 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPS: An Auto-Labeling and Pre-training Scheme for Remote Sensing Segmentation With Segment Anything Model
Jun 16, 2024In the fast-growing field of Remote Sensing (RS) image analysis, the gap between massive unlabeled datasets and the ability to fully utilize these datasets for advanced RS analytics presents a significant challenge. To fill the gap, our work introduces an innovative auto-labeling framework named ALPS (Automatic Labeling for Pre-training in Segmentation), leveraging the Segment Anything Model (SAM) to predict precise pseudo-labels for RS images without necessitating prior annotations or additional prompts. The proposed pipeline significantly reduces the labor and resource demands traditionally associated with annotating RS datasets. By constructing two comprehensive pseudo-labeled RS datasets via ALPS for pre-training purposes, our approach enhances the performance of downstream tasks across various benchmarks, including iSAID and ISPRS Potsdam. Experiments demonstrate the effectiveness of our framework, showcasing its ability to generalize well across multiple tasks even under the scarcity of extensively annotated datasets, offering a scalable solution to automatic segmentation and annotation challenges in the field. In addition, the proposed a pipeline is flexible and can be applied to medical image segmentation, remarkably boosting the performance. Note that ALPS utilizes pre-trained SAM to semi-automatically annotate RS images without additional manual annotations. Though every component in the pipeline has bee well explored, integrating clustering algorithms with SAM and novel pseudo-label alignment significantly enhances RS segmentation, as an off-the-shelf tool for pre-training data preparation. Our source code is available at: https://github.com/StriveZs/ALPS.
TiC: Exploring Vision Transformer in Convolution
Oct 06, 2023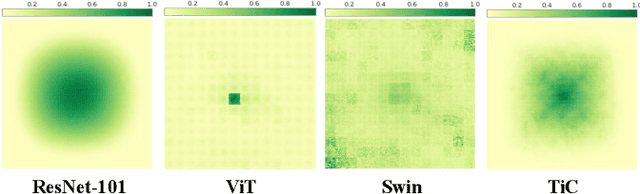

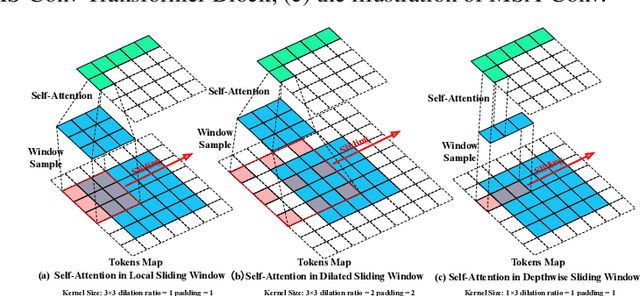

While models derived from Vision Transformers (ViTs) have been phonemically surging, pre-trained models cannot seamlessly adapt to arbitrary resolution images without altering the architecture and configuration, such as sampling the positional encoding, limiting their flexibility for various vision tasks. For instance, the Segment Anything Model (SAM) based on ViT-Huge requires all input images to be resized to 1024$\times$1024. To overcome this limitation, we propose the Multi-Head Self-Attention Convolution (MSA-Conv) that incorporates Self-Attention within generalized convolutions, including standard, dilated, and depthwise ones. Enabling transformers to handle images of varying sizes without retraining or rescaling, the use of MSA-Conv further reduces computational costs compared to global attention in ViT, which grows costly as image size increases. Later, we present the Vision Transformer in Convolution (TiC) as a proof of concept for image classification with MSA-Conv, where two capacity enhancing strategies, namely Multi-Directional Cyclic Shifted Mechanism and Inter-Pooling Mechanism, have been proposed, through establishing long-distance connections between tokens and enlarging the effective receptive field. Extensive experiments have been carried out to validate the overall effectiveness of TiC. Additionally, ablation studies confirm the performance improvement made by MSA-Conv and the two capacity enhancing strategies separately. Note that our proposal aims at studying an alternative to the global attention used in ViT, while MSA-Conv meets our goal by making TiC comparable to state-of-the-art on ImageNet-1K. Code will be released at https://github.com/zs670980918/MSA-Conv.
CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
Oct 06, 2023



While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
MUSCLE: Multi-task Self-supervised Continual Learning to Pre-train Deep Models for X-ray Images of Multiple Body Parts
Oct 03, 2023While self-supervised learning (SSL) algorithms have been widely used to pre-train deep models, few efforts [11] have been done to improve representation learning of X-ray image analysis with SSL pre-trained models. In this work, we study a novel self-supervised pre-training pipeline, namely Multi-task Self-super-vised Continual Learning (MUSCLE), for multiple medical imaging tasks, such as classification and segmentation, using X-ray images collected from multiple body parts, including heads, lungs, and bones. Specifically, MUSCLE aggregates X-rays collected from multiple body parts for MoCo-based representation learning, and adopts a well-designed continual learning (CL) procedure to further pre-train the backbone subject various X-ray analysis tasks jointly. Certain strategies for image pre-processing, learning schedules, and regularization have been used to solve data heterogeneity, overfitting, and catastrophic forgetting problems for multi-task/dataset learning in MUSCLE.We evaluate MUSCLE using 9 real-world X-ray datasets with various tasks, including pneumonia classification, skeletal abnormality classification, lung segmentation, and tuberculosis (TB) detection. Comparisons against other pre-trained models [7] confirm the proof-of-concept that self-supervised multi-task/dataset continual pre-training could boost the performance of X-ray image analysis.
Video4MRI: An Empirical Study on Brain Magnetic Resonance Image Analytics with CNN-based Video Classification Frameworks
Feb 24, 2023To address the problem of medical image recognition, computer vision techniques like convolutional neural networks (CNN) are frequently used. Recently, 3D CNN-based models dominate the field of magnetic resonance image (MRI) analytics. Due to the high similarity between MRI data and videos, we conduct extensive empirical studies on video recognition techniques for MRI classification to answer the questions: (1) can we directly use video recognition models for MRI classification, (2) which model is more appropriate for MRI, (3) are the common tricks like data augmentation in video recognition still useful for MRI classification? Our work suggests that advanced video techniques benefit MRI classification. In this paper, four datasets of Alzheimer's and Parkinson's disease recognition are utilized in experiments, together with three alternative video recognition models and data augmentation techniques that are frequently applied to video tasks. In terms of efficiency, the results reveal that the video framework performs better than 3D-CNN models by 5% - 11% with 50% - 66% less trainable parameters. This report pushes forward the potential fusion of 3D medical imaging and video understanding research.
Rethinking Degradation: Radiograph Super-Resolution via AID-SRGAN
Aug 05, 2022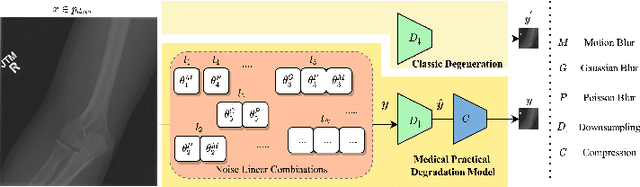
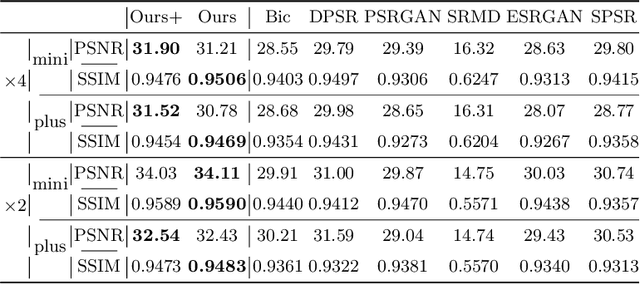
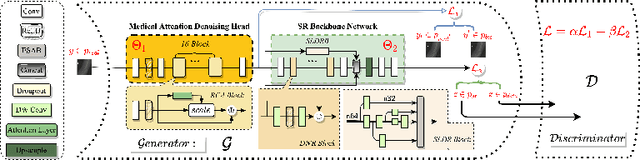

In this paper, we present a medical AttentIon Denoising Super Resolution Generative Adversarial Network (AID-SRGAN) for diographic image super-resolution. First, we present a medical practical degradation model that considers various degradation factors beyond downsampling. To the best of our knowledge, this is the first composite degradation model proposed for radiographic images. Furthermore, we propose AID-SRGAN, which can simultaneously denoise and generate high-resolution (HR) radiographs. In this model, we introduce an attention mechanism into the denoising module to make it more robust to complicated degradation. Finally, the SR module reconstructs the HR radiographs using the "clean" low-resolution (LR) radiographs. In addition, we propose a separate-joint training approach to train the model, and extensive experiments are conducted to show that the proposed method is superior to its counterparts. e.g., our proposed method achieves $31.90$ of PSNR with a scale factor of $4 \times$, which is $7.05 \%$ higher than that obtained by recent work, SPSR [16]. Our dataset and code will be made available at: https://github.com/yongsongH/AIDSRGAN-MICCAI2022.
