 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDE-HNN: An effective neural model for Circuit Netlist representation
Apr 05, 2024



The run-time for optimization tools used in chip design has grown with the complexity of designs to the point where it can take several days to go through one design cycle which has become a bottleneck. Designers want fast tools that can quickly give feedback on a design. Using the input and output data of the tools from past designs, one can attempt to build a machine learning model that predicts the outcome of a design in significantly shorter time than running the tool. The accuracy of such models is affected by the representation of the design data, which is usually a netlist that describes the elements of the digital circuit and how they are connected. Graph representations for the netlist together with graph neural networks have been investigated for such models. However, the characteristics of netlists pose several challenges for existing graph learning frameworks, due to the large number of nodes and the importance of long-range interactions between nodes. To address these challenges, we represent the netlist as a directed hypergraph and propose a Directional Equivariant Hypergraph Neural Network (DE-HNN) for the effective learning of (directed) hypergraphs. Theoretically, we show that our DE-HNN can universally approximate any node or hyperedge based function that satisfies certain permutation equivariant and invariant properties natural for directed hypergraphs. We compare the proposed DE-HNN with several State-of-the-art (SOTA) machine learning models for (hyper)graphs and netlists, and show that the DE-HNN significantly outperforms them in predicting the outcome of optimized place-and-route tools directly from the input netlists. Our source code and the netlists data used are publicly available at https://github.com/YusuLab/chips.git
Universal Representation of Permutation-Invariant Functions on Vectors and Tensors
Oct 20, 2023A main object of our study is multiset functions -- that is, permutation-invariant functions over inputs of varying sizes. Deep Sets, proposed by \cite{zaheer2017deep}, provides a \emph{universal representation} for continuous multiset functions on scalars via a sum-decomposable model. Restricting the domain of the functions to finite multisets of $D$-dimensional vectors, Deep Sets also provides a \emph{universal approximation} that requires a latent space dimension of $O(N^D)$ -- where $N$ is an upper bound on the size of input multisets. In this paper, we strengthen this result by proving that universal representation is guaranteed for continuous and discontinuous multiset functions though a latent space dimension of $O(N^D)$. We then introduce \emph{identifiable} multisets for which we can uniquely label their elements using an identifier function, namely, finite-precision vectors are identifiable. Using our analysis on identifiable multisets, we prove that a sum-decomposable model for general continuous multiset functions only requires a latent dimension of $2DN$. We further show that both encoder and decoder functions of the model are continuous -- our main contribution to the existing work which lack such a guarantee. Also this provides a significant improvement over the aforementioned $O(N^D)$ bound which was derived for universal representation of continuous and discontinuous multiset functions. We then extend our results and provide special sum-decomposition structures to universally represent permutation-invariant tensor functions on identifiable tensors. These families of sum-decomposition models enables us to design deep network architectures and deploy them on a variety of learning tasks on sequences, images, and graphs.
Principal Component Analysis in Space Forms
Jan 06, 2023
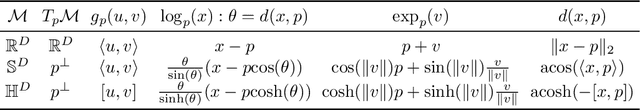


Principal component analysis (PCA) is a workhorse of modern data science. Practitioners typically perform PCA assuming the data conforms to Euclidean geometry. However, for specific data types, such as hierarchical data, other geometrical spaces may be more appropriate. We study PCA in space forms; that is, those with constant positive (spherical) and negative (hyperbolic) curvatures, in addition to zero-curvature (Euclidean) spaces. At any point on a Riemannian manifold, one can define a Riemannian affine subspace based on a set of tangent vectors and use invertible maps to project tangent vectors to the manifold and vice versa. Finding a low-dimensional Riemannian affine subspace for a set of points in a space form amounts to dimensionality reduction because, as we show, any such affine subspace is isometric to a space form of the same dimension and curvature. To find principal components, we seek a (Riemannian) affine subspace that best represents a set of manifold-valued data points with the minimum average cost of projecting data points onto the affine subspace. We propose specific cost functions that bring about two major benefits: (1) the affine subspace can be estimated by solving an eigenequation -- similar to that of Euclidean PCA, and (2) optimal affine subspaces of different dimensions form a nested set. These properties provide advances over existing methods which are mostly iterative algorithms with slow convergence and weaker theoretical guarantees. Specifically for hyperbolic PCA, the associated eigenequation operates in the Lorentzian space, endowed with an indefinite inner product; we thus establish a connection between Lorentzian and Euclidean eigenequations. We evaluate the proposed space form PCA on data sets simulated in spherical and hyperbolic spaces and show that it outperforms alternative methods in convergence speed or accuracy, often both.
