 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textbf{P$^2$A}$: A Dataset and Benchmark for Dense Action Detection from Table Tennis Match Broadcasting Videos
Jul 26, 2022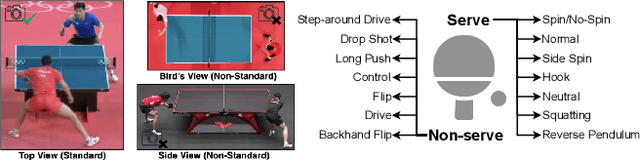
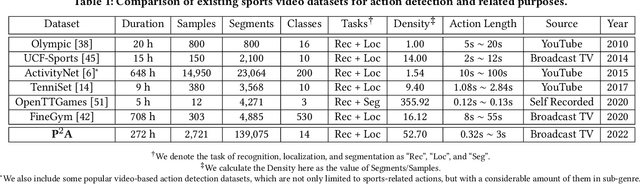

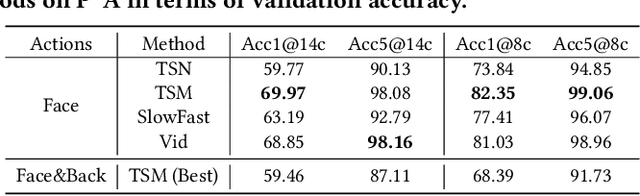
While deep learning has been widely used for video analytics, such as video classification and action detection, dense action detection with fast-moving subjects from sports videos is still challenging. In this work, we release yet another sports video dataset $\textbf{P$^2$A}$ for $\underline{P}$ing $\underline{P}$ong-$\underline{A}$ction detection, which consists of 2,721 video clips collected from the broadcasting videos of professional table tennis matches in World Table Tennis Championships and Olympiads. We work with a crew of table tennis professionals and referees to obtain fine-grained action labels (in 14 classes) for every ping-pong action that appeared in the dataset and formulate two sets of action detection problems - action localization and action recognition. We evaluate a number of commonly-seen action recognition (e.g., TSM, TSN, Video SwinTransformer, and Slowfast) and action localization models (e.g., BSN, BSN++, BMN, TCANet), using $\textbf{P$^2$A}$ for both problems, under various settings. These models can only achieve 48% area under the AR-AN curve for localization and 82% top-one accuracy for recognition since the ping-pong actions are dense with fast-moving subjects but broadcasting videos are with only 25 FPS. The results confirm that $\textbf{P$^2$A}$ is still a challenging task and can be used as a benchmark for action detection from videos.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
