 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheatAgent: Attacking LLM-Empowered Recommender Systems via LLM Agent
Apr 13, 2025Recently, Large Language Model (LLM)-empowered recommender systems (RecSys) have brought significant advances in personalized user experience and have attracted considerable attention. Despite the impressive progress, the research question regarding the safety vulnerability of LLM-empowered RecSys still remains largely under-investigated. Given the security and privacy concerns, it is more practical to focus on attacking the black-box RecSys, where attackers can only observe the system's inputs and outputs. However, traditional attack approaches employing reinforcement learning (RL) agents are not effective for attacking LLM-empowered RecSys due to the limited capabilities in processing complex textual inputs, planning, and reasoning. On the other hand, LLMs provide unprecedented opportunities to serve as attack agents to attack RecSys because of their impressive capability in simulating human-like decision-making processes. Therefore, in this paper, we propose a novel attack framework called CheatAgent by harnessing the human-like capabilities of LLMs, where an LLM-based agent is developed to attack LLM-Empowered RecSys. Specifically, our method first identifies the insertion position for maximum impact with minimal input modification. After that, the LLM agent is designed to generate adversarial perturbations to insert at target positions. To further improve the quality of generated perturbations, we utilize the prompt tuning technique to improve attacking strategies via feedback from the victim RecSys iteratively. Extensive experiments across three real-world datasets demonstrate the effectiveness of our proposed attacking method.
Towards Next-Generation Recommender Systems: A Benchmark for Personalized Recommendation Assistant with LLMs
Mar 12, 2025Recommender systems (RecSys) are widely used across various modern digital platforms and have garnered significant attention. Traditional recommender systems usually focus only on fixed and simple recommendation scenarios, making it difficult to generalize to new and unseen recommendation tasks in an interactive paradigm. Recently, the advancement of large language models (LLMs) has revolutionized the foundational architecture of RecSys, driving their evolution into more intelligent and interactive personalized recommendation assistants. However, most existing studies rely on fixed task-specific prompt templates to generate recommendations and evaluate the performance of personalized assistants, which limits the comprehensive assessments of their capabilities. This is because commonly used datasets lack high-quality textual user queries that reflect real-world recommendation scenarios, making them unsuitable for evaluating LLM-based personalized recommendation assistants. To address this gap, we introduce RecBench+, a new dataset benchmark designed to access LLMs' ability to handle intricate user recommendation needs in the era of LLMs. RecBench+ encompasses a diverse set of queries that span both hard conditions and soft preferences, with varying difficulty levels. We evaluated commonly used LLMs on RecBench+ and uncovered below findings: 1) LLMs demonstrate preliminary abilities to act as recommendation assistants, 2) LLMs are better at handling queries with explicitly stated conditions, while facing challenges with queries that require reasoning or contain misleading information. Our dataset has been released at https://github.com/jiani-huang/RecBench.git.
