 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemDiff: Generating Natural Unrestricted Adversarial Examples via Semantic Attributes Optimization in Diffusion Models
Apr 16, 2025Unrestricted adversarial examples (UAEs), allow the attacker to create non-constrained adversarial examples without given clean samples, posing a severe threat to the safety of deep learning models. Recent works utilize diffusion models to generate UAEs. However, these UAEs often lack naturalness and imperceptibility due to simply optimizing in intermediate latent noises. In light of this, we propose SemDiff, a novel unrestricted adversarial attack that explores the semantic latent space of diffusion models for meaningful attributes, and devises a multi-attributes optimization approach to ensure attack success while maintaining the naturalness and imperceptibility of generated UAEs. We perform extensive experiments on four tasks on three high-resolution datasets, including CelebA-HQ, AFHQ and ImageNet. The results demonstrate that SemDiff outperforms state-of-the-art methods in terms of attack success rate and imperceptibility. The generated UAEs are natural and exhibit semantically meaningful changes, in accord with the attributes' weights. In addition, SemDiff is found capable of evading different defenses, which further validates its effectiveness and threatening.
Joint Universal Adversarial Perturbations with Interpretations
Aug 03, 2024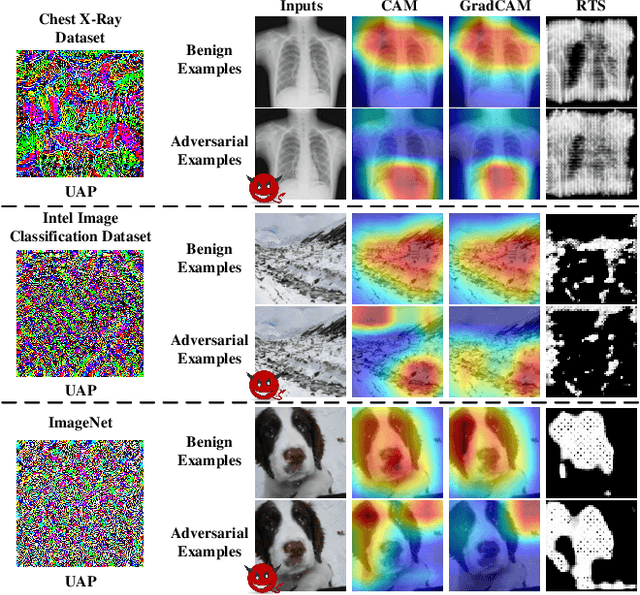
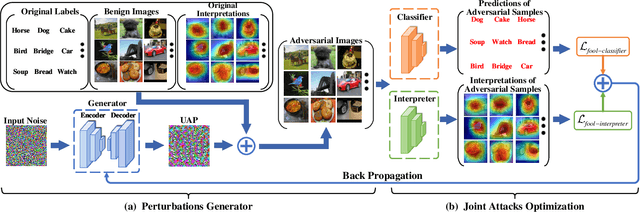
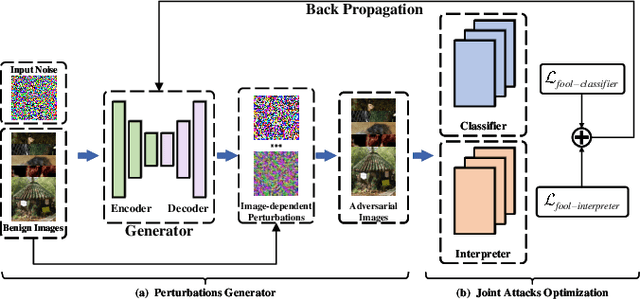
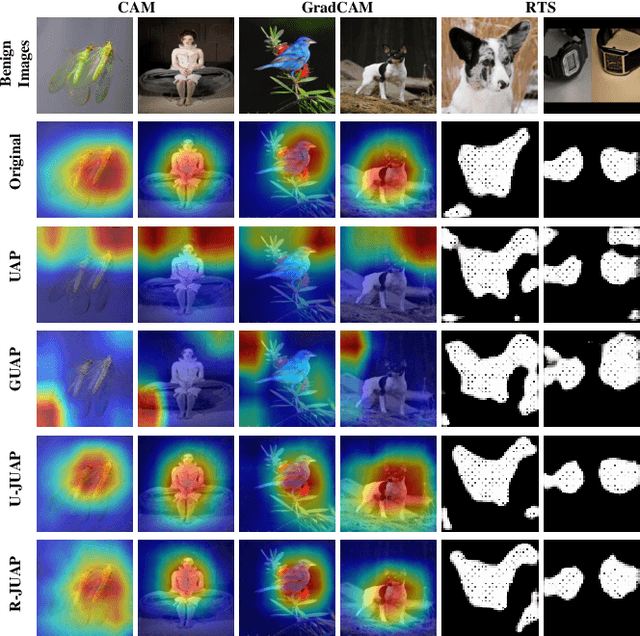
Deep neural networks (DNNs) have significantly boosted the performance of many challenging tasks. Despite the great development, DNNs have also exposed their vulnerability. Recent studies have shown that adversaries can manipulate the predictions of DNNs by adding a universal adversarial perturbation (UAP) to benign samples. On the other hand, increasing efforts have been made to help users understand and explain the inner working of DNNs by highlighting the most informative parts (i.e., attribution maps) of samples with respect to their predictions. Moreover, we first empirically find that such attribution maps between benign and adversarial examples have a significant discrepancy, which has the potential to detect universal adversarial perturbations