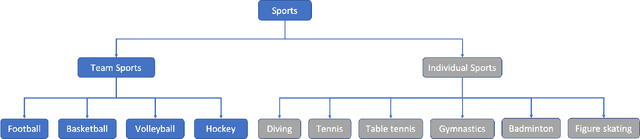
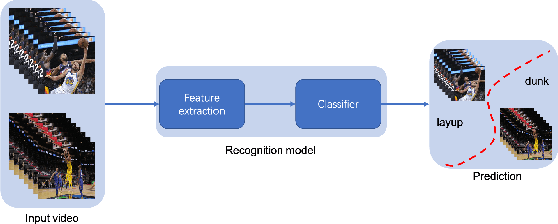
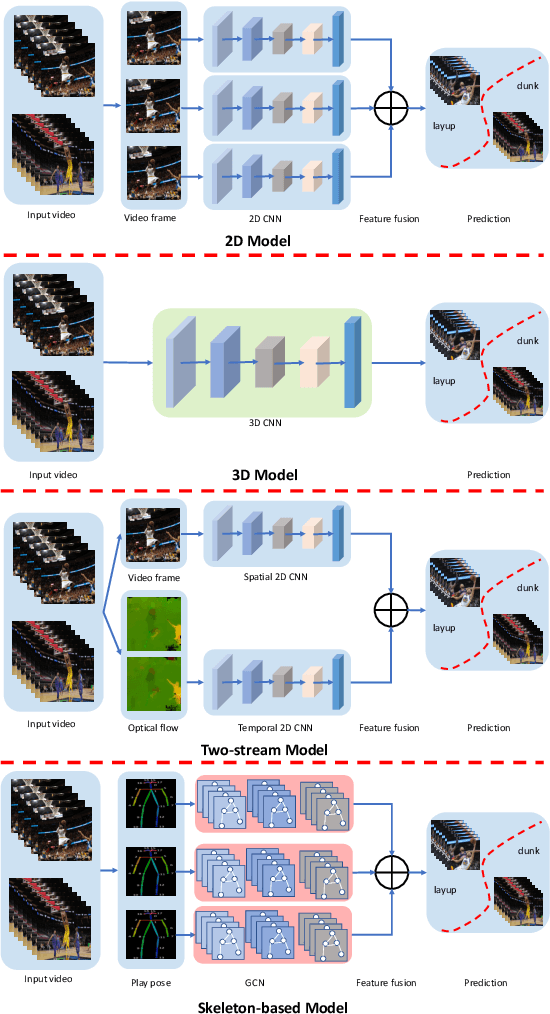
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Aug 25, 2021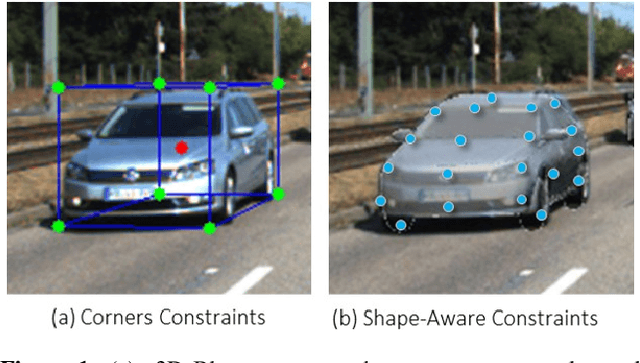
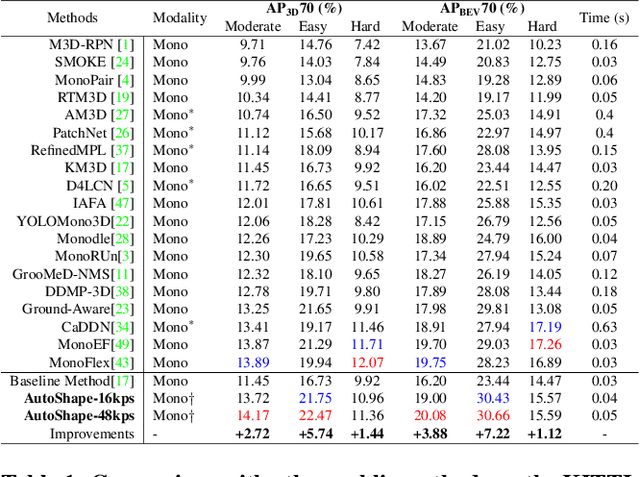
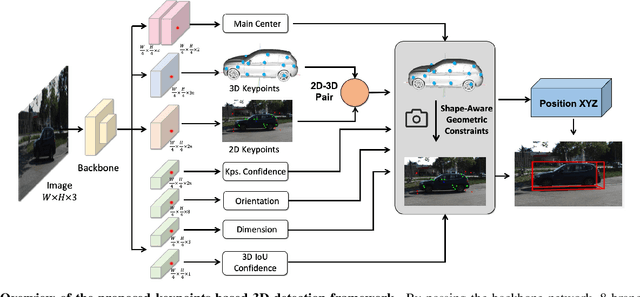
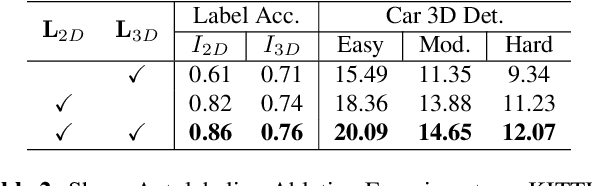
Existing deep learning-based approaches for monocular 3D object detection in autonomous driving often model the object as a rotated 3D cuboid while the object's geometric shape has been ignored. In this work, we propose an approach for incorporating the shape-aware 2D/3D constraints into the 3D detection framework. Specifically, we employ the deep neural network to learn distinguished 2D keypoints in the 2D image domain and regress their corresponding 3D coordinates in the local 3D object coordinate first. Then the 2D/3D geometric constraints are built by these correspondences for each object to boost the detection performance. For generating the ground truth of 2D/3D keypoints, an automatic model-fitting approach has been proposed by fitting the deformed 3D object model and the object mask in the 2D image. The proposed framework has been verified on the public KITTI dataset and the experimental results demonstrate that by using additional geometrical constraints the detection performance has been significantly improved as compared to the baseline method. More importantly, the proposed framework achieves state-of-the-art performance with real time. Data and code will be available at https://github.com/zongdai/AutoShape
