Diffusion-based generative models have become the standard for image generation. ODE-based samplers and flow matching models improve efficiency, in comparison to diffusion models, by reducing sampling steps through learned vector fields. However, the theoretical foundations of flow matching models remain limited, particularly regarding the convergence of individual sample trajectories at terminal time - a critical property that impacts sample quality and being critical assumption for models like the consistency model. In this paper, we advance the theory of flow matching models through a comprehensive analysis of sample trajectories, centered on the denoiser that drives ODE dynamics. We establish the existence, uniqueness and convergence of ODE trajectories at terminal time, ensuring stable sampling outcomes under minimal assumptions. Our analysis reveals how trajectories evolve from capturing global data features to local structures, providing the geometric characterization of per-sample behavior in flow matching models. We also explain the memorization phenomenon in diffusion-based training through our terminal time analysis. These findings bridge critical gaps in understanding flow matching models, with practical implications for sampling stability and model design.
DE-HNN: An effective neural model for Circuit Netlist representation
Apr 05, 2024



The run-time for optimization tools used in chip design has grown with the complexity of designs to the point where it can take several days to go through one design cycle which has become a bottleneck. Designers want fast tools that can quickly give feedback on a design. Using the input and output data of the tools from past designs, one can attempt to build a machine learning model that predicts the outcome of a design in significantly shorter time than running the tool. The accuracy of such models is affected by the representation of the design data, which is usually a netlist that describes the elements of the digital circuit and how they are connected. Graph representations for the netlist together with graph neural networks have been investigated for such models. However, the characteristics of netlists pose several challenges for existing graph learning frameworks, due to the large number of nodes and the importance of long-range interactions between nodes. To address these challenges, we represent the netlist as a directed hypergraph and propose a Directional Equivariant Hypergraph Neural Network (DE-HNN) for the effective learning of (directed) hypergraphs. Theoretically, we show that our DE-HNN can universally approximate any node or hyperedge based function that satisfies certain permutation equivariant and invariant properties natural for directed hypergraphs. We compare the proposed DE-HNN with several State-of-the-art (SOTA) machine learning models for (hyper)graphs and netlists, and show that the DE-HNN significantly outperforms them in predicting the outcome of optimized place-and-route tools directly from the input netlists. Our source code and the netlists data used are publicly available at https://github.com/YusuLab/chips.git
On the Theoretical Expressive Power and the Design Space of Higher-Order Graph Transformers
Apr 04, 2024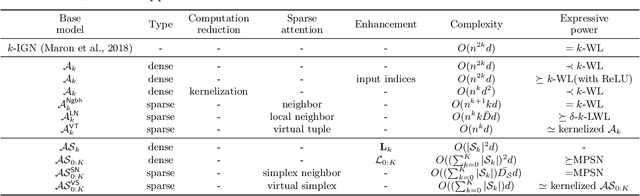
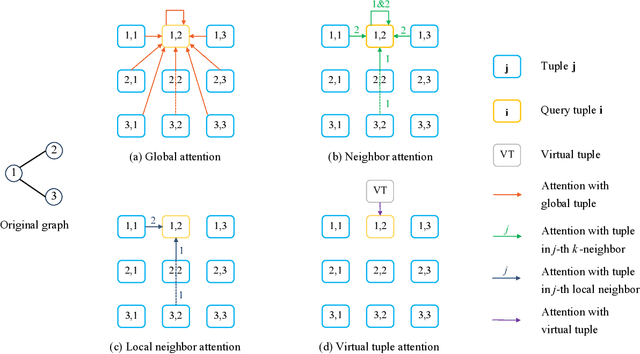


Graph transformers have recently received significant attention in graph learning, partly due to their ability to capture more global interaction via self-attention. Nevertheless, while higher-order graph neural networks have been reasonably well studied, the exploration of extending graph transformers to higher-order variants is just starting. Both theoretical understanding and empirical results are limited. In this paper, we provide a systematic study of the theoretical expressive power of order-$k$ graph transformers and sparse variants. We first show that, an order-$k$ graph transformer without additional structural information is less expressive than the $k$-Weisfeiler Lehman ($k$-WL) test despite its high computational cost. We then explore strategies to both sparsify and enhance the higher-order graph transformers, aiming to improve both their efficiency and expressiveness. Indeed, sparsification based on neighborhood information can enhance the expressive power, as it provides additional information about input graph structures. In particular, we show that a natural neighborhood-based sparse order-$k$ transformer model is not only computationally efficient, but also expressive -- as expressive as $k$-WL test. We further study several other sparse graph attention models that are computationally efficient and provide their expressiveness analysis. Finally, we provide experimental results to show the effectiveness of the different sparsification strategies.
Comparing Graph Transformers via Positional Encodings
Feb 22, 2024The distinguishing power of graph transformers is closely tied to the choice of positional encoding: features used to augment the base transformer with information about the graph. There are two primary types of positional encoding: absolute positional encodings (APEs) and relative positional encodings (RPEs). APEs assign features to each node and are given as input to the transformer. RPEs instead assign a feature to each pair of nodes, e.g., graph distance, and are used to augment the attention block. A priori, it is unclear which method is better for maximizing the power of the resulting graph transformer. In this paper, we aim to understand the relationship between these different types of positional encodings. Interestingly, we show that graph transformers using APEs and RPEs are equivalent in terms of distinguishing power. In particular, we demonstrate how to interchange APEs and RPEs while maintaining their distinguishing power in terms of graph transformers. Based on our theoretical results, we provide a study on several APEs and RPEs (including the resistance distance and the recently introduced stable and expressive positional encoding (SPE)) and compare their distinguishing power in terms of transformers. We believe our work will help navigate the huge number of choices of positional encoding and will provide guidance on the future design of positional encodings for graph transformers.