 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAL: Automated Active Learning with Differentiable Query Strategy Search
Oct 17, 2024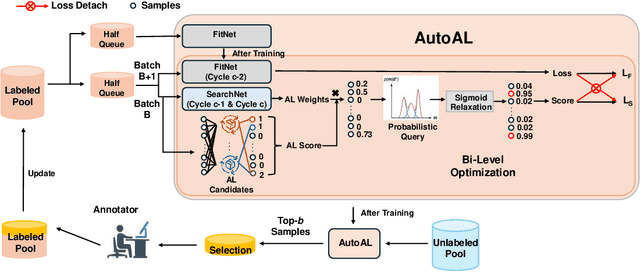
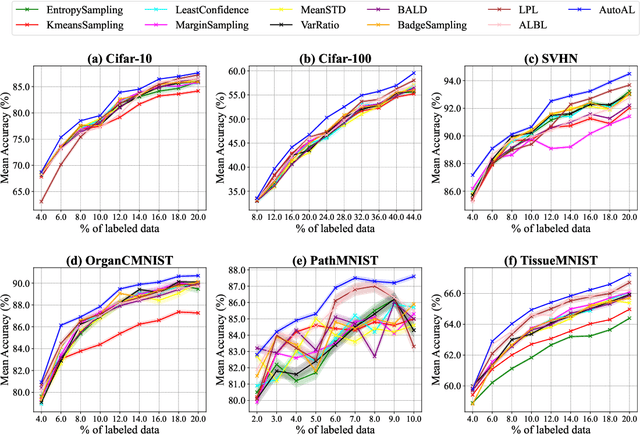
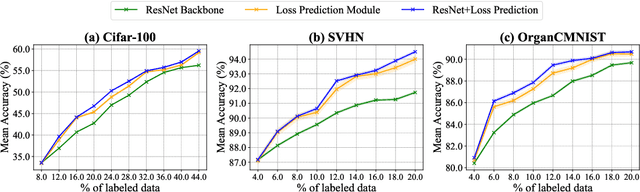
As deep learning continues to evolve, the need for data efficiency becomes increasingly important. Considering labeling large datasets is both time-consuming and expensive, active learning (AL) provides a promising solution to this challenge by iteratively selecting the most informative subsets of examples to train deep neural networks, thereby reducing the labeling cost. However, the effectiveness of different AL algorithms can vary significantly across data scenarios, and determining which AL algorithm best fits a given task remains a challenging problem. This work presents the first differentiable AL strategy search method, named AutoAL, which is designed on top of existing AL sampling strategies. AutoAL consists of two neural nets, named SearchNet and FitNet, which are optimized concurrently under a differentiable bi-level optimization framework. For any given task, SearchNet and FitNet are iteratively co-optimized using the labeled data, learning how well a set of candidate AL algorithms perform on that task. With the optimal AL strategies identified, SearchNet selects a small subset from the unlabeled pool for querying their annotations, enabling efficient training of the task model. Experimental results demonstrate that AutoAL consistently achieves superior accuracy compared to all candidate AL algorithms and other selective AL approaches, showcasing its potential for adapting and integrating multiple existing AL methods across diverse tasks and domains. Code will be available at: https://github.com/haizailache999/AutoAL.
CryoMAE: Few-Shot Cryo-EM Particle Picking with Masked Autoencoders
Apr 15, 2024
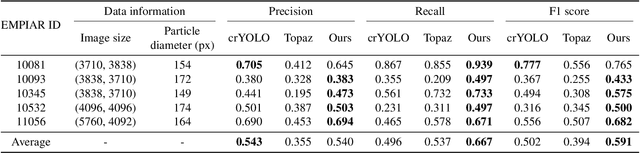
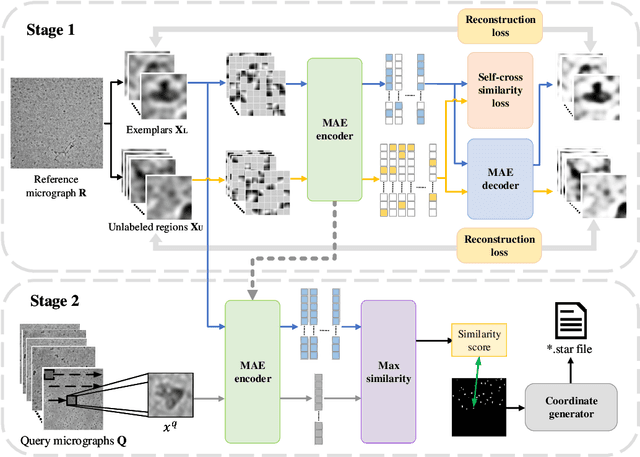
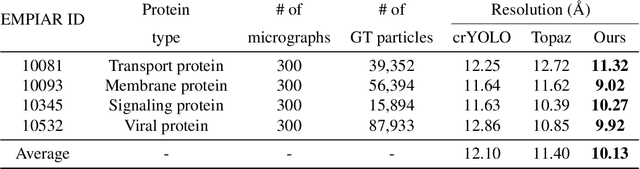
Cryo-electron microscopy (cryo-EM) emerges as a pivotal technology for determining the architecture of cells, viruses, and protein assemblies at near-atomic resolution. Traditional particle picking, a key step in cryo-EM, struggles with manual effort and automated methods' sensitivity to low signal-to-noise ratio (SNR) and varied particle orientations. Furthermore, existing neural network (NN)-based approaches often require extensive labeled datasets, limiting their practicality. To overcome these obstacles, we introduce cryoMAE, a novel approach based on few-shot learning that harnesses the capabilities of Masked Autoencoders (MAE) to enable efficient selection of single particles in cryo-EM images. Contrary to conventional NN-based techniques, cryoMAE requires only a minimal set of positive particle images for training yet demonstrates high performance in particle detection. Furthermore, the implementation of a self-cross similarity loss ensures distinct features for particle and background regions, thereby enhancing the discrimination capability of cryoMAE. Experiments on large-scale cryo-EM datasets show that cryoMAE outperforms existing state-of-the-art (SOTA) methods, improving 3D reconstruction resolution by up to 22.4%.
Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022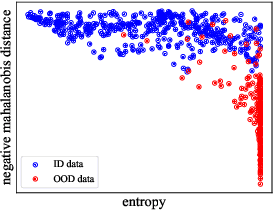
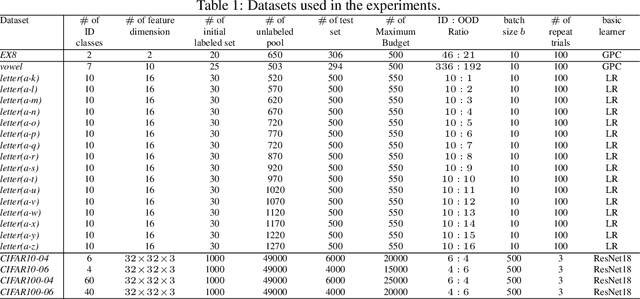
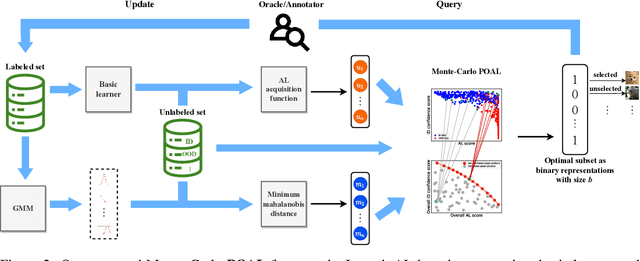
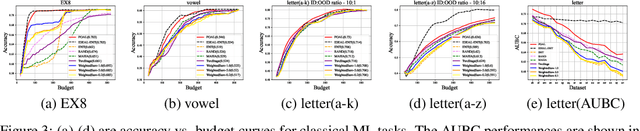
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
Deep Active Learning with Noise Stability
May 26, 2022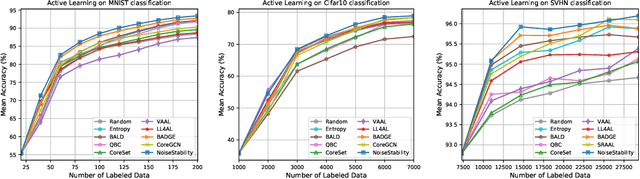
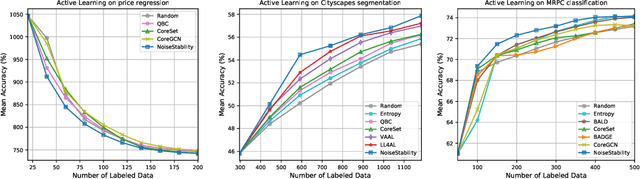
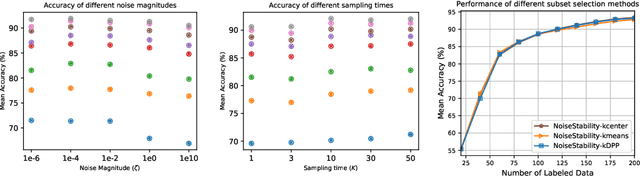
Uncertainty estimation for unlabeled data is crucial to active learning. With a deep neural network employed as the backbone model, the data selection process is highly challenging due to the potential over-confidence of the model inference. Existing methods resort to special learning fashions (e.g. adversarial) or auxiliary models to address this challenge. This tends to result in complex and inefficient pipelines, which would render the methods impractical. In this work, we propose a novel algorithm that leverages noise stability to estimate data uncertainty in a Single-Training Multi-Inference fashion. The key idea is to measure the output derivation from the original observation when the model parameters are randomly perturbed by noise. We provide theoretical analyses by leveraging the small Gaussian noise theory and demonstrate that our method favors a subset with large and diverse gradients. Despite its simplicity, our method outperforms the state-of-the-art active learning baselines in various tasks, including computer vision, natural language processing, and structural data analysis.