Robust 2D/3D Vehicle Parsing in CVIS
Mar 11, 2021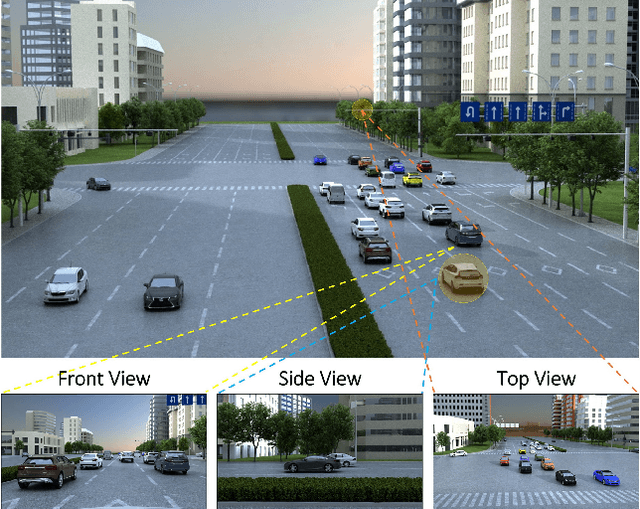
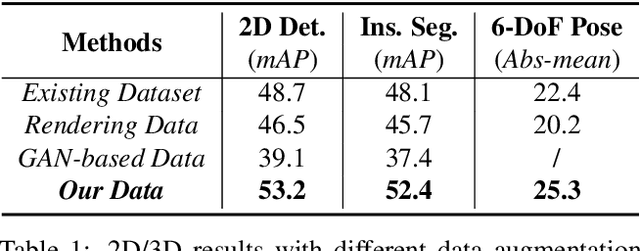
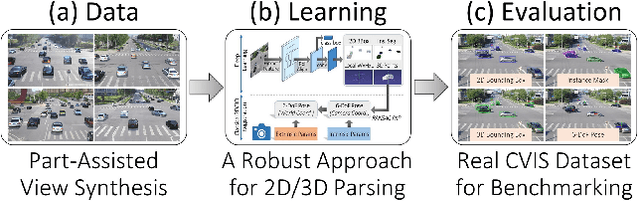
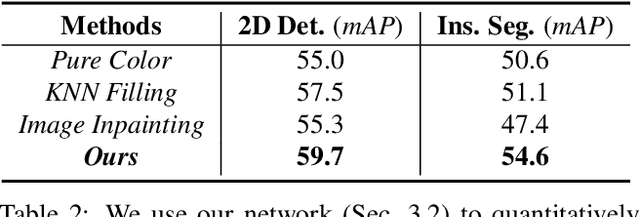
We present a novel approach to robustly detect and perceive vehicles in different camera views as part of a cooperative vehicle-infrastructure system (CVIS). Our formulation is designed for arbitrary camera views and makes no assumptions about intrinsic or extrinsic parameters. First, to deal with multi-view data scarcity, we propose a part-assisted novel view synthesis algorithm for data augmentation. We train a part-based texture inpainting network in a self-supervised manner. Then we render the textured model into the background image with the target 6-DoF pose. Second, to handle various camera parameters, we present a new method that produces dense mappings between image pixels and 3D points to perform robust 2D/3D vehicle parsing. Third, we build the first CVIS dataset for benchmarking, which annotates more than 1540 images (14017 instances) from real-world traffic scenarios. We combine these novel algorithms and datasets to develop a robust approach for 2D/3D vehicle parsing for CVIS. In practice, our approach outperforms SOTA methods on 2D detection, instance segmentation, and 6-DoF pose estimation, by 4.5%, 4.3%, and 2.9%, respectively. More details and results are included in the supplement. To facilitate future research, we will release the source code and the dataset on GitHub.
