 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Vision-Language Models on Millions of Videos
Jan 11, 2024



The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video-language model is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023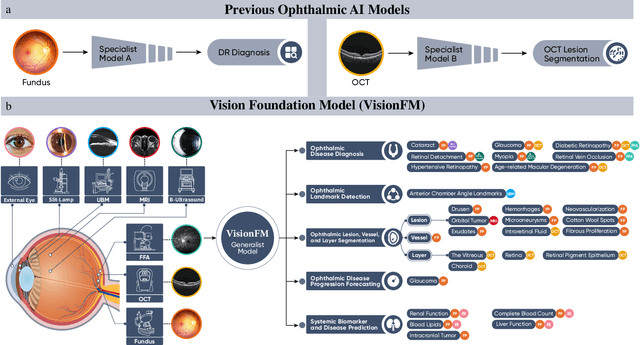
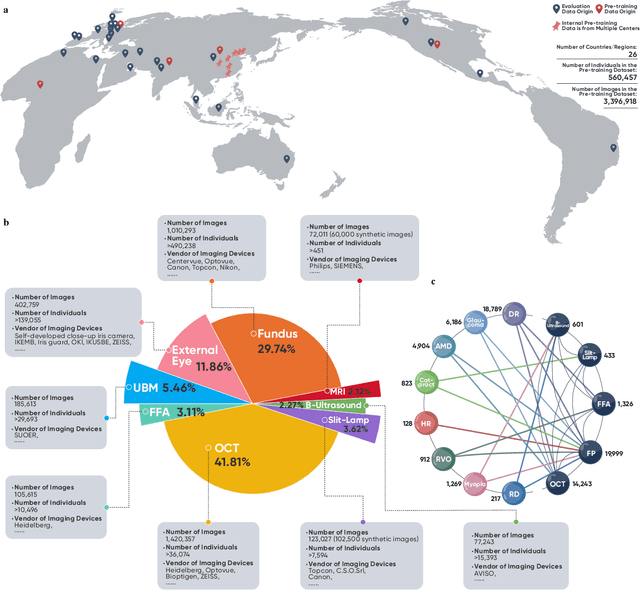

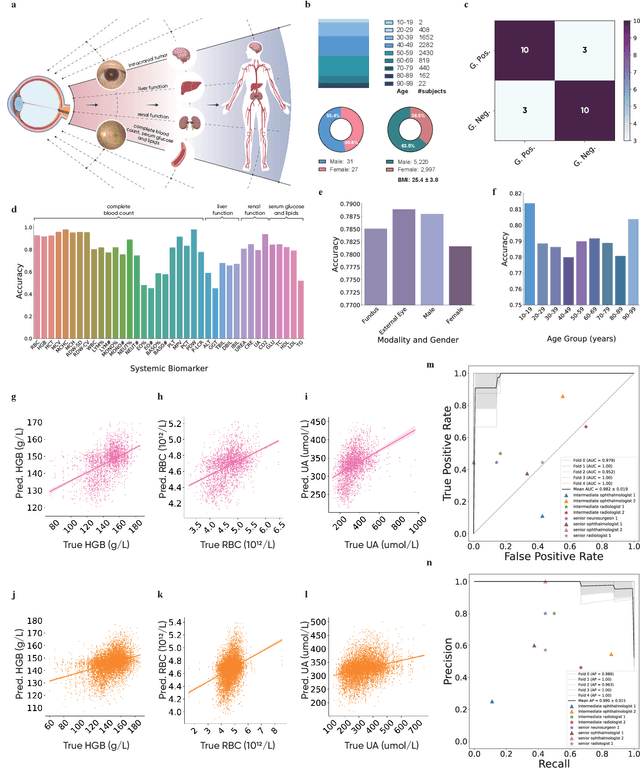
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
RFDforFin: Robust Deep Forgery Detection for GAN-generated Fingerprint Images
Aug 18, 2023



With the rapid development of the image generation technologies, the malicious abuses of the GAN-generated fingerprint images poses a significant threat to the public safety in certain circumstances. Although the existing universal deep forgery detection approach can be applied to detect the fake fingerprint images, they are easily attacked and have poor robustness. Meanwhile, there is no specifically designed deep forgery detection method for fingerprint images. In this paper, we propose the first deep forgery detection approach for fingerprint images, which combines unique ridge features of fingerprint and generation artifacts of the GAN-generated images, to the best of our knowledge. Specifically, we firstly construct a ridge stream, which exploits the grayscale variations along the ridges to extract unique fingerprint-specific features. Then, we construct a generation artifact stream, in which the FFT-based spectrums of the input fingerprint images are exploited, to extract more robust generation artifact features. At last, the unique ridge features and generation artifact features are fused for binary classification (\textit{i.e.}, real or fake). Comprehensive experiments demonstrate that our proposed approach is effective and robust with low complexities.
