 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFM SO.P: A Progressive Task Mixture Framework with Automatic Evaluation for Cross-Domain SOP Understanding
Feb 10, 2026Standard Operating Procedures (SOPs) are critical for enterprise operations, yet existing language models struggle with SOP understanding and cross-domain generalization. Current methods fail because joint training cannot differentiate between reasoning capabilities that SOP requires: terminology precision, sequential ordering, and constraint reasoning. We propose FM SO.P, solving these challenges through two novelties. First, we introduce progressive task mixtures that build capabilities by stages across three task types with cumulative data: concept disambiguation for terminology precision, action sequence understanding for procedural correctness, and scenario-aware graph reasoning for conditional logic. Second, we propose an automatic multi-agent evaluation system consisting of three agents that adaptively generate rubrics, stratified test sets, and rubric scoring, adapting to domains (e.g., temporal constraints for DMV, regulatory compliance for banking). Evaluated on SOPBench across seven domains (Bank, DMV, Healthcare, Market, University, Library, Hotel), FM SO.P achieves 48.3\% pass rate with our 32B model and 34.3\% with our opensource 7B model, matching Qwen-2.5-72B-Instruct baseline (34.4\%) with 10x fewer parameters.
Zero-Shot Multi-modal Large Language Model v.s. Supervised Deep Learning: A Comparative Study on CT-Based Intracranial Hemorrhage Subtyping
May 14, 2025Introduction: Timely identification of intracranial hemorrhage (ICH) subtypes on non-contrast computed tomography is critical for prognosis prediction and therapeutic decision-making, yet remains challenging due to low contrast and blurring boundaries. This study evaluates the performance of zero-shot multi-modal large language models (MLLMs) compared to traditional deep learning methods in ICH binary classification and subtyping. Methods: We utilized a dataset provided by RSNA, comprising 192 NCCT volumes. The study compares various MLLMs, including GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet V2, with conventional deep learning models, including ResNet50 and Vision Transformer. Carefully crafted prompts were used to guide MLLMs