 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Personalized Darts Training: A Data-Driven Framework Based on Skeleton-Based Biomechanical Analysis and Motion Modeling
Apr 02, 2026As sports training becomes more data-driven, traditional dart coaching based mainly on experience and visual observation is increasingly inadequate for high-precision, goal-oriented movements. Although prior studies have highlighted the importance of release parameters, joint motion, and coordination in dart throwing, most quantitative methods still focus on local variables, single-release metrics, or static template matching. These approaches offer limited support for personalized training and often overlook useful movement variability. This paper presents a data-driven dart training assistance system. The system creates a closed-loop framework spanning motion capture, feature modeling, and personalized feedback. Dart-throwing data were collected in markerless conditions using a Kinect 2.0 depth sensor and an optical camera. Eighteen kinematic features were extracted from four biomechanical dimensions: three-link coordination, release velocity, multi-joint angular configuration, and postural stability. Two modules were developed: a personalized optimal throwing trajectory model that combines historical high-quality samples with the minimum jerk criterion, and a motion deviation diagnosis and recommendation model based on z-scores and hierarchical logic. A total of 2,396 throwing samples from professional and non-professional athletes were collected. Results show that the system generates smooth personalized reference trajectories consistent with natural human movement. Case studies indicate that it can detect poor trunk stability, abnormal elbow displacement, and imbalanced velocity control, then provide targeted recommendations. The framework shifts dart evaluation from deviation from a uniform standard to deviation from an individual's optimal control range, improving personalization and interpretability for darts training and other high-precision target sports.
A Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
Two-dimensional Sparse Parallelism for Large Scale Deep Learning Recommendation Model Training
Aug 05, 2025The increasing complexity of deep learning recommendation models (DLRM) has led to a growing need for large-scale distributed systems that can efficiently train vast amounts of data. In DLRM, the sparse embedding table is a crucial component for managing sparse categorical features. Typically, these tables in industrial DLRMs contain trillions of parameters, necessitating model parallelism strategies to address memory constraints. However, as training systems expand with massive GPUs, the traditional fully parallelism strategies for embedding table post significant scalability challenges, including imbalance and straggler issues, intensive lookup communication, and heavy embedding activation memory. To overcome these limitations, we propose a novel two-dimensional sparse parallelism approach. Rather than fully sharding tables across all GPUs, our solution introduces data parallelism on top of model parallelism. This enables efficient all-to-all communication and reduces peak memory consumption. Additionally, we have developed the momentum-scaled row-wise AdaGrad algorithm to mitigate performance losses associated with the shift in training paradigms. Our extensive experiments demonstrate that the proposed approach significantly enhances training efficiency while maintaining model performance parity. It achieves nearly linear training speed scaling up to 4K GPUs, setting a new state-of-the-art benchmark for recommendation model training.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
ALOcc: Adaptive Lifting-based 3D Semantic Occupancy and Cost Volume-based Flow Prediction
Nov 12, 2024Vision-based semantic occupancy and flow prediction plays a crucial role in providing spatiotemporal cues for real-world tasks, such as autonomous driving. Existing methods prioritize higher accuracy to cater to the demands of these tasks. In this work, we strive to improve performance by introducing a series of targeted improvements for 3D semantic occupancy prediction and flow estimation. First, we introduce an occlusion-aware adaptive lifting mechanism with a depth denoising technique to improve the robustness of 2D-to-3D feature transformation and reduce the reliance on depth priors. Second, we strengthen the semantic consistency between 3D features and their original 2D modalities by utilizing shared semantic prototypes to jointly constrain both 2D and 3D features. This is complemented by confidence- and category-based sampling strategies to tackle long-tail challenges in 3D space. To alleviate the feature encoding burden in the joint prediction of semantics and flow, we propose a BEV cost volume-based prediction method that links flow and semantic features through a cost volume and employs a classification-regression supervision scheme to address the varying flow scales in dynamic scenes. Our purely convolutional architecture framework, named ALOcc, achieves an optimal tradeoff between speed and accuracy achieving state-of-the-art results on multiple benchmarks. On Occ3D and training without the camera visible mask, our ALOcc achieves an absolute gain of 2.5\% in terms of RayIoU while operating at a comparable speed compared to the state-of-the-art, using the same input size (256$\times$704) and ResNet-50 backbone. Our method also achieves 2nd place in the CVPR24 Occupancy and Flow Prediction Competition.
