 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks on Lottery Ticket Networks
Aug 07, 2021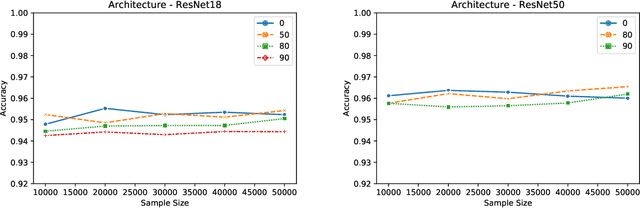
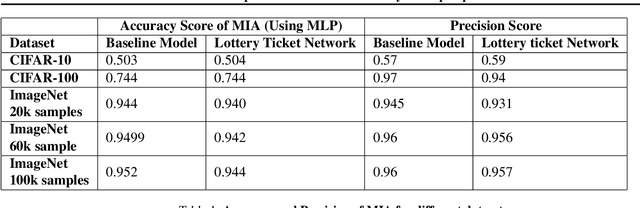
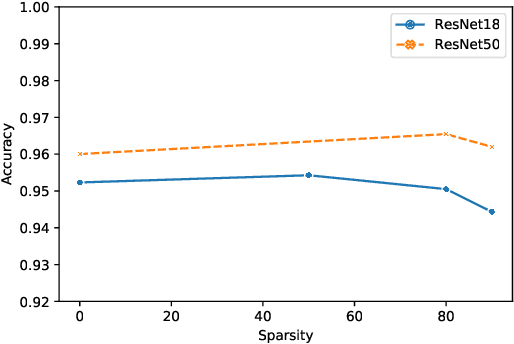
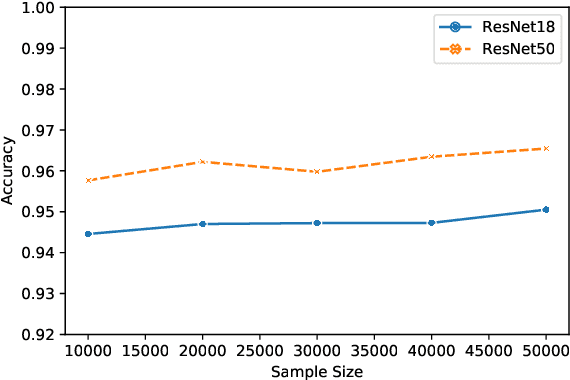
The vulnerability of the Lottery Ticket Hypothesis has not been studied from the purview of Membership Inference Attacks. Through this work, we are the first to empirically show that the lottery ticket networks are equally vulnerable to membership inference attacks. A Membership Inference Attack (MIA) is the process of determining whether a data sample belongs to a training set of a trained model or not. Membership Inference Attacks could leak critical information about the training data that can be used for targeted attacks. Recent deep learning models often have very large memory footprints and a high computational cost associated with training and drawing inferences. Lottery Ticket Hypothesis is used to prune the networks to find smaller sub-networks that at least match the performance of the original model in terms of test accuracy in a similar number of iterations. We used CIFAR-10, CIFAR-100, and ImageNet datasets to perform image classification tasks and observe that the attack accuracies are similar. We also see that the attack accuracy varies directly according to the number of classes in the dataset and the sparsity of the network. We demonstrate that these attacks are transferable across models with high accuracy.
ModelHub: Towards Unified Data and Lifecycle Management for Deep Learning
Nov 18, 2016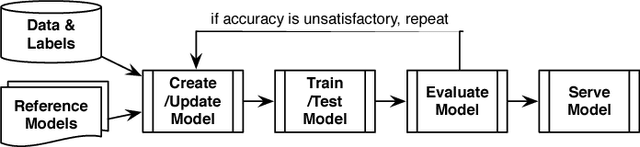
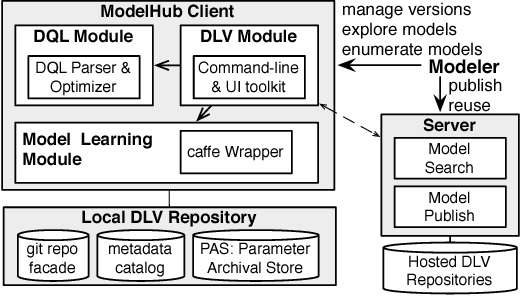
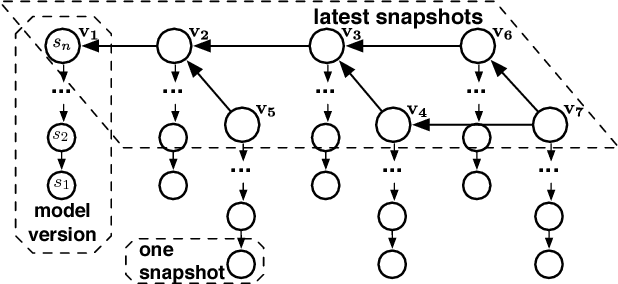
Deep learning has improved state-of-the-art results in many important fields, and has been the subject of much research in recent years, leading to the development of several systems for facilitating deep learning. Current systems, however, mainly focus on model building and training phases, while the issues of data management, model sharing, and lifecycle management are largely ignored. Deep learning modeling lifecycle generates a rich set of data artifacts, such as learned parameters and training logs, and comprises of several frequently conducted tasks, e.g., to understand the model behaviors and to try out new models. Dealing with such artifacts and tasks is cumbersome and largely left to the users. This paper describes our vision and implementation of a data and lifecycle management system for deep learning. First, we generalize model exploration and model enumeration queries from commonly conducted tasks by deep learning modelers, and propose a high-level domain specific language (DSL), inspired by SQL, to raise the abstraction level and accelerate the modeling process. To manage the data artifacts, especially the large amount of checkpointed float parameters, we design a novel model versioning system (dlv), and a read-optimized parameter archival storage system (PAS) that minimizes storage footprint and accelerates query workloads without losing accuracy. PAS archives versioned models using deltas in a multi-resolution fashion by separately storing the less significant bits, and features a novel progressive query (inference) evaluation algorithm. Third, we show that archiving versioned models using deltas poses a new dataset versioning problem and we develop efficient algorithms for solving it. We conduct extensive experiments over several real datasets from computer vision domain to show the efficiency of the proposed techniques.
