 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary
Apr 29, 2021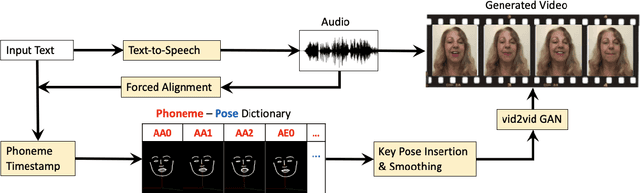

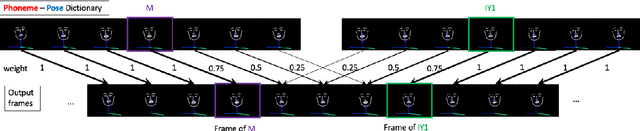
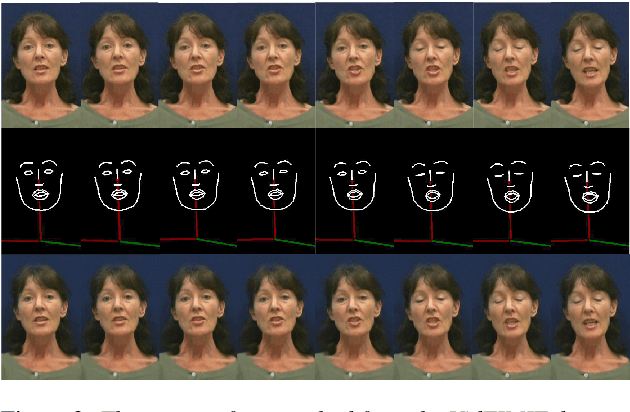
With the advance of deep learning technology, automatic video generation from audio or text has become an emerging and promising research topic. In this paper, we present a novel approach to synthesize video from the text. The method builds a phoneme-pose dictionary and trains a generative adversarial network (GAN) to generate video from interpolated phoneme poses. Compared to audio-driven video generation algorithms, our approach has a number of advantages: 1) It only needs a fraction of the training data used by an audio-driven approach; 2) It is more flexible and not subject to vulnerability due to speaker variation; 3) It significantly reduces the preprocessing, training and inference time. We perform extensive experiments to compare the proposed method with state-of-the-art talking face generation methods on a benchmark dataset and datasets of our own. The results demonstrate the effectiveness and superiority of our approach.
IAFA: Instance-aware Feature Aggregation for 3D Object Detection from a Single Image
Mar 05, 2021
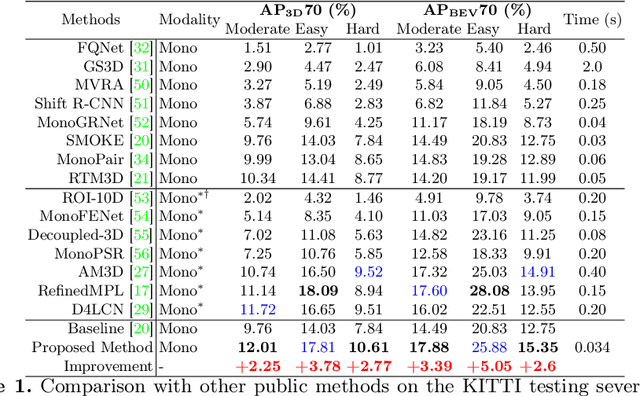
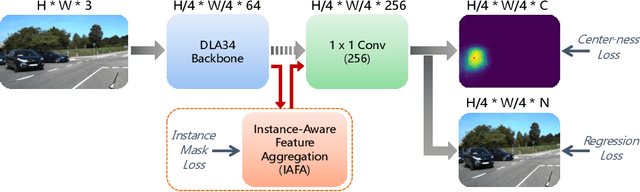
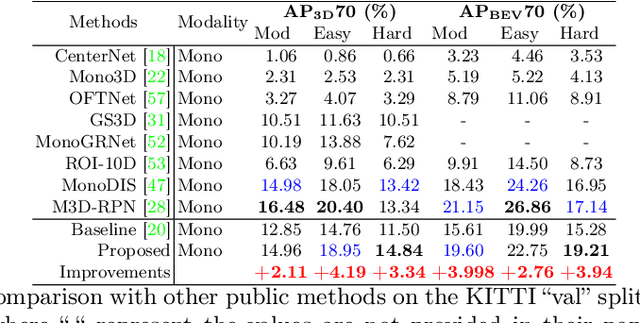
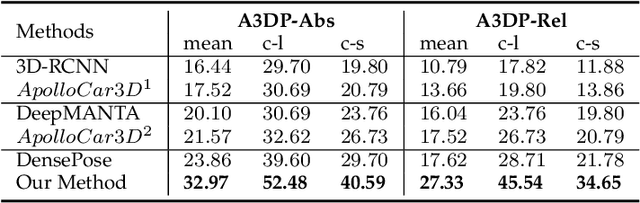
3D object detection from a single image is an important task in Autonomous Driving (AD), where various approaches have been proposed. However, the task is intrinsically ambiguous and challenging as single image depth estimation is already an ill-posed problem. In this paper, we propose an instance-aware approach to aggregate useful information for improving the accuracy of 3D object detection with the following contributions. First, an instance-aware feature aggregation (IAFA) module is proposed to collect local and global features for 3D bounding boxes regression. Second, we empirically find that the spatial attention module can be well learned by taking coarse-level