in tasks such as ICH presence, subtype classification, localization, and volume estimation. Results: The results indicate that in the ICH binary classification task, traditional deep learning models outperform MLLMs comprehensively. For subtype classification, MLLMs also exhibit inferior performance compared to traditional deep learning models, with Gemini 2.0 Flash achieving an macro-averaged precision of 0.41 and a macro-averaged F1 score of 0.31. Conclusion: While MLLMs excel in interactive capabilities, their overall accuracy in ICH subtyping is inferior to deep networks. However, MLLMs enhance interpretability through language interactions, indicating potential in medical imaging analysis. Future efforts will focus on model refinement and developing more precise MLLMs to improve performance in three-dimensional medical image processing.
FedGTST: Boosting Global Transferability of Federated Models via Statistics Tuning
Oct 16, 2024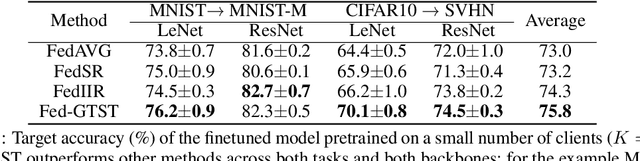
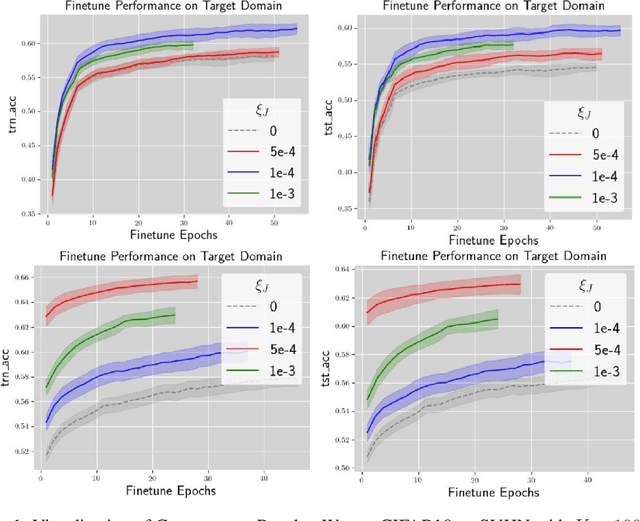
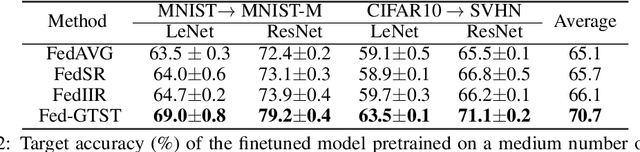
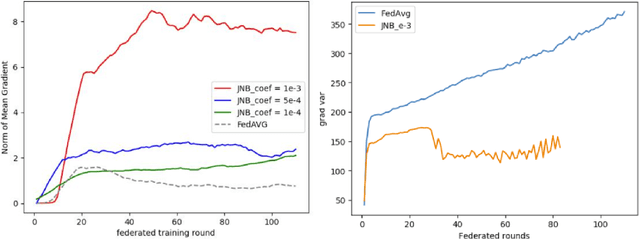
The performance of Transfer Learning (TL) heavily relies on effective pretraining, which demands large datasets and substantial computational resources. As a result, executing TL is often challenging for individual model developers. Federated Learning (FL) addresses these issues by facilitating collaborations among clients, expanding the dataset indirectly, distributing computational costs, and preserving privacy. However, key challenges remain unresolved. First, existing FL methods tend to optimize transferability only within local domains, neglecting the global learning domain. Second, most approaches rely on indirect transferability metrics, which do not accurately reflect the final target loss or true degree of transferability. To address these gaps, we propose two enhancements to FL. First, we introduce a client-server exchange protocol that leverages cross-client Jacobian (gradient) norms to boost transferability. Second, we increase the average Jacobian norm across clients at the server, using this as a local regularizer to reduce cross-client Jacobian variance. Our transferable federated algorithm, termed FedGTST (Federated Global Transferability via Statistics Tuning), demonstrates