A Comparative Survey of Deep Active Learning
Mar 25, 2022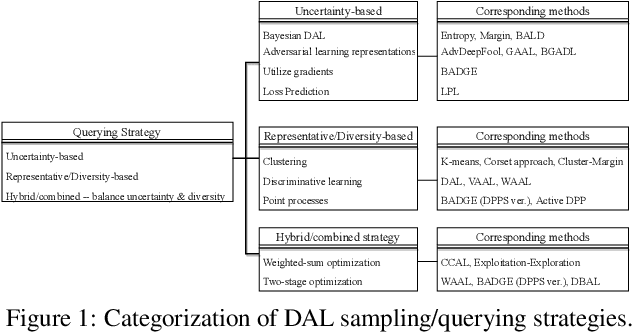


Active Learning (AL) is a set of techniques for reducing labeling cost by sequentially selecting data samples from a large unlabeled data pool for labeling. Meanwhile, Deep Learning (DL) is data-hungry, and the performance of DL models scales monotonically with more training data. Therefore, in recent years, Deep Active Learning (DAL) has risen as feasible solutions for maximizing model performance while minimizing the expensive labeling cost. Abundant methods have sprung up and literature reviews of DAL have been presented before. However, the performance comparison of different branches of DAL methods under various tasks is still insufficient and our work fills this gap. In this paper, we survey and categorize DAL-related work and construct comparative experiments across frequently used datasets and DAL algorithms. Additionally, we explore some factors (e.g., batch size, number of epochs in the training process) that influence the efficacy of DAL, which provides better references for researchers to design their own DAL experiments or carry out DAL-related applications. We construct a DAL toolkit, DeepAL+, by re-implementing many highly-cited DAL-related methods, and it will be released to the public.
Multiple-criteria Based Active Learning with Fixed-size Determinantal Point Processes
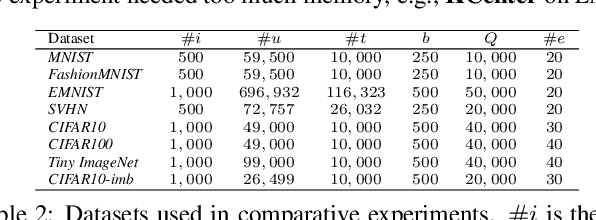
Jul 04, 2021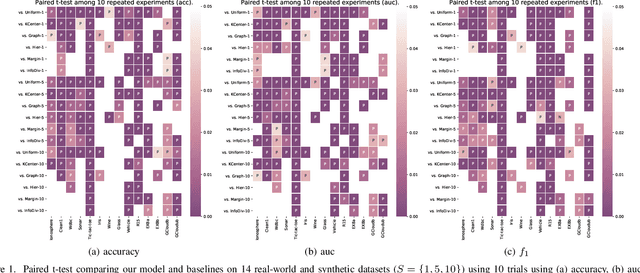
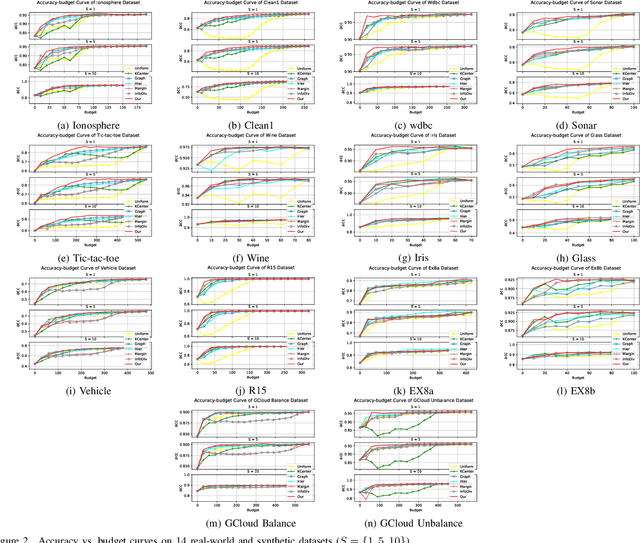

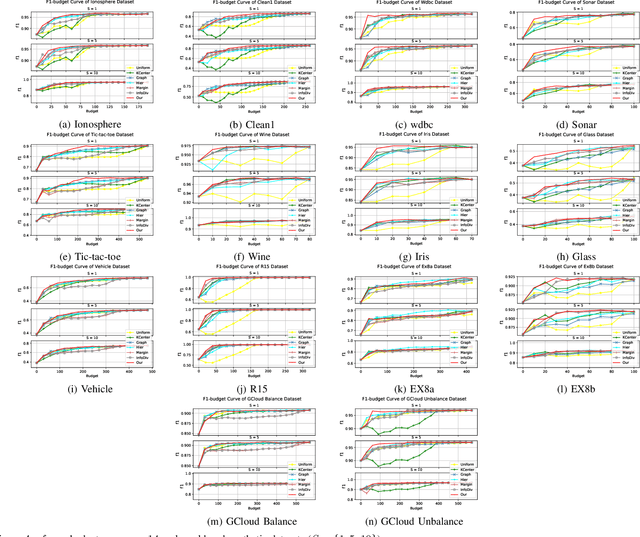
Active learning aims to achieve greater accuracy with less training data by selecting the most useful data samples from which it learns. Single-criterion based methods (i.e., informativeness and representativeness based methods) are simple and efficient; however, they lack adaptability to different real-world scenarios. In this paper, we introduce a multiple-criteria based active learning algorithm, which incorporates three complementary