AdaOcc: Adaptive Forward View Transformation and Flow Modeling for 3D Occupancy and Flow Prediction
Jul 01, 2024



In this technical report, we present our solution for the Vision-Centric 3D Occupancy and Flow Prediction track in the nuScenes Open-Occ Dataset Challenge at CVPR 2024. Our innovative approach involves a dual-stage framework that enhances 3D occupancy and flow predictions by incorporating adaptive forward view transformation and flow modeling. Initially, we independently train the occupancy model, followed by flow prediction using sequential frame integration. Our method combines regression with classification to address scale variations in different scenes, and leverages predicted flow to warp current voxel features to future frames, guided by future frame ground truth. Experimental results on the nuScenes dataset demonstrate significant improvements in accuracy and robustness, showcasing the effectiveness of our approach in real-world scenarios. Our single model based on Swin-Base ranks second on the public leaderboard, validating the potential of our method in advancing autonomous car perception systems.
A Scalable and Effective Alternative to Graph Transformers
Jun 17, 2024



Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
VCR-Graphormer: A Mini-batch Graph Transformer via Virtual Connections
Mar 24, 2024



Graph transformer has been proven as an effective graph learning method for its adoption of attention mechanism that is capable of capturing expressive representations from complex topological and feature information of graphs. Graph transformer conventionally performs dense attention (or global attention) for every pair of nodes to learn node representation vectors, resulting in quadratic computational costs that are unaffordable for large-scale graph data. Therefore, mini-batch training for graph transformers is a promising direction, but limited samples in each mini-batch can not support effective dense attention to encode informative representations. Facing this bottleneck, (1) we start by assigning each node a token list that is sampled by personalized PageRank (PPR) and then apply standard multi-head self-attention only on this list to compute its node representations. This PPR tokenization method decouples model training from complex graph topological information and makes heavy feature engineering offline and independent, such that mini-batch training of graph transformers is possible by loading each node's token list in batches. We further prove this PPR tokenization is viable as a graph convolution network with a fixed polynomial filter and jumping knowledge. However, only using personalized PageRank may limit information carried by a token list, which could not support different graph inductive biases for model training. To this end, (2) we rewire graphs by introducing multiple types of virtual connections through structure- and content-based super nodes that enable PPR tokenization to encode local and global contexts, long-range interaction, and heterophilous information into each node's token list, and then formalize our Virtual Connection Ranking based Graph Transformer (VCR-Graphormer).
LiDAR-CS Dataset: LiDAR Point Cloud Dataset with Cross-Sensors for 3D Object Detection
Jan 29, 2023LiDAR devices are widely used in autonomous driving scenarios and researches on 3D point cloud achieve remarkable progress over the past years. However, deep learning-based methods heavily rely on the annotation data and often face the domain generalization problem. Unlike 2D images whose domains are usually related to the texture information, the feature extracted from the 3D point cloud is affected by the distribution of the points. Due to the lack of a 3D domain adaptation benchmark, the common practice is to train the model on one benchmark (e.g, Waymo) and evaluate it on another dataset (e.g. KITTI). However, in this setting, there are two types of domain gaps, the scenarios domain, and sensors domain, making the evaluation and analysis complicated and difficult. To handle this situation, we propose LiDAR Dataset with Cross-Sensors (LiDAR-CS Dataset), which contains large-scale annotated LiDAR point cloud under 6 groups of different sensors but with same corresponding scenarios, captured from hybrid realistic LiDAR simulator. As far as we know, LiDAR-CS Dataset is the first dataset focused on the sensor (e.g., the points distribution) domain gaps for 3D object detection in real traffic. Furthermore, we evaluate and analyze the performance with several baseline detectors on the LiDAR-CS benchmark and show its applications.