that increasing the average Jacobian and reducing its variance allows for tighter control of the target loss. This leads to an upper bound on the target loss in terms of the source loss and source-target domain discrepancy. Extensive experiments on datasets such as MNIST to MNIST-M and CIFAR10 to SVHN show that FedGTST outperforms relevant baselines, including FedSR. On the second dataset pair, FedGTST improves accuracy by 9.8% over FedSR and 7.6% over FedIIR when LeNet is used as the backbone.
Joint Universal Adversarial Perturbations with Interpretations
Aug 03, 2024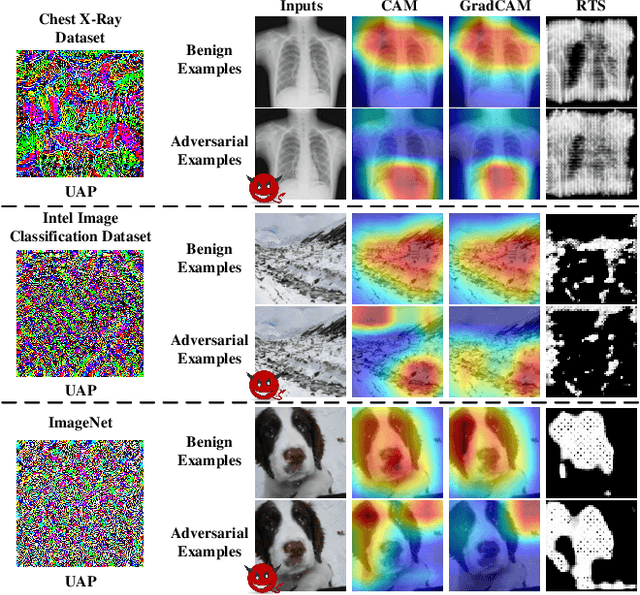
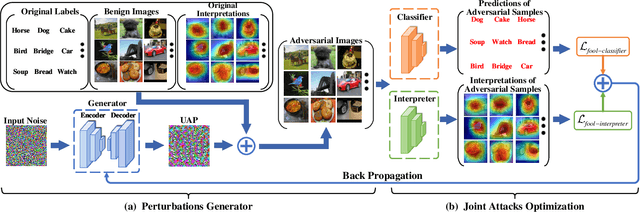
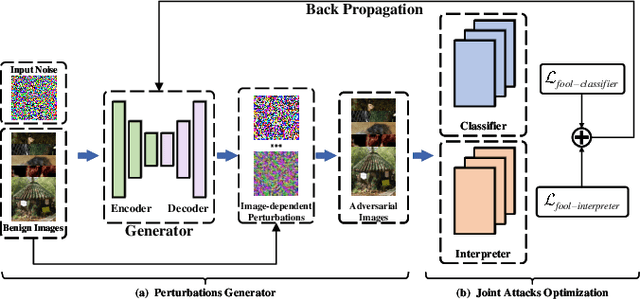
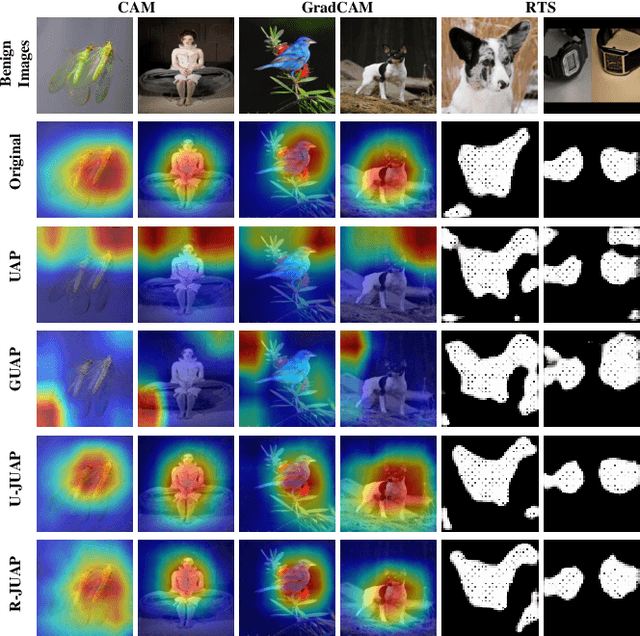
Deep neural networks (DNNs) have significantly boosted the performance of many challenging tasks. Despite the great development, DNNs have also exposed their vulnerability. Recent studies have shown that adversaries can manipulate the predictions of DNNs by adding a universal adversarial perturbation (UAP) to benign samples. On the other hand, increasing efforts have been made to help users understand and explain the inner working of DNNs by highlighting the most informative parts (i.e., attribution maps) of samples with respect to their predictions. Moreover, we first empirically find that such attribution maps between benign and adversarial examples have a significant discrepancy, which has the potential to detect universal adversarial perturbations for defending against adversarial attacks. This finding motivates us to further investigate a new research problem: whether there exist universal adversarial perturbations that are able to jointly attack DNNs classifier and its interpretation with malicious desires. It is challenging to give an explicit answer since these two objectives are seemingly conflicting. In this paper, we propose a novel attacking framework to generate joint universal adversarial perturbations (JUAP), which can fool the DNNs model and misguide the inspection from interpreters simultaneously. Comprehensive experiments on various datasets demonstrate the effectiveness of the proposed method JUAP for joint attacks. To the best of our knowledge, this is the first effort to study UAP for jointly attacking both DNNs and interpretations.