$\textbf{P$^2$A}$: A Dataset and Benchmark for Dense Action Detection from Table Tennis Match Broadcasting Videos
Jul 26, 2022
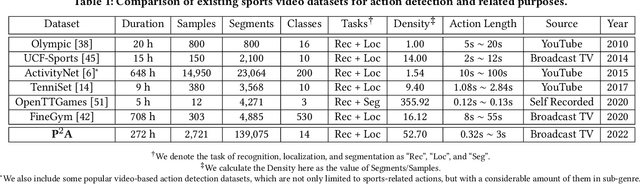

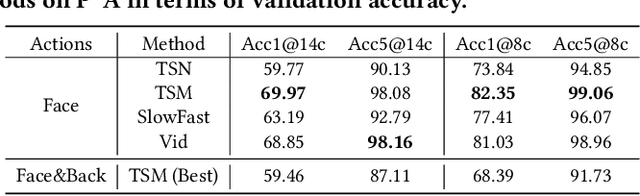
While deep learning has been widely used for video analytics, such as video classification and action detection, dense action detection with fast-moving subjects from sports videos is still challenging. In this work, we release yet another sports video dataset $\textbf{P$^2$A}$ for $\underline{P}$ing $\underline{P}$ong-$\underline{A}$ction detection, which consists of 2,721 video clips collected from the broadcasting videos of professional table tennis matches in World Table Tennis Championships and Olympiads. We work with a crew of table tennis professionals and referees to obtain fine-grained action labels (in 14 classes) for every ping-pong action that appeared in the dataset and formulate two sets of action detection problems - action localization and action recognition. We evaluate a number of commonly-seen action recognition (e.g., TSM, TSN, Video SwinTransformer, and Slowfast) and action localization models (e.g., BSN, BSN++, BMN, TCANet), using $\textbf{P$^2$A}$ for both problems, under various settings. These models can only achieve 48% area under the AR-AN curve for localization and 82% top-one accuracy for recognition since the ping-pong actions are dense with fast-moving subjects but broadcasting videos are with only 25 FPS. The results confirm that $\textbf{P$^2$A}$ is still a challenging task and can be used as a benchmark for action detection from videos.
Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022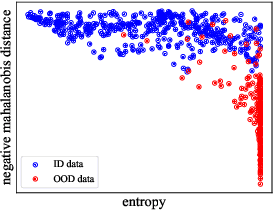
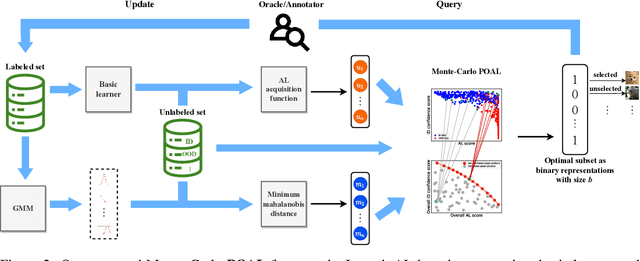
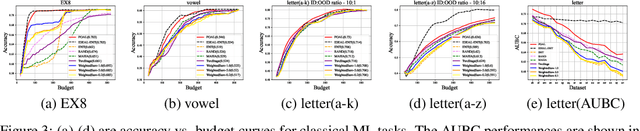
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
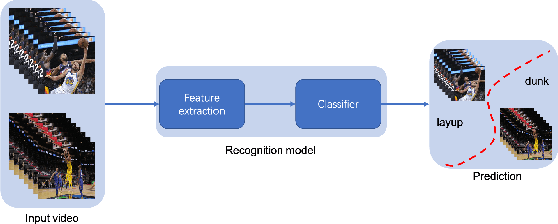
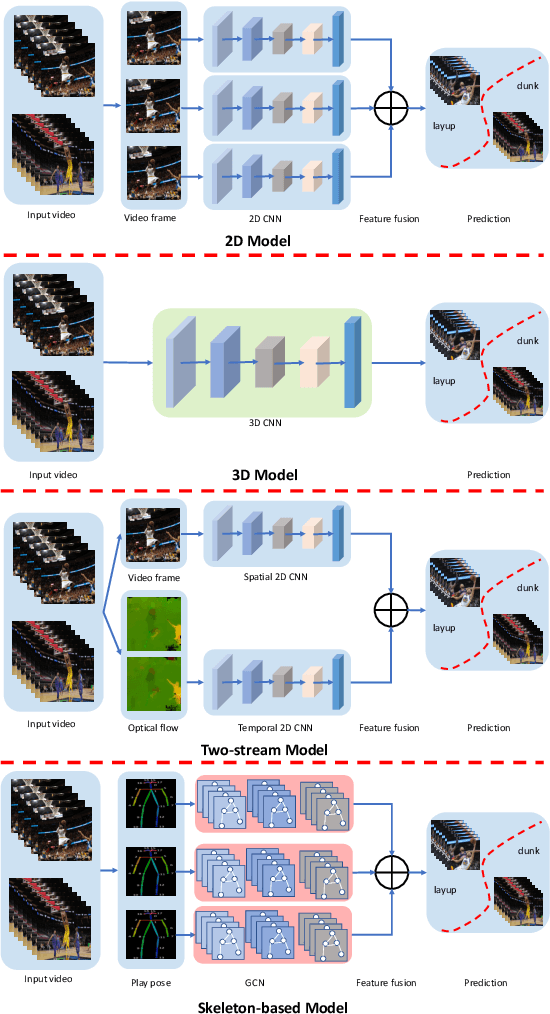
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Practical Strategies of Active Learning to Rank for Web Search