Production Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities
Mar 30, 2021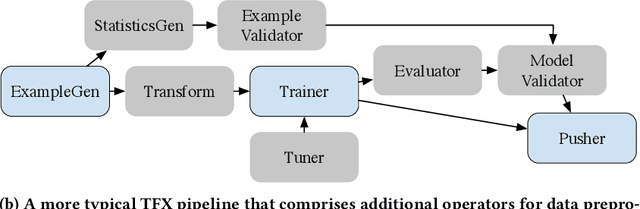
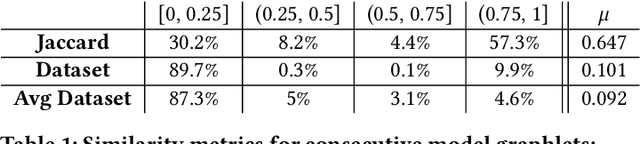
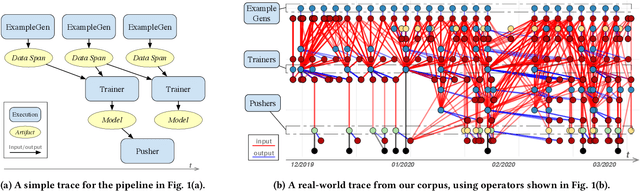
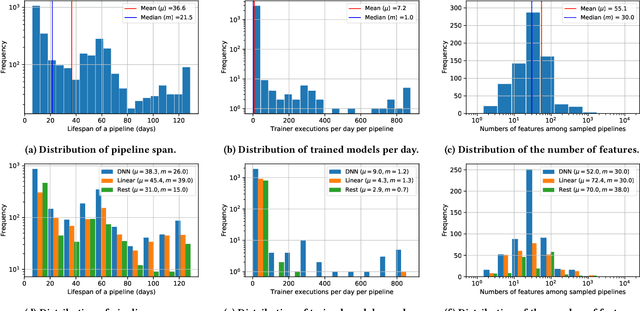
Machine learning (ML) is now commonplace, powering data-driven applications in various organizations. Unlike the traditional perception of ML in research, ML production pipelines are complex, with many interlocking analytical components beyond training, whose sub-parts are often run multiple times on overlapping subsets of data. However, there is a lack of quantitative evidence regarding the lifespan, architecture, frequency, and complexity of these pipelines to understand how data management research can be used to make them more efficient, effective, robust, and reproducible. To that end, we analyze the provenance graphs of 3000 production ML pipelines at Google, comprising over 450,000 models trained, spanning a period of over four months, in an effort to understand the complexity and challenges underlying production ML. Our analysis reveals the characteristics, components, and topologies of typical industry-strength ML pipelines at various granularities. Along the way, we introduce a specialized data model for representing and reasoning about repeatedly run components in these ML pipelines, which we call model graphlets. We identify several rich opportunities for optimization, leveraging traditional data management ideas. We show how targeting even one of these opportunities, i.e., identifying and pruning wasted computation that does not translate to model deployment, can reduce wasted computation cost by 50% without compromising the model deployment cadence.