HyperAid: Denoising in hyperbolic spaces for tree-fitting and hierarchical clustering
May 19, 2022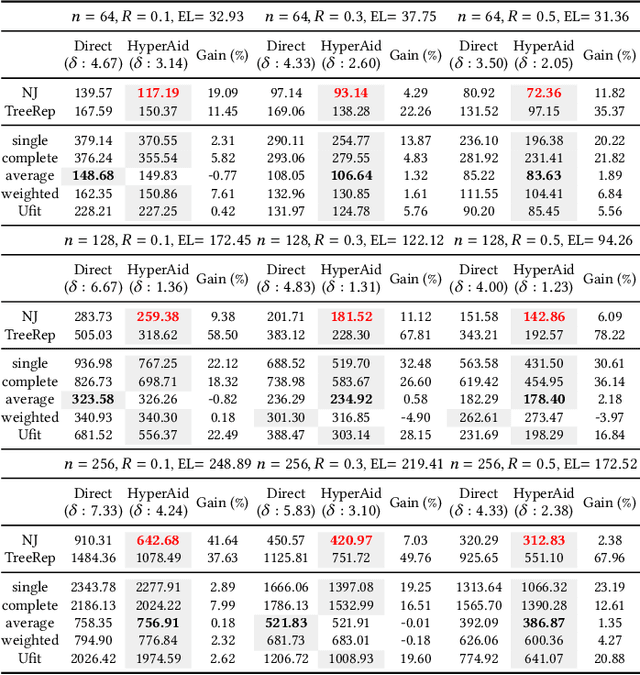

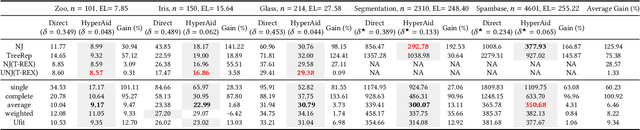

The problem of fitting distances by tree-metrics has received significant attention in the theoretical computer science and machine learning communities alike, due to many applications in natural language processing, phylogeny, cancer genomics and a myriad of problem areas that involve hierarchical clustering. Despite the existence of several provably exact algorithms for tree-metric fitting of data that inherently obeys tree-metric constraints, much less is known about how to best fit tree-metrics for data whose structure moderately (or substantially) differs from a tree. For such noisy data, most available algorithms perform poorly and often produce negative edge weights in representative trees. Furthermore, it is currently not known how to choose the most suitable approximation objective for noisy fitting. Our contributions are as follows. First, we propose a new approach to tree-metric denoising (HyperAid) in hyperbolic spaces which transforms the original data into data that is ``more'' tree-like, when evaluated in terms of Gromov's $\delta$ hyperbolicity. Second, we perform an ablation study involving two choices for the approximation objective, $\ell_p$ norms and the Dasgupta loss. Third, we integrate HyperAid with schemes for enforcing nonnegative edge-weights. As a result, the HyperAid platform outperforms all other existing methods in the literature, including Neighbor Joining (NJ), TreeRep and T-REX, both on synthetic and real-world data. Synthetic data is represented by edge-augmented trees and shortest-distance metrics while the real-world datasets include Zoo, Iris, Glass, Segmentation and SpamBase; on these datasets, the average improvement with respect to NJ is $125.94\%$.