Multi-Sem Fusion: Multimodal Semantic Fusion for 3D Object Detection
Dec 10, 2022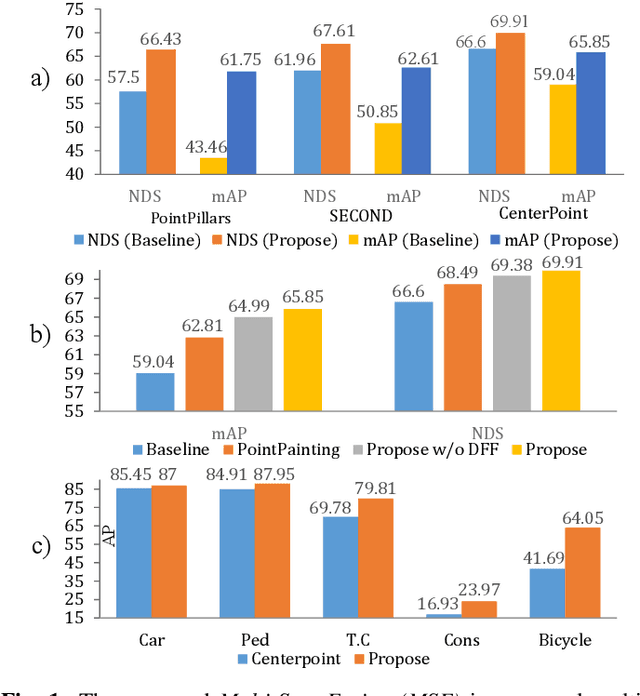
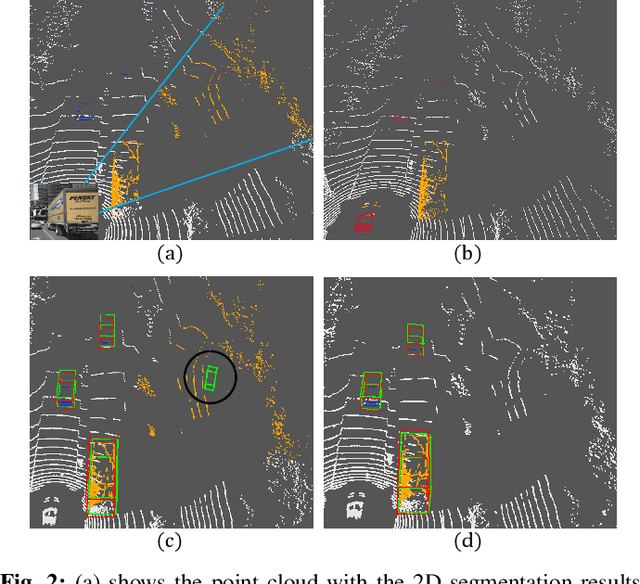


LiDAR-based 3D Object detectors have achieved impressive performances in many benchmarks, however, multisensors fusion-based techniques are promising to further improve the results. PointPainting, as a recently proposed framework, can add the semantic information from the 2D image into the 3D LiDAR point by the painting operation to boost the detection performance. However, due to the limited resolution of 2D feature maps, severe boundary-blurring effect happens during re-projection of 2D semantic segmentation into the 3D point clouds. To well handle this limitation, a general multimodal fusion framework MSF has been proposed to fuse the semantic information from both the 2D image and 3D points scene parsing results. Specifically, MSF includes three main modules. First, SOTA off-the-shelf 2D/3D semantic segmentation approaches are employed to generate the parsing results for 2D images and 3D point clouds. The 2D semantic information is further re-projected into the 3D point clouds with calibrated parameters. To handle the misalignment between the 2D and 3D parsing results, an AAF module is proposed to fuse them by learning an adaptive fusion score. Then the point cloud with the fused semantic label is sent to the following 3D object detectors. Furthermore, we propose a DFF module to aggregate deep features in different levels to boost the final detection performance. The effectiveness of the framework has been verified on two public large-scale 3D object detection benchmarks by comparing with different baselines. The experimental results show that the proposed fusion strategies can significantly improve the detection performance compared to the methods using only point clouds and the methods using only 2D semantic information. Most importantly, the proposed approach significantly outperforms other approaches and sets new SOTA results on the nuScenes testing benchmark.