Robust 2D/3D Vehicle Parsing in CVIS
Mar 11, 2021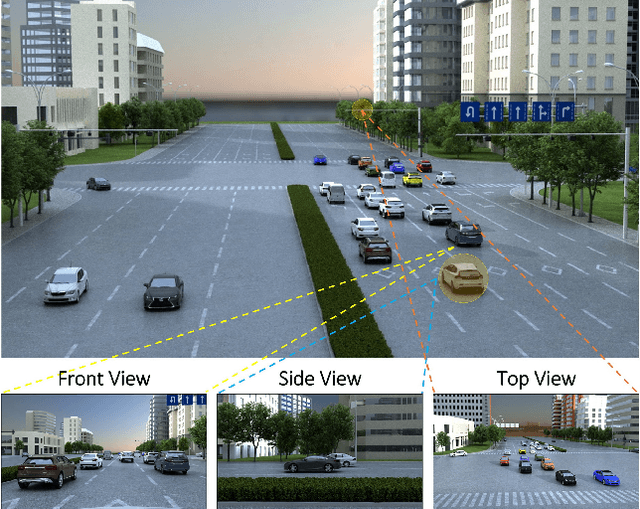
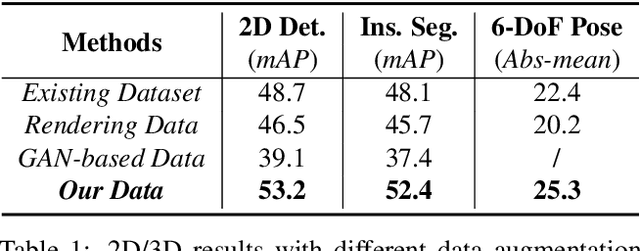
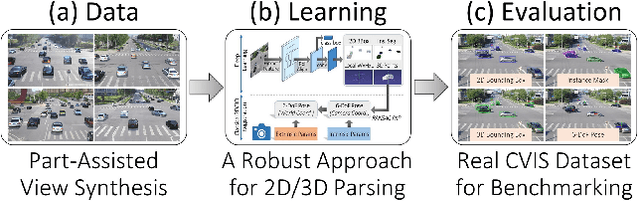
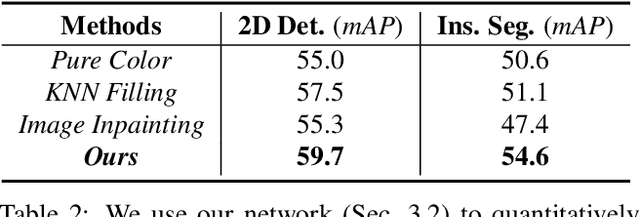
We present a novel approach to robustly detect and perceive vehicles in different camera views as part of a cooperative vehicle-infrastructure system (CVIS). Our formulation is designed for arbitrary camera views and makes no assumptions about intrinsic or extrinsic parameters. First, to deal with multi-view data scarcity, we propose a part-assisted novel view synthesis algorithm for data augmentation. We train a part-based texture inpainting network in a self-supervised manner. Then we render the textured model into the background image with the target 6-DoF pose. Second, to handle various camera parameters, we present a new method that produces dense mappings between image pixels and 3D points to perform robust 2D/3D vehicle parsing. Third, we build the first CVIS dataset for benchmarking, which annotates more than 1540 images (14017 instances) from real-world traffic scenarios. We combine these novel algorithms and datasets to develop a robust approach for 2D/3D vehicle parsing for CVIS. In practice, our approach outperforms SOTA methods on 2D detection, instance segmentation, and 6-DoF pose estimation, by 4.5%, 4.3%, and 2.9%, respectively. More details and results are included in the supplement. To facilitate future research, we will release the source code and the dataset on GitHub.