Provably Accurate and Scalable Linear Classifiers in Hyperbolic Spaces
Mar 11, 2022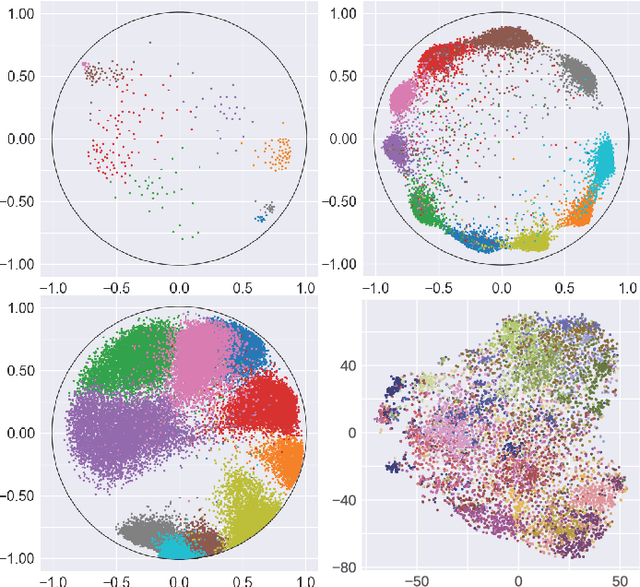

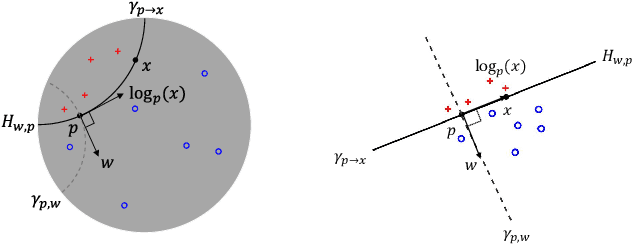
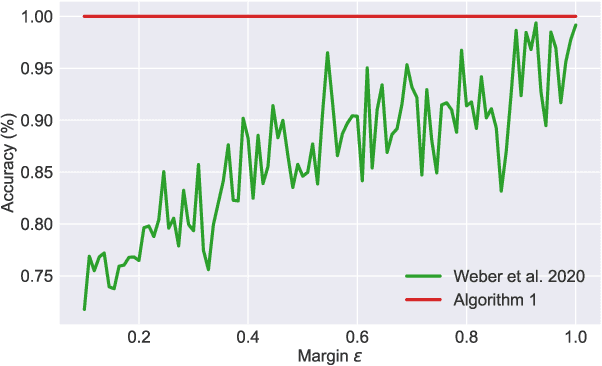
Many high-dimensional practical data sets have hierarchical structures induced by graphs or time series. Such data sets are hard to process in Euclidean spaces and one often seeks low-dimensional embeddings in other space forms to perform the required learning tasks. For hierarchical data, the space of choice is a hyperbolic space because it guarantees low-distortion embeddings for tree-like structures. The geometry of hyperbolic spaces has properties not encountered in Euclidean spaces that pose challenges when trying to rigorously analyze algorithmic solutions. We propose a unified framework for learning scalable and simple hyperbolic linear classifiers with provable performance guarantees. The gist of our approach is to focus on Poincar\'e ball models and formulate the classification problems using tangent space formalisms. Our results include a new hyperbolic perceptron algorithm as well as an efficient and highly accurate convex optimization setup for hyperbolic support vector machine classifiers. Furthermore, we adapt our approach to accommodate second-order perceptrons, where data is preprocessed based on second-order information (correlation) to accelerate convergence, and strategic perceptrons, where potentially manipulated data arrives in an online manner and decisions are made sequentially. The excellent performance of the Poincar\'e second-order and strategic perceptrons shows that the proposed framework can be extended to general machine learning problems in hyperbolic spaces. Our experimental results, pertaining to synthetic, single-cell RNA-seq expression measurements, CIFAR10, Fashion-MNIST and mini-ImageNet, establish that all algorithms provably converge and have complexity comparable to those of their Euclidean counterparts. Accompanying codes can be found at: https://github.com/thupchnsky/PoincareLinearClassification.
Highly Scalable and Provably Accurate Classification in Poincare Balls
Sep 15, 2021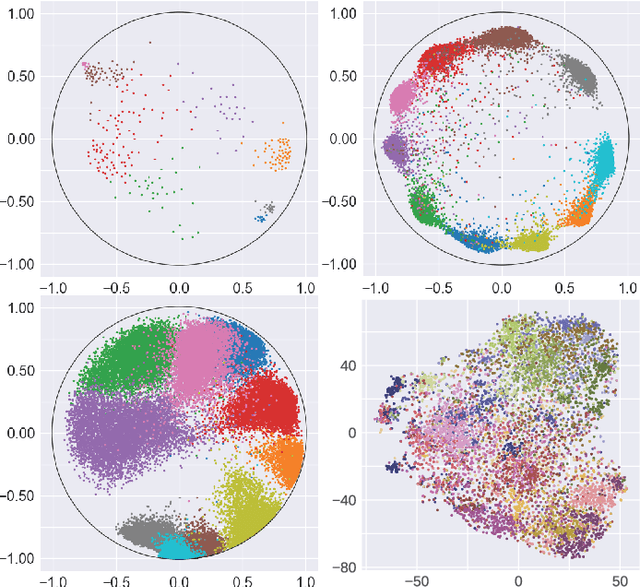
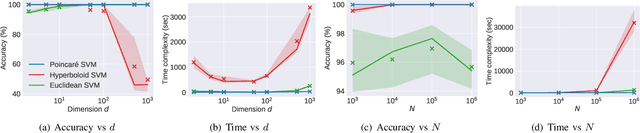
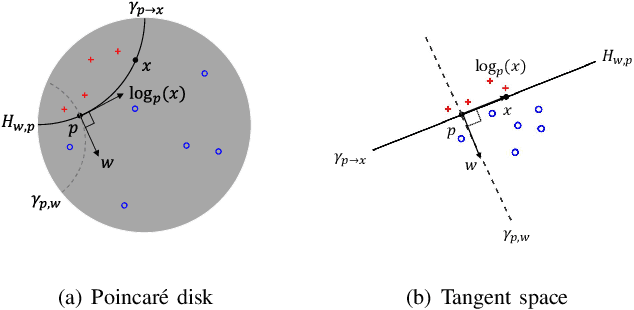
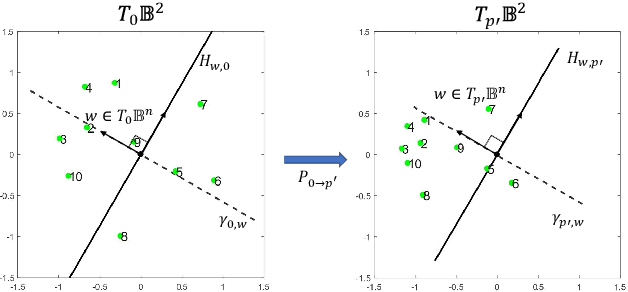