Graph Transductive Defense: a Two-Stage Defense for Graph Membership Inference Attacks
Jun 12, 2024



Graph neural networks (GNNs) have become instrumental in diverse real-world applications, offering powerful graph learning capabilities for tasks such as social networks and medical data analysis. Despite their successes, GNNs are vulnerable to adversarial attacks, including membership inference attacks (MIA), which threaten privacy by identifying whether a record was part of the model's training data. While existing research has explored MIA in GNNs under graph inductive learning settings, the more common and challenging graph transductive learning setting remains understudied in this context. This paper addresses this gap and proposes an effective two-stage defense, Graph Transductive Defense (GTD), tailored to graph transductive learning characteristics. The gist of our approach is a combination of a train-test alternate training schedule and flattening strategy, which successfully reduces the difference between the training and testing loss distributions. Extensive empirical results demonstrate the superior performance of our method (a decrease in attack AUROC by $9.42\%$ and an increase in utility performance by $18.08\%$ on average compared to LBP), highlighting its potential for seamless integration into various classification models with minimal overhead.
An Anchor-Point Based Image-Model for Room Impulse Response Simulation with Directional Source Radiation and Sensor Directivity Patterns
Aug 21, 2023The image model method has been widely used to simulate room impulse responses and the endeavor to adapt this method to different applications has also piqued great interest over the last few decades. This paper attempts to extend the image model method and develops an anchor-point-image-model (APIM) approach as a solution for simulating impulse responses by including both the source radiation and sensor directivity patterns. To determine the orientations of all the virtual sources, anchor points are introduced to real sources, which subsequently lead to the determination of the orientations of the virtual sources. An algorithm is developed to generate room impulse responses with APIM by taking into account the directional pattern functions, factional time delays, as well as the computational complexity. The developed model and algorithms can be used in various acoustic problems to simulate room acoustics and improve and evaluate processing algorithms.
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Aug 14, 2023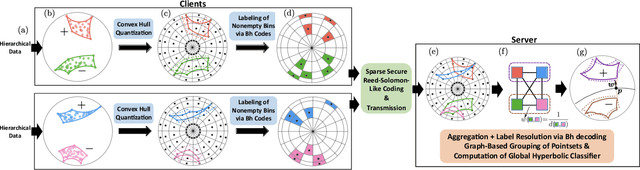
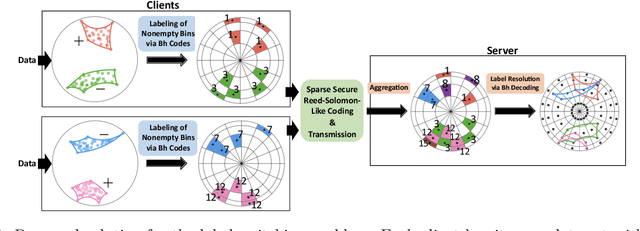

Hierarchical and tree-like data sets arise in many applications, including language processing, graph data mining, phylogeny and genomics. It is known that tree-like data cannot be embedded into Euclidean spaces of finite dimension with small distortion. This problem can be mitigated through the use of hyperbolic spaces. When such data also has to be processed in a distributed and privatized setting, it becomes necessary to work with new federated learning methods tailored to hyperbolic spaces. As an initial step towards the development of the field of federated learning in hyperbolic spaces, we propose the first known approach to federated classification in hyperbolic spaces. Our contributions are as follows. First, we develop distributed versions of convex SVM classifiers for Poincar\'e discs. In this setting, the information conveyed from clients to the global classifier are convex hulls of clusters present in individual client data. Second, to avoid label switching issues, we introduce a number-theoretic approach for label recovery based on the so-called integer $B_h$ sequences. Third, we compute the complexity of the convex hulls in hyperbolic spaces to assess the extent of data leakage; at the same time, in order to limit the communication cost for the hulls, we propose a new quantization method for the Poincar\'e disc coupled with Reed-Solomon-like encoding. Fourth, at server level, we introduce a new approach for aggregating convex hulls of the clients based on balanced graph partitioning. We test our method on a collection of diverse data sets, including hierarchical single-cell RNA-seq data from different patients distributed across different repositories that have stringent privacy constraints. The classification accuracy of our method is up to $\sim 11\%$ better than its Euclidean counterpart, demonstrating the importance of privacy-preserving learning in hyperbolic spaces.