May 20, 2022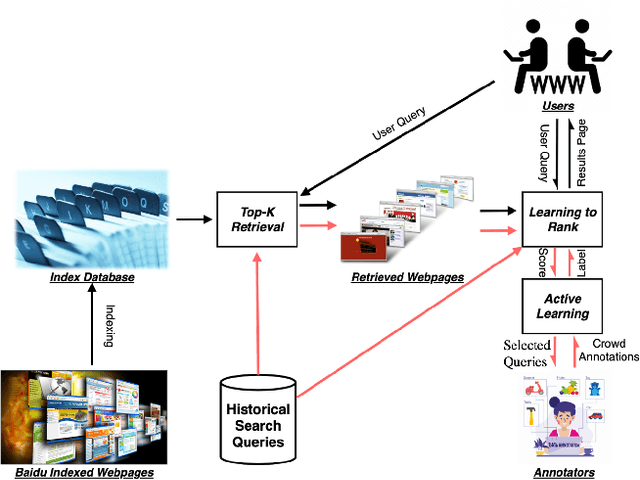
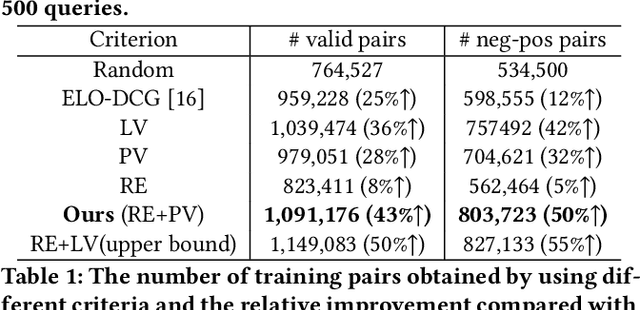
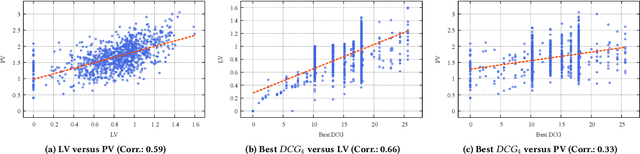
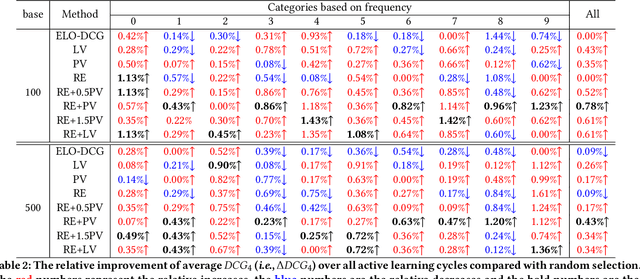
While China has become the biggest online market in the world with around 1 billion internet users, Baidu runs the world largest Chinese search engine serving more than hundreds of millions of daily active users and responding billions queries per day. To handle the diverse query requests from users at web-scale, Baidu has done tremendous efforts in understanding users' queries, retrieve relevant contents from a pool of trillions of webpages, and rank the most relevant webpages on the top of results. Among these components used in Baidu search, learning to rank (LTR) plays a critical role and we need to timely label an extremely large number of queries together with relevant webpages to train and update the online LTR models. To reduce the costs and time consumption of queries/webpages labeling, we study the problem of Activ Learning to Rank (active LTR) that selects unlabeled queries for annotation and training in this work. Specifically, we first investigate the criterion -- Ranking Entropy (RE) characterizing the entropy of relevant webpages under a query produced by a sequence of online LTR models updated by different checkpoints, using a Query-By-Committee (QBC) method. Then, we explore a new criterion namely Prediction Variances (PV) that measures the variance of prediction results for all relevant webpages under a query. Our empirical studies find that RE may favor low-frequency queries from the pool for labeling while PV prioritizing high-frequency queries more. Finally, we combine these two complementary criteria as the sample selection strategies for active learning. Extensive experiments with comparisons to baseline algorithms show that the proposed approach could train LTR models achieving higher Discounted Cumulative Gain (i.e., the relative improvement {\Delta}DCG4=1.38%) with the same budgeted labeling efforts.