Efficient Stepwise Selection in Decomposable Models
Jan 10, 2013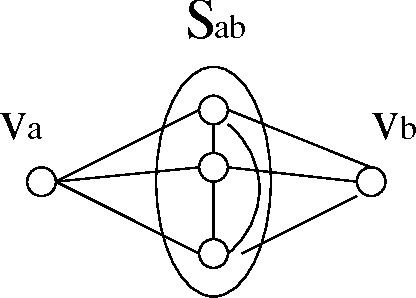
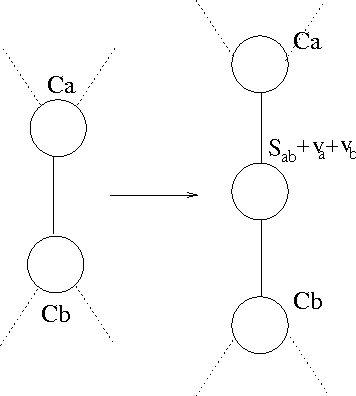
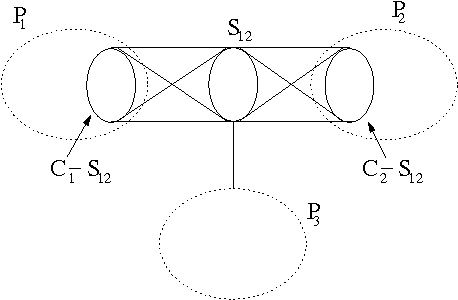
In this paper, we present an efficient way of performing stepwise selection in the class of decomposable models. The main contribution of the paper is a simple characterization of the edges that canbe added to a decomposable model while keeping the resulting model decomposable and an efficient algorithm for enumerating all such edges for a given model in essentially O(1) time per edge. We also discuss how backward selection can be performed efficiently using our data structures.We also analyze the complexity of the complete stepwise selection procedure, including the complexity of choosing which of the eligible dges to add to (or delete from) the current model, with the aim ofminimizing the Kullback-Leibler distance of the resulting model from the saturated model for the data.
Bisimulation-based Approximate Lifted Inference
May 09, 2012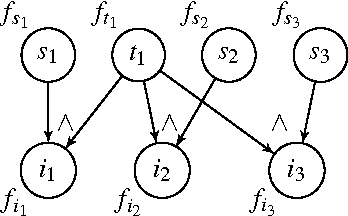

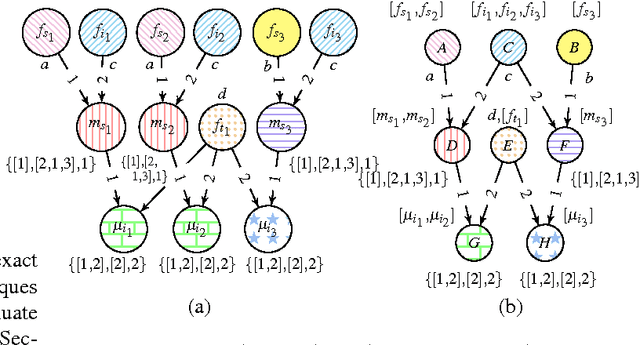
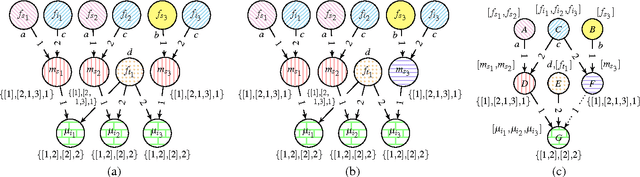
There has been a great deal of recent interest in methods for performing lifted inference; however, most of this work assumes that the first-order model is given as input to the system. Here, we describe lifted inference algorithms that determine symmetries and automatically lift the probabilistic model to speedup inference. In particular, we describe approximate lifted inference techniques that allow the user to trade off inference accuracy for computational efficiency by using a handful of tunable parameters, while keeping the error bounded. Our algorithms are closely related to the graph-theoretic concept of bisimulation. We report experiments on both synthetic and real data to show that in the presence of symmetries, run-times for inference can be improved significantly, with approximate lifted inference providing orders of magnitude speedup over ground inference.