Differentially Private Decoupled Graph Convolutions for Multigranular Topology Protection
Jul 12, 2023



Graph learning methods, such as Graph Neural Networks (GNNs) based on graph convolutions, are highly successful in solving real-world learning problems involving graph-structured data. However, graph learning methods expose sensitive user information and interactions not only through their model parameters but also through their model predictions. Consequently, standard Differential Privacy (DP) techniques that merely offer model weight privacy are inadequate. This is especially the case for node predictions that leverage neighboring node attributes directly via graph convolutions that create additional risks of privacy leakage. To address this problem, we introduce Graph Differential Privacy (GDP), a new formal DP framework tailored to graph learning settings that ensures both provably private model parameters and predictions. Furthermore, since there may be different privacy requirements for the node attributes and graph structure, we introduce a novel notion of relaxed node-level data adjacency. This relaxation can be used for establishing guarantees for different degrees of graph topology privacy while maintaining node attribute privacy. Importantly, this relaxation reveals a useful trade-off between utility and topology privacy for graph learning methods. In addition, our analysis of GDP reveals that existing DP-GNNs fail to exploit this trade-off due to the complex interplay between graph topology and attribute data in standard graph convolution designs. To mitigate this problem, we introduce the Differentially Private Decoupled Graph Convolution (DPDGC) model, which benefits from decoupled graph convolution while providing GDP guarantees. Extensive experiments on seven node classification benchmarking datasets demonstrate the superior privacy-utility trade-off of DPDGC over existing DP-GNNs based on standard graph convolution design.
Unlearning Nonlinear Graph Classifiers in the Limited Training Data Regime
Nov 06, 2022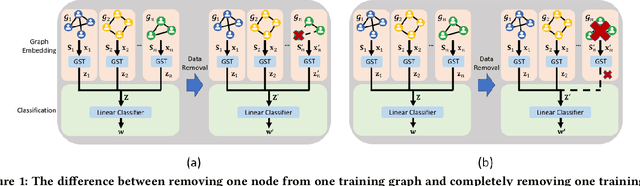
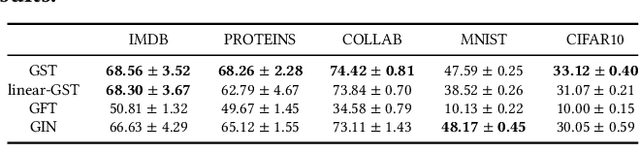
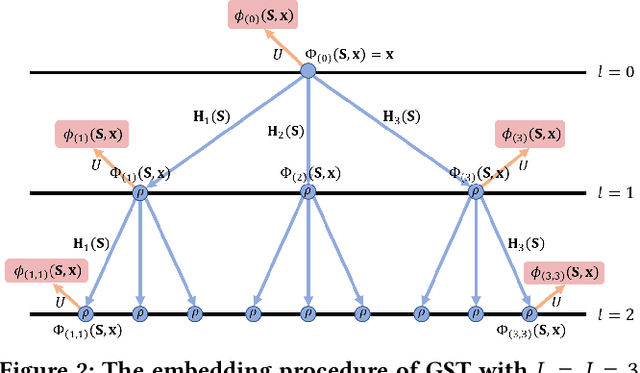
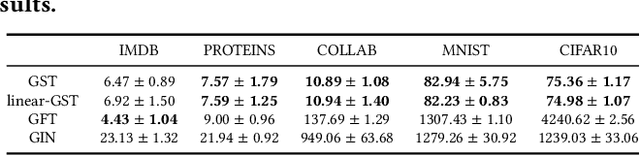
As the demand for user privacy grows, controlled data removal (machine unlearning) is becoming an important feature of machine learning models for data-sensitive Web applications such as social networks and recommender systems. Nevertheless, at this point it is still largely unknown how to perform efficient machine unlearning of graph neural networks (GNNs); this is especially the case when the number of training samples is small, in which case unlearning can seriously compromise the performance of the model. To address this issue, we initiate the study of unlearning the Graph Scattering Transform (GST), a mathematical framework that is efficient, provably stable under feature or graph topology perturbations, and offers graph classification performance comparable to that of GNNs. Our main contribution is the first known nonlinear approximate graph unlearning method based on GSTs. Our second contribution is a theoretical analysis of the computational complexity of the proposed unlearning mechanism, which is hard to replicate for deep neural networks. Our third contribution are extensive simulation results which show that, compared to complete retraining of GNNs after each removal request, the new GST-based approach offers, on average, a $10.38$x speed-up and leads to a $2.6$% increase in test accuracy during unlearning of $90$ out of $100$ training graphs from the IMDB dataset ($10$% training ratio).
