 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Nonlinear Graph Classifiers in the Limited Training Data Regime
Paper and Code
Nov 06, 2022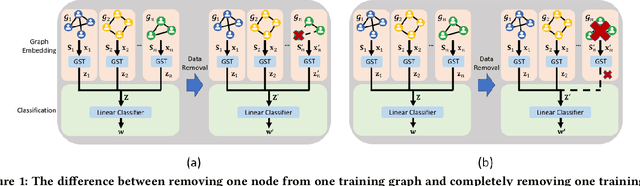
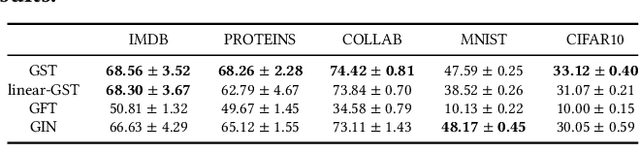
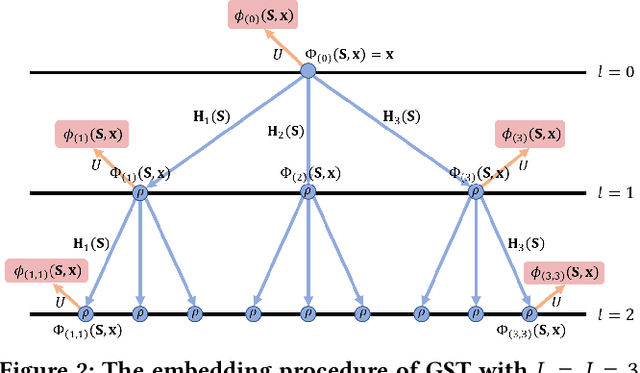
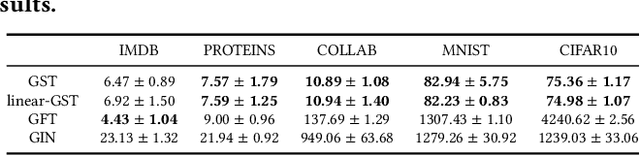
As the demand for user privacy grows, controlled data removal (machine unlearning) is becoming an important feature of machine learning models for data-sensitive Web applications such as social networks and recommender systems. Nevertheless, at this point it is still largely unknown how to perform efficient machine unlearning of graph neural networks (GNNs); this is especially the case when the number of training samples is small, in which case unlearning can seriously compromise the performance of the model. To address this issue, we initiate the study of unlearning the Graph Scattering Transform (GST), a mathematical framework that is efficient, provably stable under feature or graph topology perturbations, and offers graph classification performance comparable to that of GNNs. Our main contribution is the first known nonlinear approximate graph unlearning method based on GSTs. Our second contribution is a theoretical analysis of the computational complexity of the proposed unlearning mechanism, which is hard to replicate for deep neural networks. Our third contribution are extensive simulation results which show that, compared to complete retraining of GNNs after each removal request, the new GST-based approach offers, on average, a $10.38$x speed-up and leads to a $2.6$% increase in test accuracy during unlearning of $90$ out of $100$ training graphs from the IMDB dataset ($10$% training ratio).