Joint Universal Adversarial Perturbations with Interpretations
Aug 03, 2024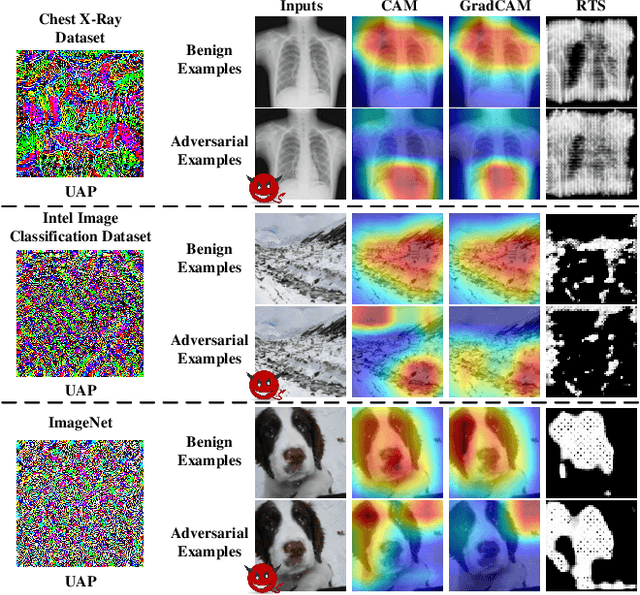
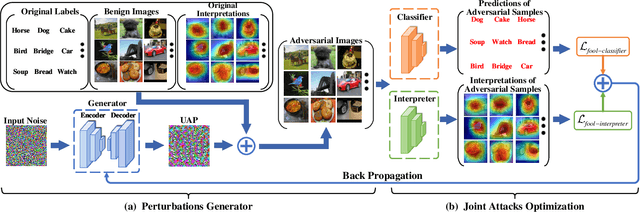
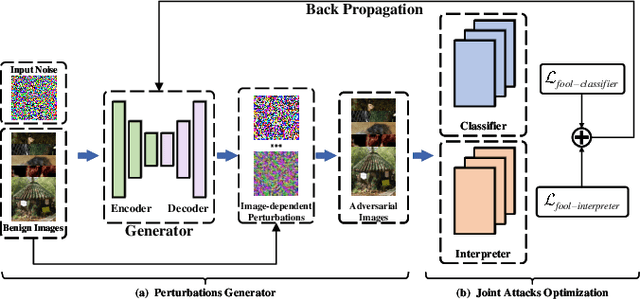
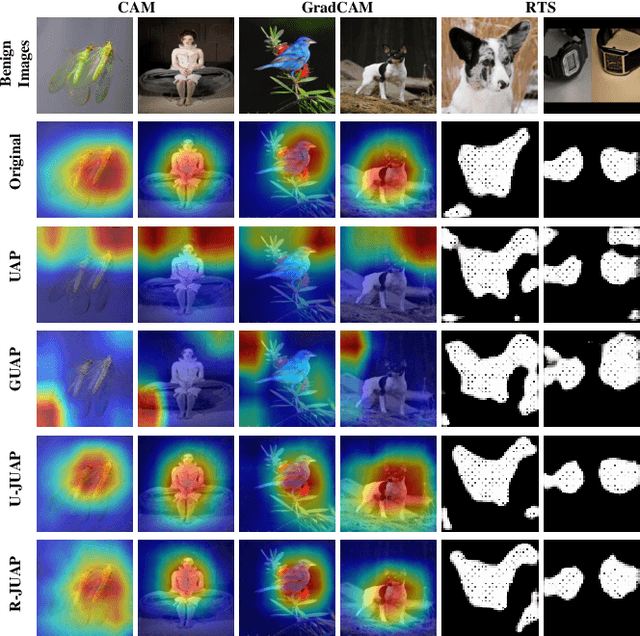
Deep neural networks (DNNs) have significantly boosted the performance of many challenging tasks. Despite the great development, DNNs have also exposed their vulnerability. Recent studies have shown that adversaries can manipulate the predictions of DNNs by adding a universal adversarial perturbation (UAP) to benign samples. On the other hand, increasing efforts have been made to help users understand and explain the inner working of DNNs by highlighting the most informative parts (i.e., attribution maps) of samples with respect to their predictions. Moreover, we first empirically find that such attribution maps between benign and adversarial examples have a significant discrepancy, which has the potential to detect universal adversarial perturbations for defending against adversarial attacks. This finding motivates us to further investigate a new research problem: whether there exist universal adversarial perturbations that are able to jointly attack DNNs classifier and its interpretation with malicious desires. It is challenging to give an explicit answer since these two objectives are seemingly conflicting. In this paper, we propose a novel attacking framework to generate joint universal adversarial perturbations (JUAP), which can fool the DNNs model and misguide the inspection from interpreters simultaneously. Comprehensive experiments on various datasets demonstrate the effectiveness of the proposed method JUAP for joint attacks. To the best of our knowledge, this is the first effort to study UAP for jointly attacking both DNNs and interpretations.