 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Vehicle Perception via 3D Part-Guided Visual Data Augmentation
Paper and Code
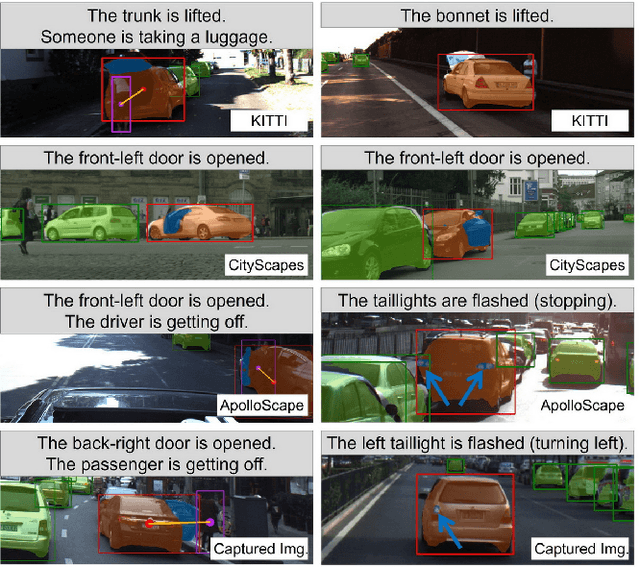
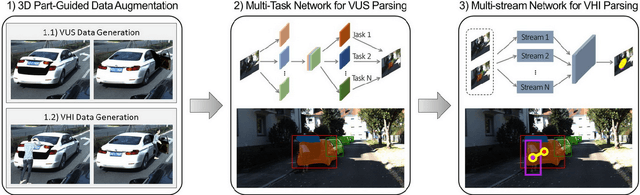
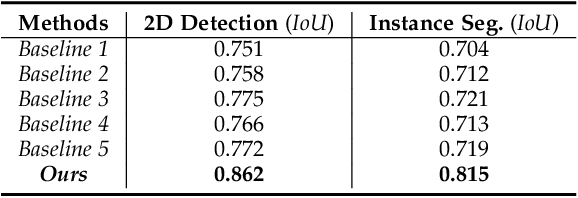
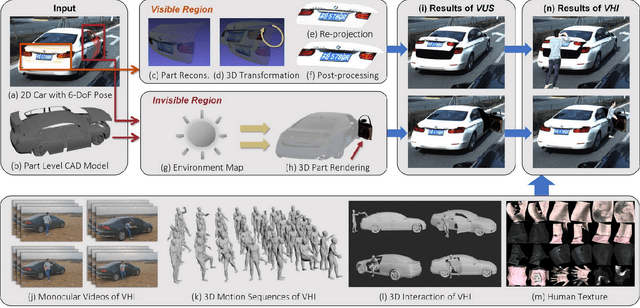
Holistically understanding an object and its 3D movable parts through visual perception models is essential for enabling an autonomous agent to interact with the world. For autonomous driving, the dynamics and states of vehicle parts such as doors, the trunk, and the bonnet can provide meaningful semantic information and interaction states, which are essential to ensuring the safety of the self-driving vehicle. Existing visual perception models mainly focus on coarse parsing such as object bounding box detection or pose estimation and rarely tackle these situations. In this paper, we address this important autonomous driving problem by solving three critical issues. First, to deal with data scarcity, we propose an effective training data generation process by fitting a 3D car model with dynamic parts to vehicles in real images before reconstructing human-vehicle interaction (VHI) scenarios. Our approach is fully automatic without any human interaction, which can generate a large number of vehicles in uncommon states (VUS) for training deep neural networks (DNNs). Second, to perform fine-grained vehicle perception, we present a multi-task network for VUS parsing and a multi-stream network for VHI parsing. Third, to quantitatively evaluate the effectiveness of our data augmentation approach, we build the first VUS dataset in real traffic scenarios (e.g., getting on/out or placing/removing luggage). Experimental results show that our approach advances other baseline methods in 2D detection and instance segmentation by a big margin (over 8%). In addition, our network yields large improvements in discovering and understanding these uncommon cases. Moreover, we have released the source code, the dataset, and the trained model on Github (https://github.com/zongdai/EditingForDNN).