Many high-dimensional and large-volume data sets of practical relevance have hierarchical structures induced by trees, graphs or time series. Such data sets are hard to process in Euclidean spaces and one often seeks low-dimensional embeddings in other space forms to perform required learning tasks. For hierarchical data, the space of choice is a hyperbolic space since it guarantees low-distortion embeddings for tree-like structures. Unfortunately, the geometry of hyperbolic spaces has properties not encountered in Euclidean spaces that pose challenges when trying to rigorously analyze algorithmic solutions. Here, for the first time, we establish a unified framework for learning scalable and simple hyperbolic linear classifiers with provable performance guarantees. The gist of our approach is to focus on Poincar\'e ball models and formulate the classification problems using tangent space formalisms. Our results include a new hyperbolic and second-order perceptron algorithm as well as an efficient and highly accurate convex optimization setup for hyperbolic support vector machine classifiers. All algorithms provably converge and are highly scalable as they have complexities comparable to those of their Euclidean counterparts. Their performance accuracies on synthetic data sets comprising millions of points, as well as on complex real-world data sets such as single-cell RNA-seq expression measurements, CIFAR10, Fashion-MNIST and mini-ImageNet.
Linear Classifiers in Mixed Constant Curvature Spaces
Feb 19, 2021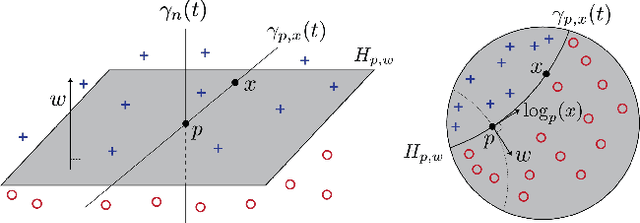

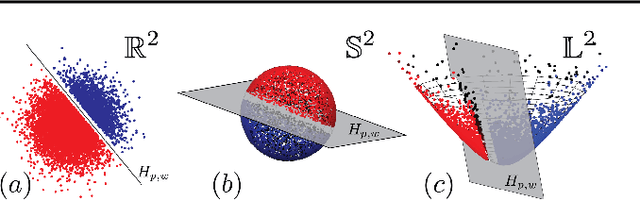
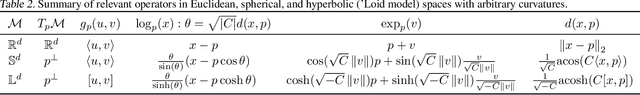
Embedding methods for mixed-curvature spaces are powerful techniques for low-distortion and low-dimensional representation of complex data structures. Nevertheless, little is known regarding downstream learning and optimization in the embedding space. Here, we address for the first time the problem of linear classification in a product space form -- a mix of Euclidean, spherical, and hyperbolic spaces with different dimensions. First, we revisit the definition of a linear classifier on a Riemannian manifold by using geodesics and Riemannian metrics which generalize the notions of straight lines and inner products in vector spaces, respectively. Second, we prove that linear classifiers in $d$-dimensional constant curvature spaces can shatter exactly $d+1$ points: Hence, Euclidean, hyperbolic and spherical classifiers have the same expressive power. Third, we formalize linear classifiers in product space forms, describe a novel perceptron classification algorithm, and establish rigorous convergence results. We support our theoretical findings with simulation results on several datasets, including synthetic data, MNIST and Omniglot. Our results reveal that learning methods applied to small-dimensional embeddings in product space forms significantly outperform their algorithmic counterparts in Euclidean spaces.