IAFA: Instance-aware Feature Aggregation for 3D Object Detection from a Single Image
Mar 05, 2021
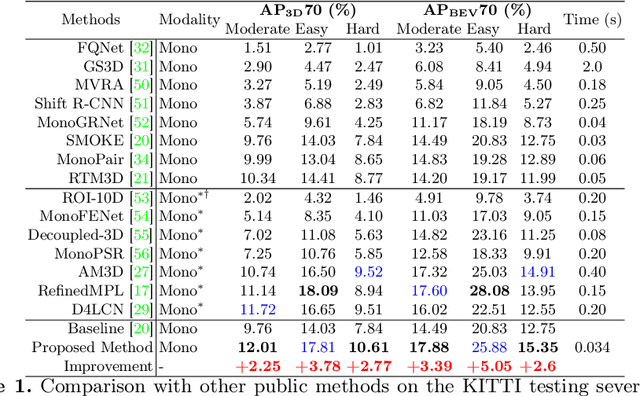
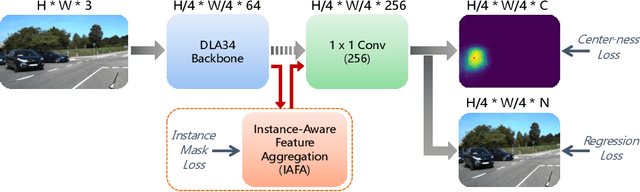
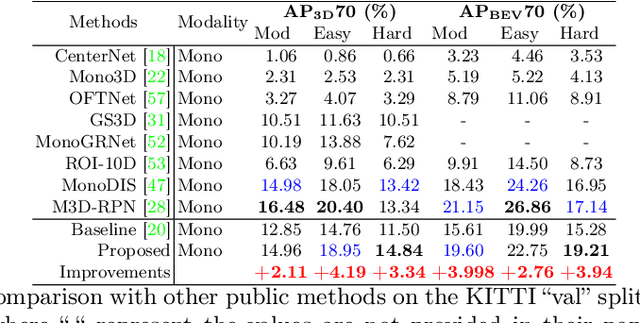
3D object detection from a single image is an important task in Autonomous Driving (AD), where various approaches have been proposed. However, the task is intrinsically ambiguous and challenging as single image depth estimation is already an ill-posed problem. In this paper, we propose an instance-aware approach to aggregate useful information for improving the accuracy of 3D object detection with the following contributions. First, an instance-aware feature aggregation (IAFA) module is proposed to collect local and global features for 3D bounding boxes regression. Second, we empirically find that the spatial attention module can be well learned by taking coarse-level instance annotations as a supervision signal. The proposed module has significantly boosted the performance of the baseline method on both 3D detection and 2D bird-eye's view of vehicle detection among all three categories. Third, our proposed method outperforms all single image-based approaches (even these methods trained with depth as auxiliary inputs) and achieves state-of-the-art 3D detection performance on the KITTI benchmark.
Fine-Grained Vehicle Perception via 3D Part-Guided Visual Data Augmentation
Jan 06, 2021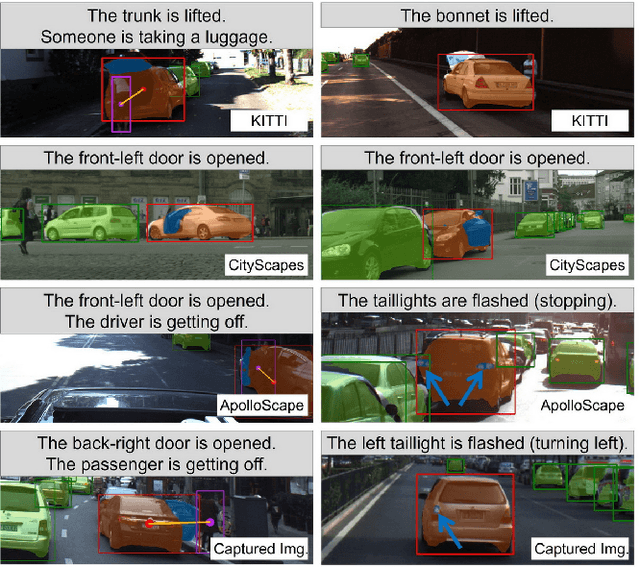
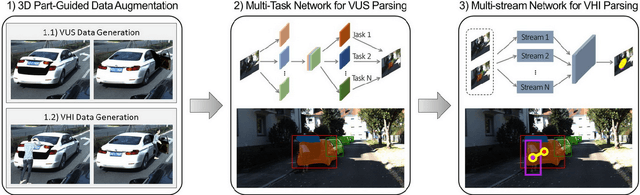
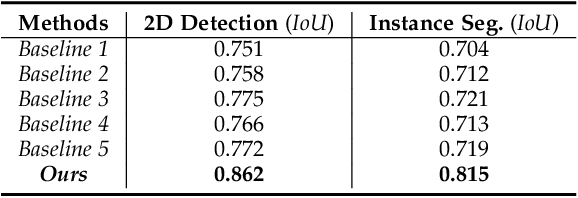
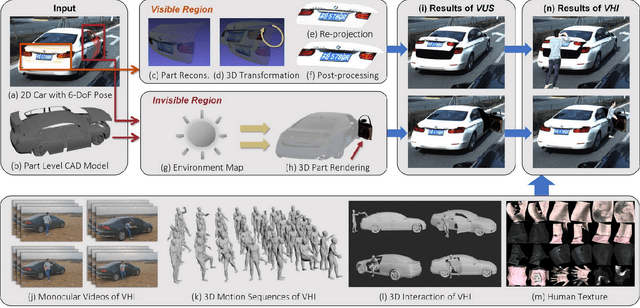
Holistically understanding an object and its 3D movable parts through visual perception models is essential for enabling an autonomous agent to interact with the world. For autonomous driving, the dynamics and states of vehicle parts such as doors, the trunk, and the bonnet can provide meaningful semantic information and interaction states, which are essential to ensuring the safety of the self-driving vehicle. Existing visual perception models mainly focus on coarse parsing such as object bounding box detection or