instance annotations as a supervision signal. The proposed module has significantly boosted the performance of the baseline method on both 3D detection and 2D bird-eye's view of vehicle detection among all three categories. Third, our proposed method outperforms all single image-based approaches (even these methods trained with depth as auxiliary inputs) and achieves state-of-the-art 3D detection performance on the KITTI benchmark.
Personalized Speech2Video with 3D Skeleton Regularization and Expressive Body Poses
Jul 17, 2020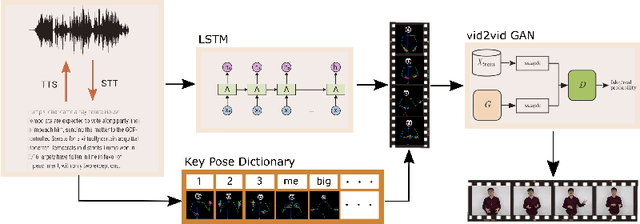
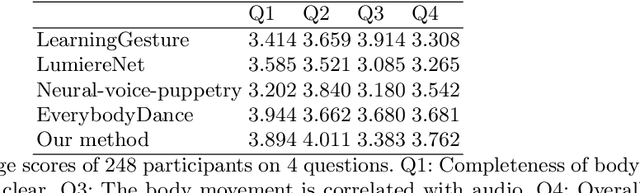
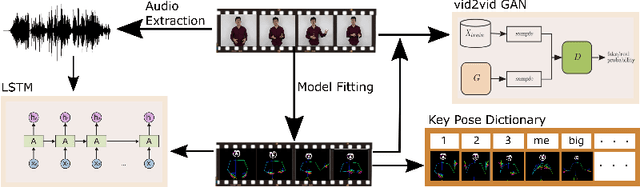
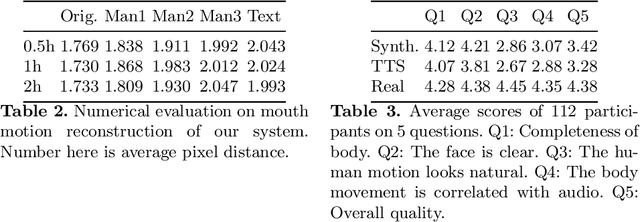
In this paper, we propose a novel approach to convert given speech audio to a photo-realistic speaking video of a specific person, where the output video has synchronized, realistic, and expressive rich body dynamics. We achieve this by first generating 3D skeleton movements from the audio sequence using a recurrent neural network (RNN), and then synthesizing the output video via a conditional generative adversarial network (GAN). To make the skeleton movement realistic and expressive, we embed the knowledge of an articulated 3D human skeleton and a learned dictionary of personal speech iconic gestures into the generation process in both learning and testing pipelines. The former prevents the generation of unreasonable body distortion, while the later helps our model quickly learn meaningful body movement through a few recorded videos. To produce photo-realistic and high-resolution video with motion details, we propose to insert part attention mechanisms in the conditional GAN, where each detailed part, e.g. head and hand, is automatically zoomed in to have their own discriminators. To validate our approach, we collect a dataset with 20 high-quality videos from 1 male and 1 female model reading various documents under different topics. Compared with previous SoTA pipelines handling similar tasks, our approach achieves better results by a user study.