On Procrustes Analysis in Hyperbolic Space
Feb 07, 2021
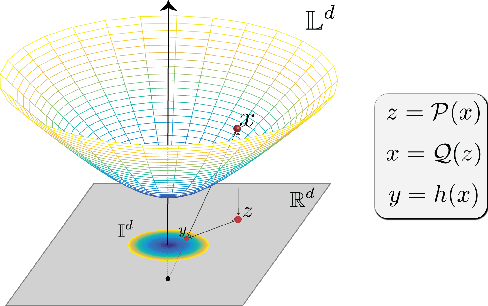
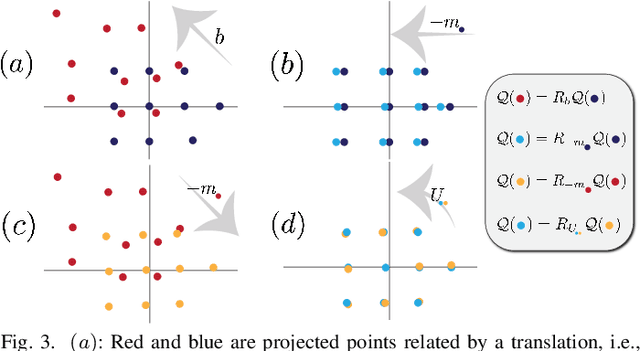
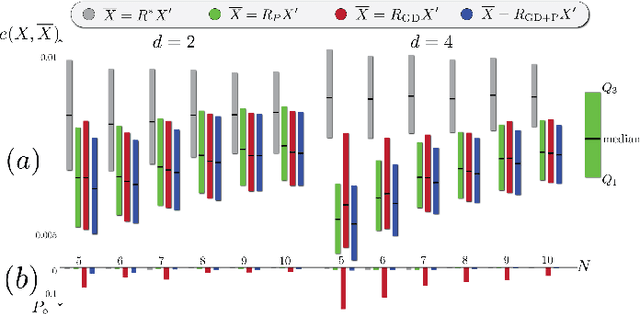
Congruent Procrustes analysis aims to find the best matching between two point sets through rotation, reflection and translation. We formulate the Procrustes problem for hyperbolic spaces, review the canonical definition of the center of point sets, and give a closed form solution for the optimal isometry for noise-free measurements. We also analyze the performance of the proposed method under measurement noise.
Geometry of Comparisons
Jun 17, 2020



Many data analysis problems can be cast as distance geometry problems in \emph{space forms}---Euclidean, elliptic, or hyperbolic spaces. We ask: what can be said about the dimension of the underlying space form if we are only given a subset of comparisons between pairwise distances, without computing an actual embedding? To study this question, we define the \textit{ordinal capacity} of a metric space. Ordinal capacity measures how well a space can accommodate a given set of ordinal measurements. We prove that the ordinal capacity of a space form is related to its dimension and curvature sign, and provide a lower bound on the embedding dimension of non-metric graphs in terms of the \textit{ordinal spread} of their sub-cliques. Computer experiments on random graphs, Bitcoin trust network, and olfactory data illustrate the theory.
Hyperbolic Distance Matrices
May 18, 2020



Hyperbolic space is a natural setting for mining and visualizing data with hierarchical structure. In order to compute a hyperbolic embedding from comparison or similarity information, one has to solve a hyperbolic distance geometry problem. In this paper, we propose a unified framework to compute hyperbolic embeddings from an arbitrary mix of noisy metric and non-metric data. Our algorithms are based on semidefinite programming and the notion of a hyperbolic distance matrix, in many ways parallel to its famous Euclidean counterpart. A central ingredient we put forward is a semidefinite characterization of the hyperbolic Gramian -- a matrix of Lorentzian inner products. This characterization allows us to formulate a semidefinite relaxation to efficiently compute hyperbolic embeddings in two stages: first, we complete and denoise the observed hyperbolic distance matrix; second, we propose a spectral factorization method to estimate the embedded points from the hyperbolic distance matrix. We show through numerical experiments how the flexibility to mix metric and non-metric constraints allows us to efficiently compute embeddings from arbitrary data.