for defending against adversarial attacks. This finding motivates us to further investigate a new research problem: whether there exist universal adversarial perturbations that are able to jointly attack DNNs classifier and its interpretation with malicious desires. It is challenging to give an explicit answer since these two objectives are seemingly conflicting. In this paper, we propose a novel attacking framework to generate joint universal adversarial perturbations (JUAP), which can fool the DNNs model and misguide the inspection from interpreters simultaneously. Comprehensive experiments on various datasets demonstrate the effectiveness of the proposed method JUAP for joint attacks. To the best of our knowledge, this is the first effort to study UAP for jointly attacking both DNNs and interpretations.
Perturbation-Based Two-Stage Multi-Domain Active Learning
Jun 19, 2023In multi-domain learning (MDL) scenarios, high labeling effort is required due to the complexity of collecting data from various domains. Active Learning (AL) presents an encouraging solution to this issue by annotating a smaller number of highly informative instances, thereby reducing the labeling effort. Previous research has relied on conventional AL strategies for MDL scenarios, which underutilize the domain-shared information of each instance during the selection procedure. To mitigate this issue, we propose a novel perturbation-based two-stage multi-domain active learning (P2S-MDAL) method incorporated into the well-regarded ASP-MTL model. Specifically, P2S-MDAL involves allocating budgets for domains and establishing regions for diversity selection, which are further used to select the most cross-domain influential samples in each region. A perturbation metric has been introduced to evaluate the robustness of the shared feature extractor of the model, facilitating the identification of potentially cross-domain influential samples. Experiments are conducted on three real-world datasets, encompassing both texts and images. The superior performance over conventional AL strategies shows the effectiveness of the proposed strategy. Additionally, an ablation study has been carried out to demonstrate the validity of each component. Finally, we outline several intriguing potential directions for future MDAL research, thus catalyzing the field's advancement.
Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022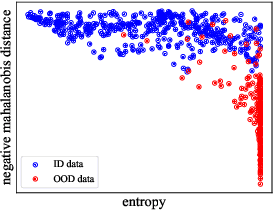
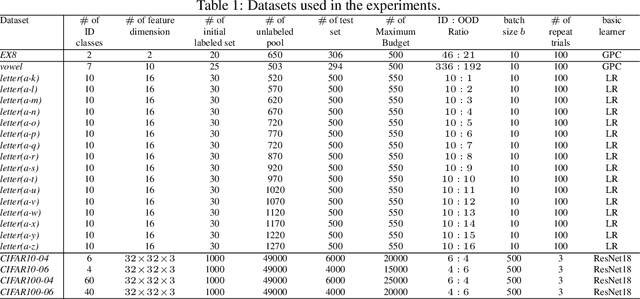
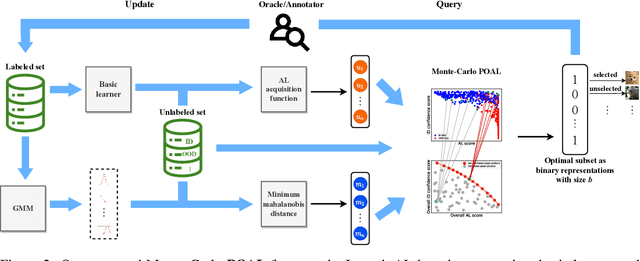
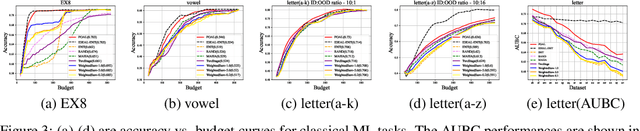
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
Saliency Attack: Towards Imperceptible Black-box Adversarial Attack
Jun 04, 2022
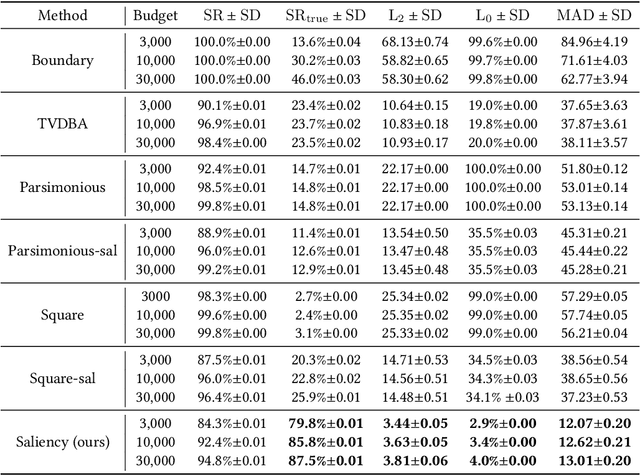

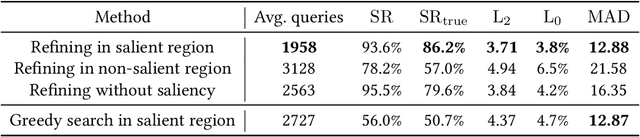
Deep neural networks are vulnerable to adversarial examples, even in the black-box setting where the attacker is only accessible to the model output. Recent studies have devised effective black-box attacks with high query efficiency. However, such performance is often accompanied by compromises in attack imperceptibility, hindering the practical use of these approaches. In this paper, we propose to restrict the perturbations to a small salient region to generate adversarial examples that can hardly be perceived. This approach is readily compatible with many existing black-box attacks and can significantly improve their imperceptibility with little degradation in attack success rate. Further, we propose the Saliency Attack, a new black-box attack aiming to refine the perturbations in the salient region to achieve even better imperceptibility. Extensive experiments show that compared to the state-of-the-art black-box attacks, our approach achieves much better imperceptibility scores, including most apparent distortion (MAD), $L_0$ and $L_2$ distances, and also obtains significantly higher success rates judged by a human-like threshold on MAD. Importantly, the perturbations generated by our approach are interpretable to some extent. Finally, it is also demonstrated to be robust to different detection-based defenses.
Building Context-aware Clause Representations for Situation Entity Type Classification
Sep 20, 2018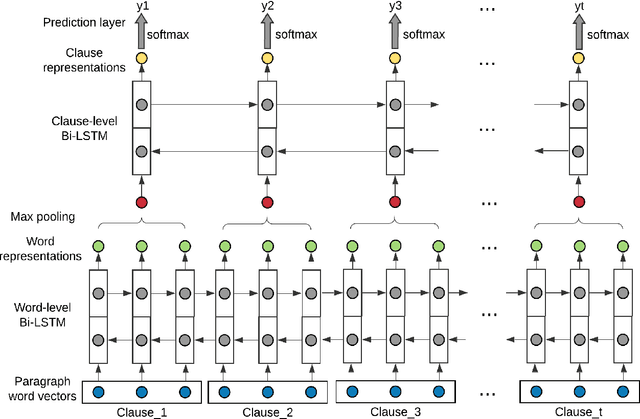