DVI: Depth Guided Video Inpainting for Autonomous Driving
Jul 17, 2020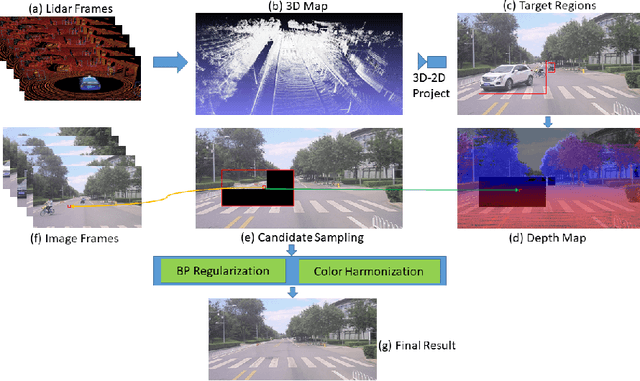
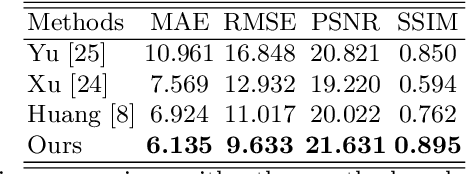


To get clear street-view and photo-realistic simulation in autonomous driving, we present an automatic video inpainting algorithm that can remove traffic agents from videos and synthesize missing regions with the guidance of depth/point cloud. By building a dense 3D map from stitched point clouds, frames within a video are geometrically correlated via this common 3D map. In order to fill a target inpainting area in a frame, it is straightforward to transform pixels from other frames into the current one with correct occlusion. Furthermore, we are able to fuse multiple videos through 3D point cloud registration, making it possible to inpaint a target video with multiple source videos. The motivation is to solve the long-time occlusion problem where an occluded area has never been visible in the entire video. To our knowledge, we are the first to fuse multiple videos for video inpainting. To verify the effectiveness of our approach, we build a large inpainting dataset in the real urban road environment with synchronized images and Lidar data including many challenge scenes, e.g., long time occlusion. The experimental results show that the proposed approach outperforms the state-of-the-art approaches for all the criteria, especially the RMSE (Root Mean Squared Error) has been reduced by about 13%.
PerMO: Perceiving More at Once from a Single Image for Autonomous Driving
Jul 16, 2020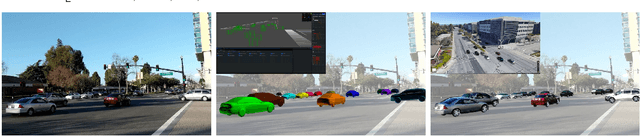

We present a novel approach to detect, segment, and reconstruct complete textured 3D models of vehicles from a single image for autonomous driving. Our approach combines the strengths of deep learning and the elegance of traditional techniques from part-based deformable model representation to produce high-quality 3D models in the presence of severe occlusions. We present a new part-based deformable vehicle model that is used for instance segmentation and automatically generate a dataset that contains dense correspondences between 2D images and 3D models. We also present a novel end-to-end deep neural network to predict dense 2D/3D mapping and highlight its benefits. Based on the dense mapping, we are able to compute precise 6-DoF poses and 3D reconstruction results at almost interactive rates on a commodity GPU. We have integrated these algorithms with an autonomous driving system. In practice, our method outperforms the state-of-the-art methods for all major vehicle parsing tasks: 2D instance segmentation by 4.4 points (mAP), 6-DoF pose estimation by 9.11 points, and 3D detection by 1.37. Moreover, we have released all of the source code, dataset, and the trained model on Github.