Fine-Grained Vehicle Perception via 3D Part-Guided Visual Data Augmentation
Jan 06, 2021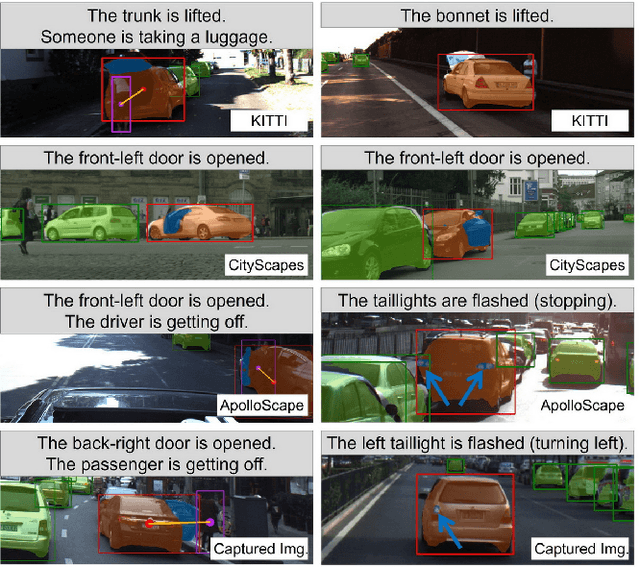
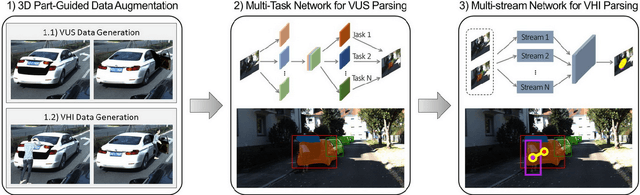
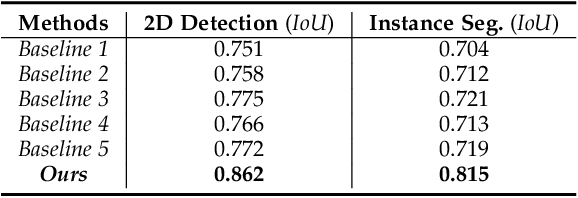
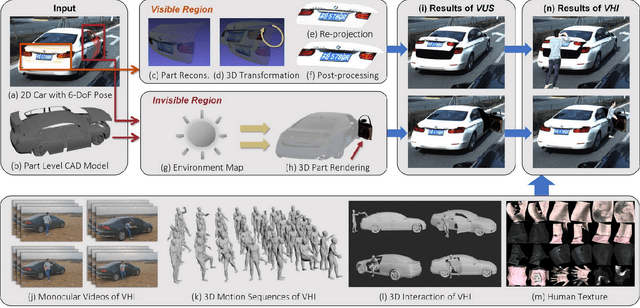
Holistically understanding an object and its 3D movable parts through visual perception models is essential for enabling an autonomous agent to interact with the world. For autonomous driving, the dynamics and states of vehicle parts such as doors, the trunk, and the bonnet can provide meaningful semantic information and interaction states, which are essential to ensuring the safety of the self-driving vehicle. Existing visual perception models mainly focus on coarse parsing such as object bounding box detection or pose estimation and rarely tackle these situations. In this paper, we address this important autonomous driving problem by solving three critical issues. First, to deal with data scarcity, we propose an effective training data generation process by fitting a 3D car model with dynamic parts to vehicles in real images before reconstructing human-vehicle interaction (VHI) scenarios. Our approach is fully automatic without any human interaction, which can generate a large number of vehicles in uncommon states (VUS) for training deep neural networks (DNNs). Second, to perform fine-grained vehicle perception, we present a multi-task network for VUS parsing and a multi-stream network for VHI parsing. Third, to quantitatively evaluate the effectiveness of our data augmentation approach, we build the first VUS dataset in real traffic scenarios (e.g., getting on/out or placing/removing luggage). Experimental results show that our approach advances other baseline methods in 2D detection and instance segmentation by a big margin (over 8%). In addition, our network yields large improvements in discovering and understanding these uncommon cases. Moreover, we have released the source code, the dataset, and the trained model on Github (https://github.com/zongdai/EditingForDNN).