pose estimation and rarely tackle these situations. In this paper, we address this important autonomous driving problem by solving three critical issues. First, to deal with data scarcity, we propose an effective training data generation process by fitting a 3D car model with dynamic parts to vehicles in real images before reconstructing human-vehicle interaction (VHI) scenarios. Our approach is fully automatic without any human interaction, which can generate a large number of vehicles in uncommon states (VUS) for training deep neural networks (DNNs). Second, to perform fine-grained vehicle perception, we present a multi-task network for VUS parsing and a multi-stream network for VHI parsing. Third, to quantitatively evaluate the effectiveness of our data augmentation approach, we build the first VUS dataset in real traffic scenarios (e.g., getting on/out or placing/removing luggage). Experimental results show that our approach advances other baseline methods in 2D detection and instance segmentation by a big margin (over 8%). In addition, our network yields large improvements in discovering and understanding these uncommon cases. Moreover, we have released the source code, the dataset, and the trained model on Github (https://github.com/zongdai/EditingForDNN).
AES: Autonomous Excavator System for Real-World and Hazardous Environments
Nov 10, 2020
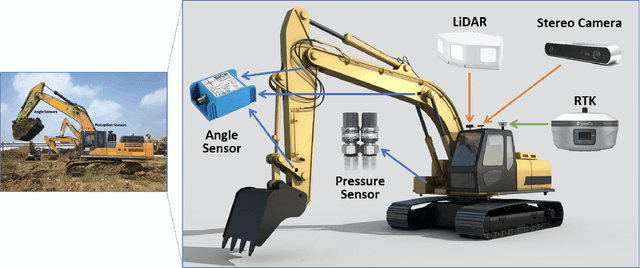
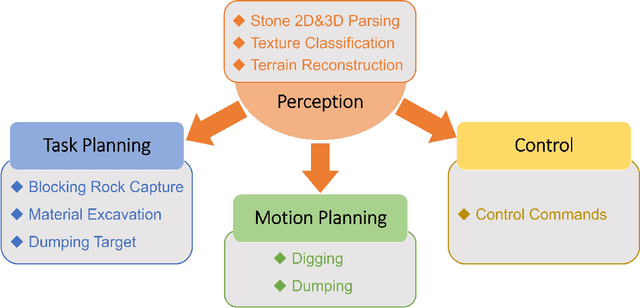
Excavators are widely used for material-handling applications in unstructured environments, including mining and construction. The size of the global market of excavators is 44.12 Billion USD in 2018 and is predicted to grow to 63.14 Billion USD by 2026. Operating excavators in a real-world environment can be challenging due to extreme conditions and rock sliding, ground collapse, or exceeding dust. Multiple fatalities and injuries occur each year during excavations. An autonomous excavator that can substitute human operators in these hazardous environments would substantially lower the number of injuries and can improve the overall productivity.