Analyzing Periodicity and Saliency for Adult Video Detection
Jan 11, 2019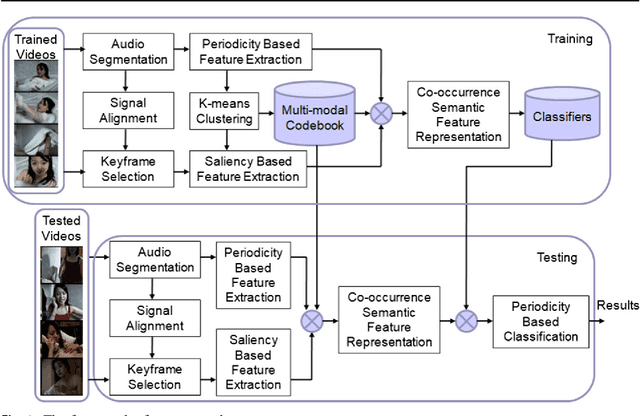

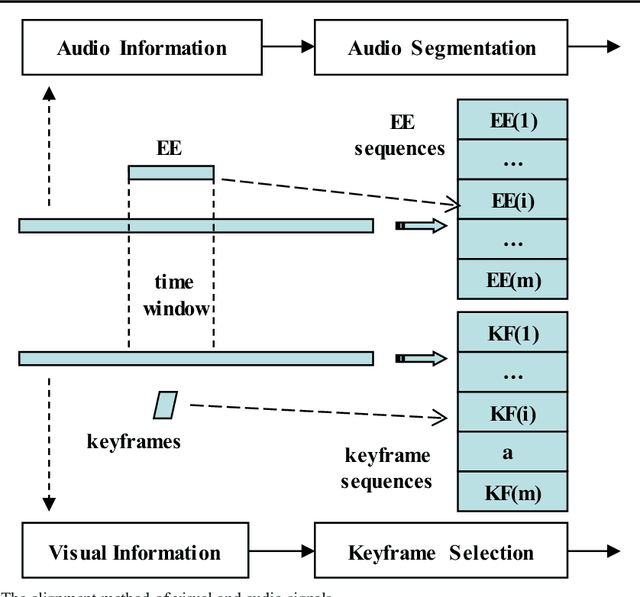
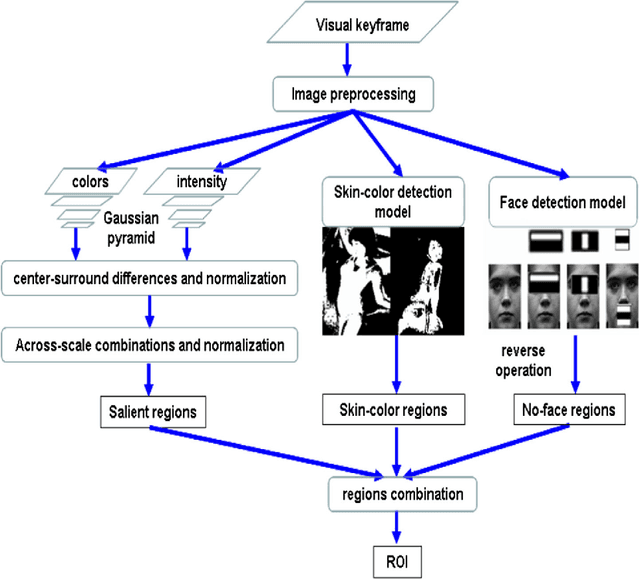
Content-based adult video detection plays an important role in preventing pornography. However, existing methods usually rely on single modality and seldom focus on multi-modality semantics representation. Addressing at this problem, we put forward an approach of analyzing periodicity and saliency for adult video detection. At first, periodic patterns and salient regions are respective-ly analyzed in audio-frames and visual-frames. Next, the multi-modal co-occurrence semantics is described by combining audio periodicity with visual saliency. Moreover, the performance of our approach is evaluated step by step. Experimental results show that our approach obviously outper-forms some state-of-the-art methods.