 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAFA: Instance-aware Feature Aggregation for 3D Object Detection from a Single Image
Paper and Code
Mar 05, 2021
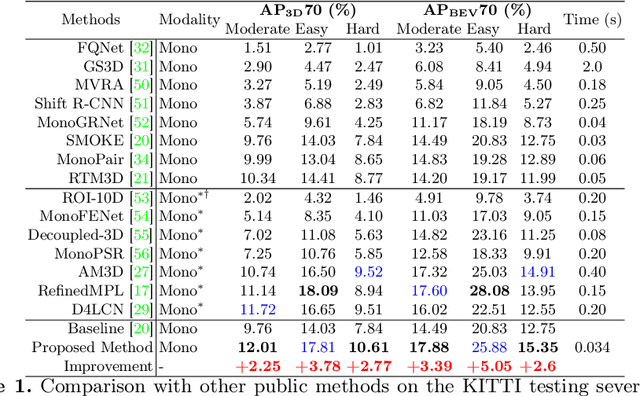
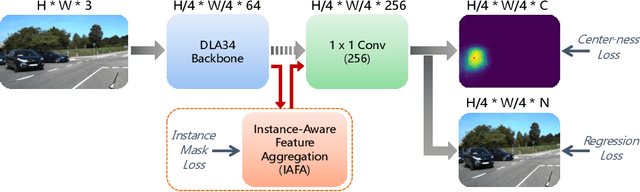
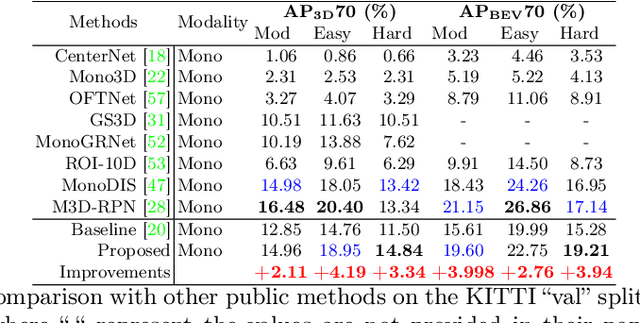
3D object detection from a single image is an important task in Autonomous Driving (AD), where various approaches have been proposed. However, the task is intrinsically ambiguous and challenging as single image depth estimation is already an ill-posed problem. In this paper, we propose an instance-aware approach to aggregate useful information for improving the accuracy of 3D object detection with the following contributions. First, an instance-aware feature aggregation (IAFA) module is proposed to collect local and global features for 3D bounding boxes regression. Second, we empirically find that the spatial attention module can be well learned by taking coarse-level instance annotations as a supervision signal. The proposed module has significantly boosted the performance of the baseline method on both 3D detection and 2D bird-eye's view of vehicle detection among all three categories. Third, our proposed method outperforms all single image-based approaches (even these methods trained with depth as auxiliary inputs) and achieves state-of-the-art 3D detection performance on the KITTI benchmark.