PerMO: Perceiving More at Once from a Single Image for Autonomous Driving
Jul 16, 2020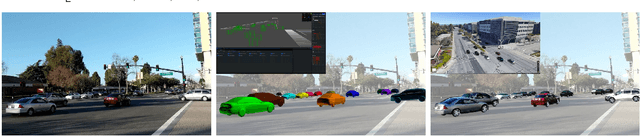

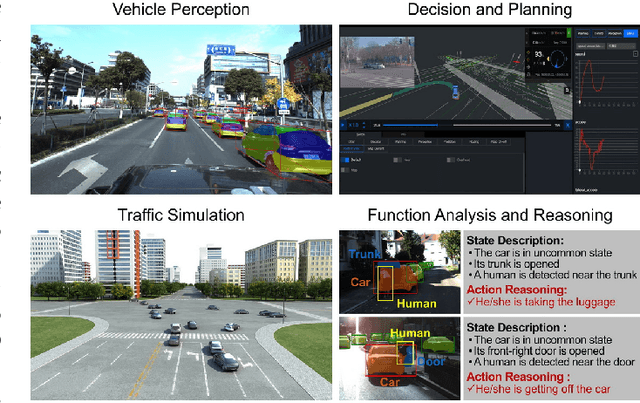
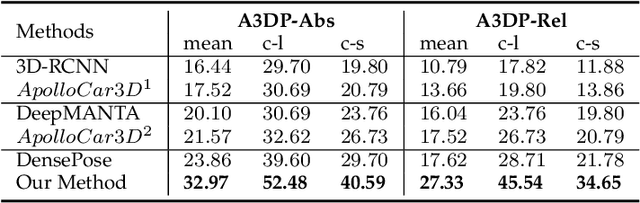
We present a novel approach to detect, segment, and reconstruct complete textured 3D models of vehicles from a single image for autonomous driving. Our approach combines the strengths of deep learning and the elegance of traditional techniques from part-based deformable model representation to produce high-quality 3D models in the presence of severe occlusions. We present a new part-based deformable vehicle model that is used for instance segmentation and automatically generate a dataset that contains dense correspondences between 2D images and 3D models. We also present a novel end-to-end deep neural network to predict dense 2D/3D mapping and highlight its benefits. Based on the dense mapping, we are able to compute precise 6-DoF poses and 3D reconstruction results at almost interactive rates on a commodity GPU. We have integrated these algorithms with an autonomous driving system. In practice, our method outperforms the state-of-the-art methods for all major vehicle parsing tasks: 2D instance segmentation by 4.4 points (mAP), 6-DoF pose estimation by 9.11 points, and 3D detection by 1.37. Moreover, we have released all of the source code, dataset, and the trained model on Github.
ModelHub: Towards Unified Data and Lifecycle Management for Deep Learning
Nov 18, 2016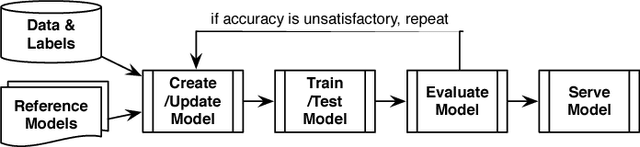
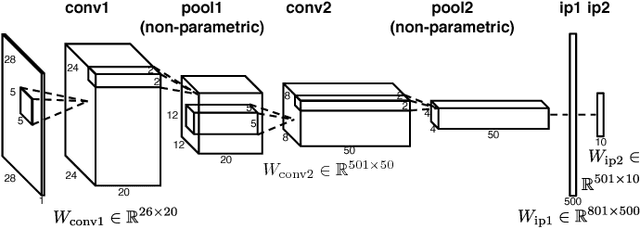
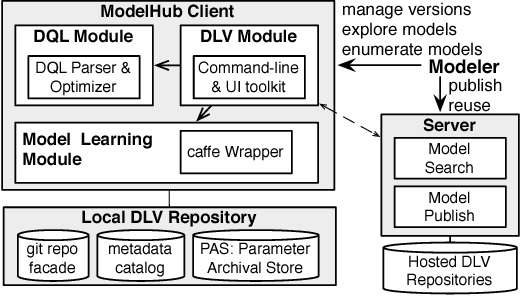
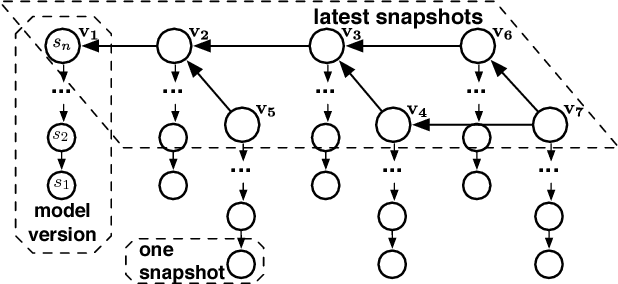
Deep learning has improved state-of-the-art results in many important fields, and has been the subject of much research in recent years, leading to the development of several systems for facilitating deep learning. Current systems, however, mainly focus on model building and training phases, while the issues of data management, model sharing, and lifecycle management are largely ignored. Deep learning modeling lifecycle generates a rich set of data artifacts, such as learned parameters and training logs, and comprises of several frequently conducted tasks, e.g., to understand the model behaviors and to try out new models. Dealing with such artifacts and tasks is cumbersome and largely left to the users. This paper describes our vision and implementation of a data and lifecycle management system for deep learning. First, we