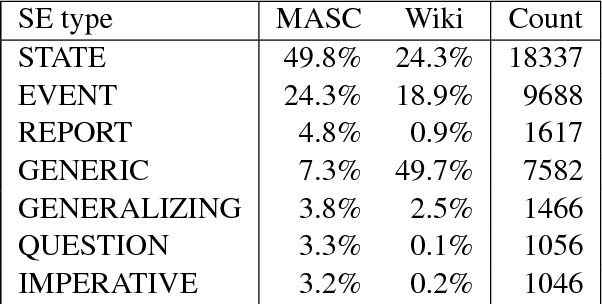
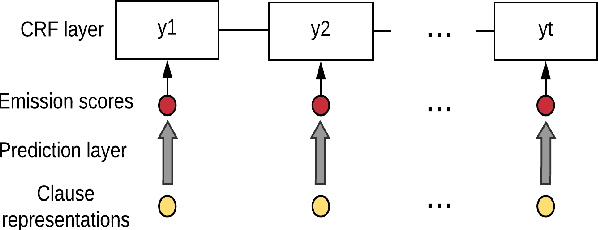
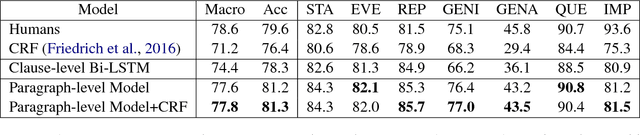
Capabilities to categorize a clause based on the type of situation entity (e.g., events, states and generic statements) the clause introduces to the discourse can benefit many NLP applications. Observing that the situation entity type of a clause depends on discourse functions the clause plays in a paragraph and the interpretation of discourse functions depends heavily on paragraph-wide contexts, we propose to build context-aware clause representations for predicting situation entity types of clauses. Specifically, we propose a hierarchical recurrent neural network model to read a whole paragraph at a time and jointly learn representations for all the clauses in the paragraph by extensively modeling context influences and inter-dependencies of clauses. Experimental results show that our model achieves the state-of-the-art performance for clause-level situation entity classification on the genre-rich MASC+Wiki corpus, which approaches human-level performance.
Improving Implicit Discourse Relation Classification by Modeling Inter-dependencies of Discourse Units in a Paragraph
Apr 16, 2018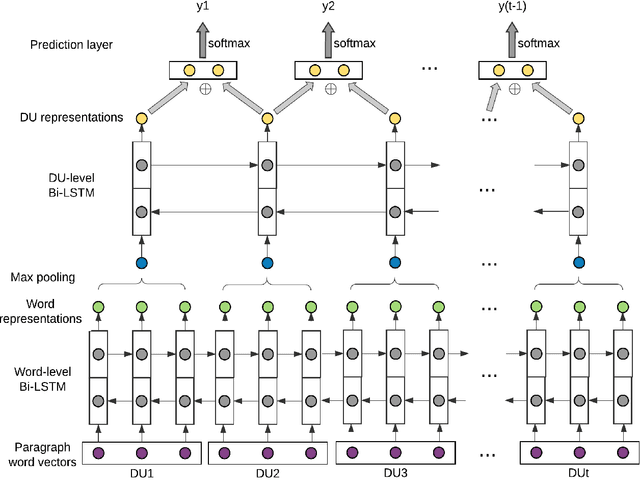

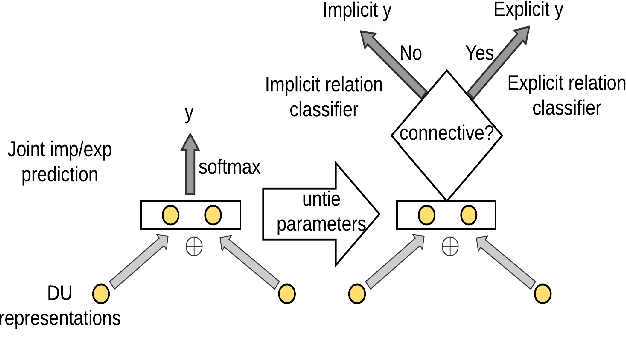

We argue that semantic meanings of a sentence or clause can not be interpreted independently from the rest of a paragraph, or independently from all discourse relations and the overall paragraph-level discourse structure. With the goal of improving implicit discourse relation classification, we introduce a paragraph-level neural networks that model inter-dependencies between discourse units as well as discourse relation continuity and patterns, and predict a sequence of discourse relations in a paragraph. Experimental results show that our model outperforms the previous state-of-the-art systems on the benchmark corpus of PDTB.