criteria, i.e., informativeness, representativeness and diversity, to make appropriate selections in the active learning rounds under different data types. We consider the selection process as a Determinantal Point Process, which good balance among these criteria. We refine the query selection strategy by both selecting the hardest unlabeled data sample and biasing towards the classifiers that are more suitable for the current data distribution. In addition, we also consider the dependencies and relationships between these data points in data selection by means of centroidbased clustering approaches. Through evaluations on synthetic and real-world datasets, we show that our method performs significantly better and is more stable than other multiple-criteria based AL algorithms.
ALdataset: a benchmark for pool-based active learning
Oct 16, 2020
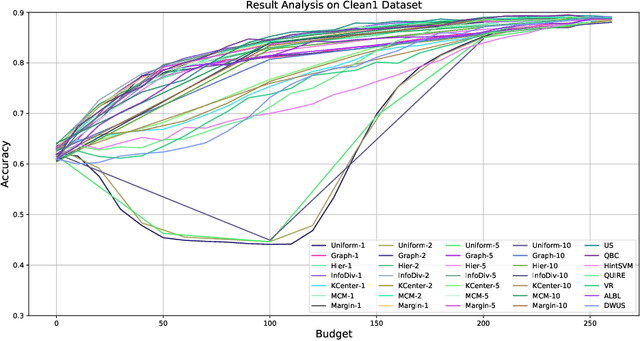

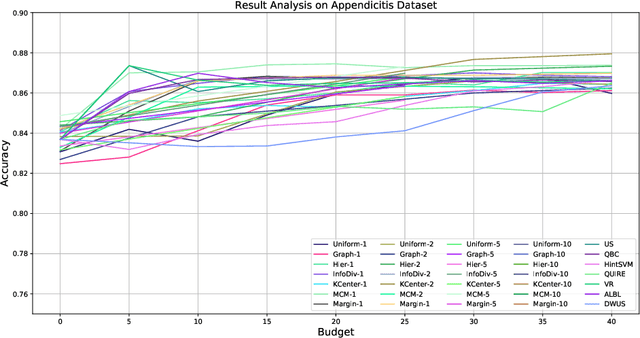
Active learning (AL) is a subfield of machine learning (ML) in which a learning algorithm could achieve good accuracy with less training samples by interactively querying a user/oracle to label new data points. Pool-based AL is well-motivated in many ML tasks, where unlabeled data is abundant, but their labels are hard to obtain. Although many pool-based AL methods have been developed, the lack of a comparative benchmarking and integration of techniques makes it difficult to: 1) determine the current state-of-the-art technique; 2) evaluate the relative benefit of new methods for various properties of the dataset; 3) understand what specific problems merit greater attention; and 4) measure the progress of the field over time. To conduct easier comparative evaluation among AL methods, we present a benchmark task for pool-based active learning, which consists of benchmarking datasets and quantitative metrics that summarize overall performance. We present experiment results for various active learning strategies, both recently proposed and classic highly-cited methods, and draw insights from the results.