generalize model exploration and model enumeration queries from commonly conducted tasks by deep learning modelers, and propose a high-level domain specific language (DSL), inspired by SQL, to raise the abstraction level and accelerate the modeling process. To manage the data artifacts, especially the large amount of checkpointed float parameters, we design a novel model versioning system (dlv), and a read-optimized parameter archival storage system (PAS) that minimizes storage footprint and accelerates query workloads without losing accuracy. PAS archives versioned models using deltas in a multi-resolution fashion by separately storing the less significant bits, and features a novel progressive query (inference) evaluation algorithm. Third, we show that archiving versioned models using deltas poses a new dataset versioning problem and we develop efficient algorithms for solving it. We conduct extensive experiments over several real datasets from computer vision domain to show the efficiency of the proposed techniques.
A Hypergraph-Partitioned Vertex Programming Approach for Large-scale Consensus Optimization
Aug 30, 2013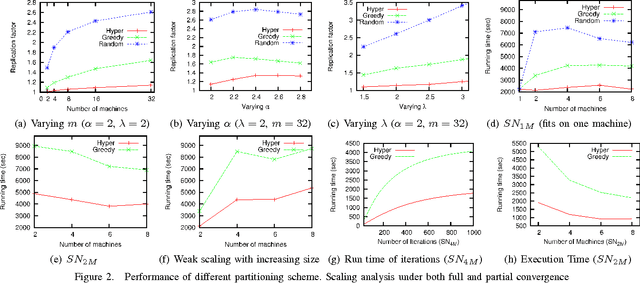
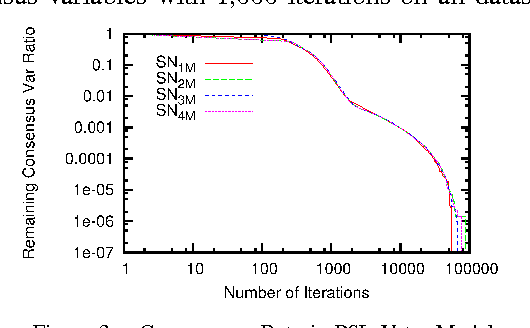
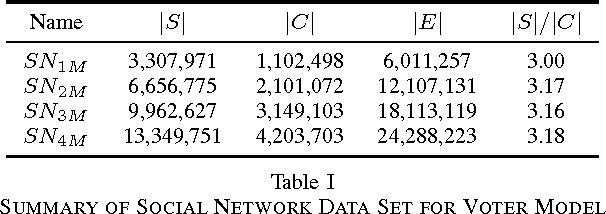
In modern data science problems, techniques for extracting value from big data require performing large-scale optimization over heterogenous, irregularly structured data. Much of this data is best represented as multi-relational graphs, making vertex programming abstractions such as those of Pregel and GraphLab ideal fits for modern large-scale data analysis. In this paper, we describe a vertex-programming implementation of a popular consensus optimization technique known as the alternating direction of multipliers (ADMM). ADMM consensus optimization allows elegant solution of complex objectives such as inference in rich probabilistic models. We also introduce a novel hypergraph partitioning technique that improves over state-of-the-art partitioning techniques for vertex programming and significantly reduces the communication cost by reducing the number of replicated nodes up to an order of magnitude. We implemented our algorithm in GraphLab and measure scaling performance on a variety of realistic bipartite graph distributions and a large synthetic voter-opinion analysis application. In our experiments, we are able to achieve a 50% improvement in runtime over the current state-of-the-art GraphLab partitioning scheme.