Machine Unlearning of Federated Clusters
Oct 28, 2022
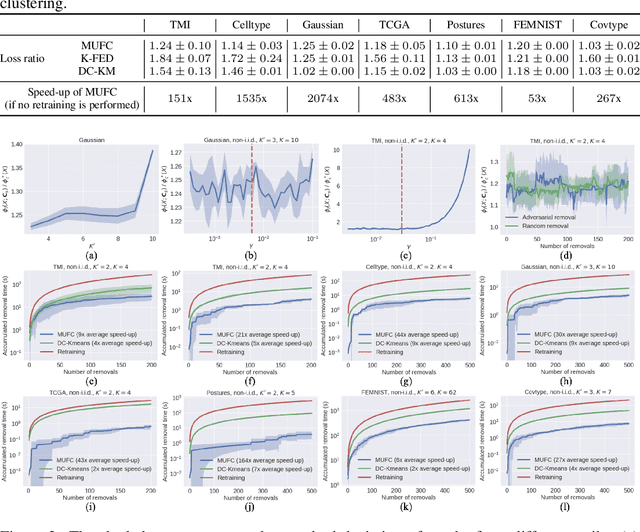
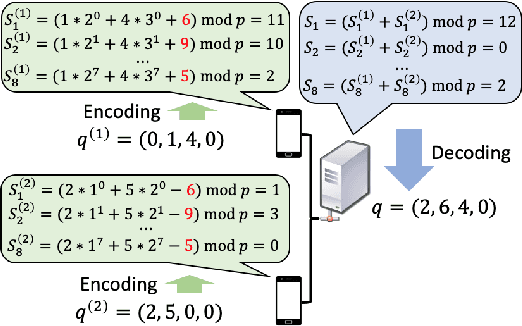

Federated clustering is an unsupervised learning problem that arises in a number of practical applications, including personalized recommender and healthcare systems. With the adoption of recent laws ensuring the "right to be forgotten", the problem of machine unlearning for federated clustering methods has become of significant importance. This work proposes the first known unlearning mechanism for federated clustering with privacy criteria that support simple, provable, and efficient data removal at the client and server level. The gist of our approach is to combine special initialization procedures with quantization methods that allow for secure aggregation of estimated local cluster counts at the server unit. As part of our platform, we introduce secure compressed multiset aggregation (SCMA), which is of independent interest for secure sparse model aggregation. In order to simultaneously facilitate low communication complexity and secret sharing protocols, we integrate Reed-Solomon encoding with special evaluation points into the new SCMA pipeline and derive bounds on the time and communication complexity of different components of the scheme. Compared to completely retraining K-means++ locally and globally for each removal request, we obtain an average speed-up of roughly 84x across seven datasets, two of which contain biological and medical information that is subject to frequent unlearning requests.