 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelHub: Towards Unified Data and Lifecycle Management for Deep Learning
Paper and Code
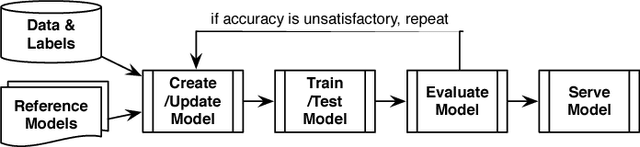
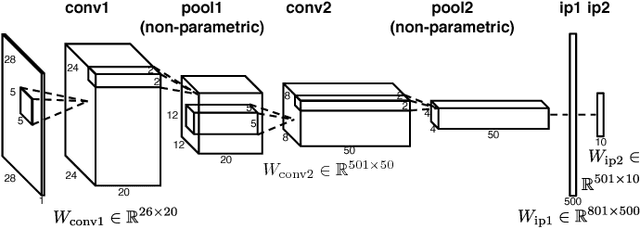
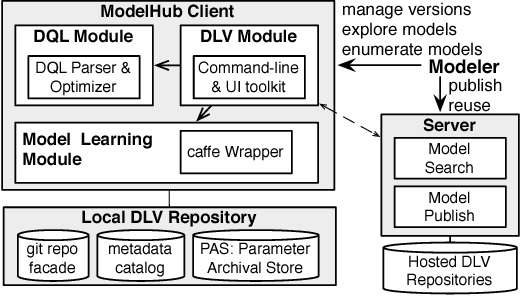
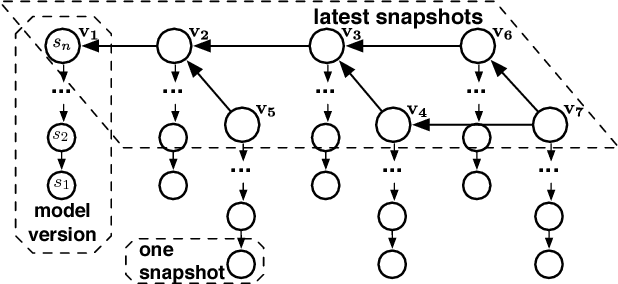
Deep learning has improved state-of-the-art results in many important fields, and has been the subject of much research in recent years, leading to the development of several systems for facilitating deep learning. Current systems, however, mainly focus on model building and training phases, while the issues of data management, model sharing, and lifecycle management are largely ignored. Deep learning modeling lifecycle generates a rich set of data artifacts, such as learned parameters and training logs, and comprises of several frequently conducted tasks, e.g., to understand the model behaviors and to try out new models. Dealing with such artifacts and tasks is cumbersome and largely left to the users. This paper describes our vision and implementation of a data and lifecycle management system for deep learning. First, we generalize model exploration and model enumeration queries from commonly conducted tasks by deep learning modelers, and propose a high-level domain specific language (DSL), inspired by SQL, to raise the abstraction level and accelerate the modeling process. To manage the data artifacts, especially the large amount of checkpointed float parameters, we design a novel model versioning system (dlv), and a read-optimized parameter archival storage system (PAS) that minimizes storage footprint and accelerates query workloads without losing accuracy. PAS archives versioned models using deltas in a multi-resolution fashion by separately storing the less significant bits, and features a novel progressive query (inference) evaluation algorithm. Third, we show that archiving versioned models using deltas poses a new dataset versioning problem and we develop efficient algorithms for solving it. We conduct extensive experiments over several real datasets from computer vision domain to show the efficiency of the proposed techniques.