DVI: Depth Guided Video Inpainting for Autonomous Driving
Jul 17, 2020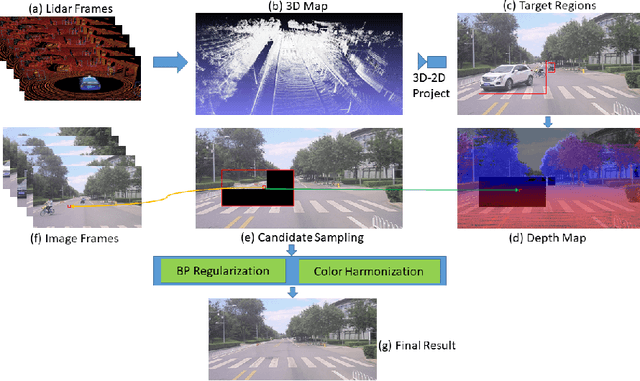
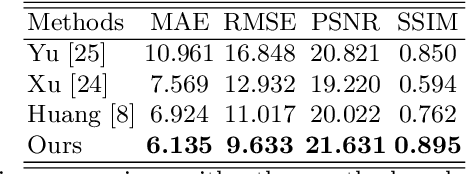


To get clear street-view and photo-realistic simulation in autonomous driving, we present an automatic video inpainting algorithm that can remove traffic agents from videos and synthesize missing regions with the guidance of depth/point cloud. By building a dense 3D map from stitched point clouds, frames within a video are geometrically correlated via this common 3D map. In order to fill a target inpainting area in a frame, it is straightforward to transform pixels from other frames into the current one with correct occlusion. Furthermore, we are able to fuse multiple videos through 3D point cloud registration, making it possible to inpaint a target video with multiple source videos. The motivation is to solve the long-time occlusion problem where an occluded area has never been visible in the entire video. To our knowledge, we are the first to fuse multiple videos for video inpainting. To verify the effectiveness of our approach, we build a large inpainting dataset in the real urban road environment with synchronized images and Lidar data including many challenge scenes, e.g., long time occlusion. The experimental results show that the proposed approach outperforms the state-of-the-art approaches for all the criteria, especially the RMSE (Root Mean Squared Error) has been reduced by about 13%.
PerMO: Perceiving More at Once from a Single Image for Autonomous Driving
Jul 16, 2020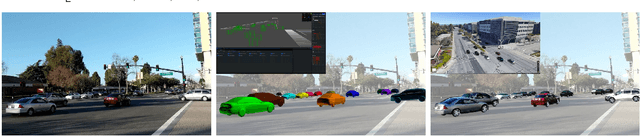

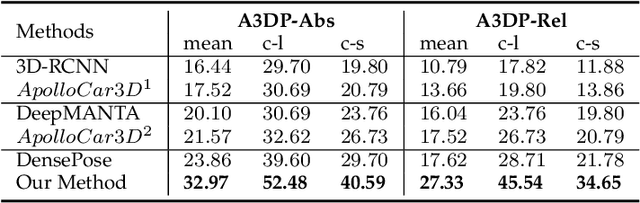
We present a novel approach to detect, segment, and reconstruct complete textured 3D models of vehicles from a single image for autonomous driving. Our approach combines the strengths of deep learning and the elegance of traditional techniques from part-based deformable model representation to produce high-quality 3D models in the presence of severe occlusions. We present a new part-based deformable vehicle model that is used for instance segmentation and automatically generate a dataset that contains dense correspondences between 2D images and 3D models. We also present a novel end-to-end deep neural network to predict dense 2D/3D mapping and highlight its benefits. Based on the dense mapping, we are able to compute precise 6-DoF poses and 3D reconstruction results at almost interactive rates on a commodity GPU. We have integrated these algorithms with an autonomous driving system. In practice, our method outperforms the state-of-the-art methods for all major vehicle parsing tasks: 2D instance segmentation by 4.4 points (mAP), 6-DoF pose estimation by 9.11 points, and 3D detection by 1.37. Moreover, we have released all of the source code, dataset, and the trained model on Github.