Using Context Events in Neural Network Models for Event Temporal Status Identification
Oct 12, 2017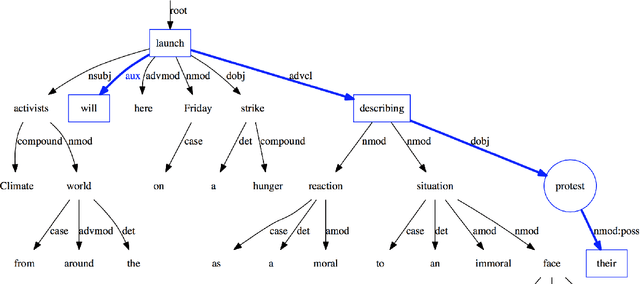
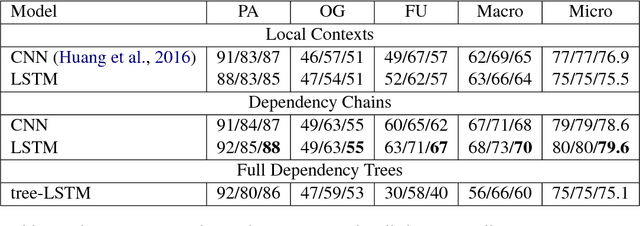
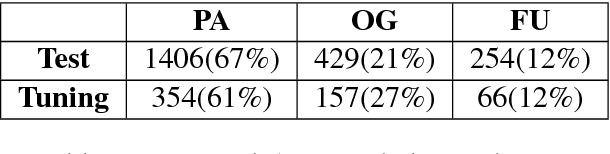
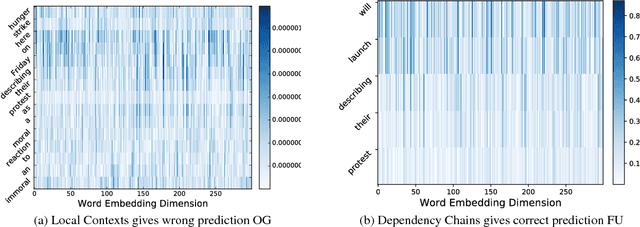
Focusing on the task of identifying event temporal status, we find that events directly or indirectly governing the target event in a dependency tree are most important contexts. Therefore, we extract dependency chains containing context events and use them as input in neural network models, which consistently outperform previous models using local context words as input. Visualization verifies that the dependency chain representation can effectively capture the context events which are closely related to the target event and play key roles in predicting event temporal status.
Online Deception Detection Refueled by Real World Data Collection
Jul 28, 2017

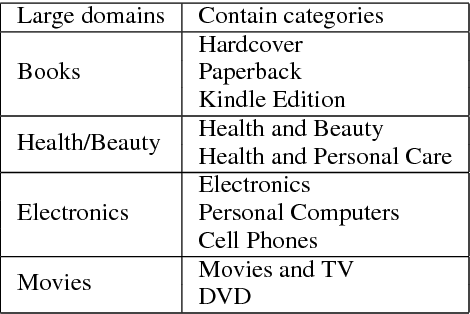
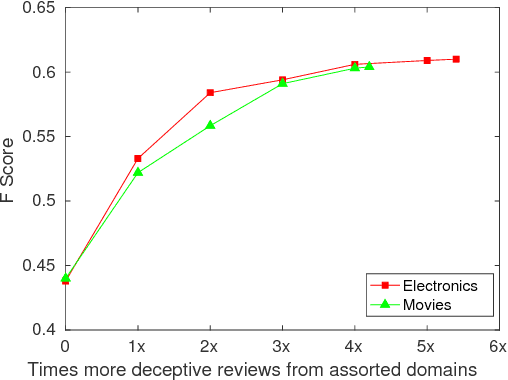
The lack of large realistic datasets presents a bottleneck in online deception detection studies. In this paper, we apply a data collection method based on social network analysis to quickly identify high-quality deceptive and truthful online reviews from Amazon. The dataset contains more than 10,000 deceptive reviews and is diverse in product domains and reviewers. Using this dataset, we explore effective general features for online deception detection that perform well across domains. We demonstrate that with generalized features - advertising speak and writing complexity scores - deception detection performance can be further improved by adding additional deceptive reviews from assorted domains in training. Finally, reviewer level evaluation gives an interesting insight into different deceptive reviewers' writing styles.