Part-level Car Parsing and Reconstruction from Single Street View
Nov 27, 2018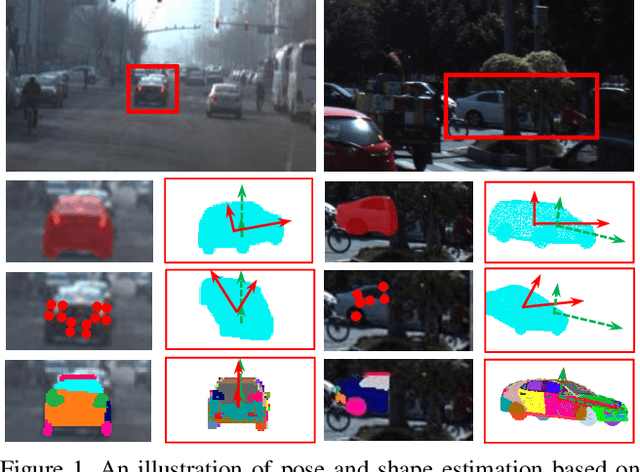
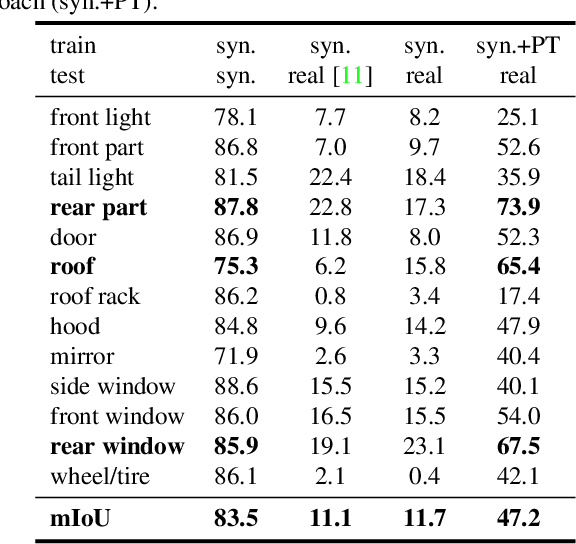
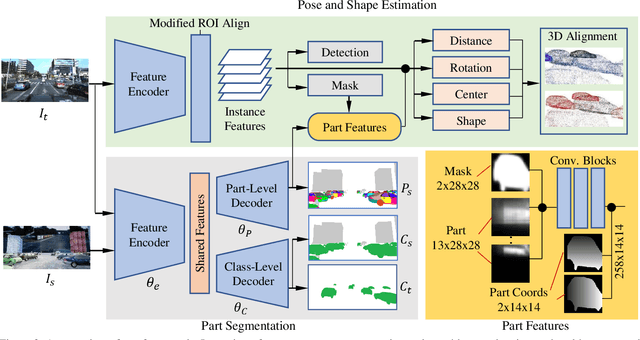
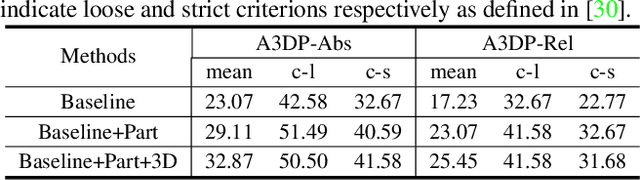
In this paper, we make the first attempt to build a framework to simultaneously estimate semantic parts, shape, translation, and orientation of cars from single street view. Our framework contains three major contributions. Firstly, a novel domain adaptation approach based on the class consistency loss is developed to transfer our part segmentation model from the synthesized images to the real images. Secondly, we propose a novel network structure that leverages part-level features from street views and 3D losses for pose and shape estimation. Thirdly, we construct a high quality dataset that contains more than 300 different car models with physical dimensions and part-level annotations based on global and local deformations. We have conducted experiments on both synthesized data and real images. Our results show that the domain adaptation approach can bring 35.5 percentage point performance improvement in terms of mean intersection-over-union score (mIoU) comparing with the baseline network using domain randomization only. Our network for translation and orientation estimation achieves competitive performance on highly complex street views (e.g., 11 cars per image on average). Moreover, our network is able to reconstruct a list of 3D car models with part-level details from street views, which could benefit various applications such as fine-grained car recognition, vehicle re-identification, and traffic simulation.