 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Web to Pixels: Bringing Agentic Search into Visual Perception
May 12, 2026Visual perception connects high-level semantic understanding to pixel-level perception, but most existing settings assume that the decisive evidence for identifying a target is already in the image or frozen model knowledge. We study a more practical yet harder open-world case where a visible object must first be resolved from external facts, recent events, long-tail entities, or multi-hop relations before it can be localized. We formalize this challenge as Perception Deep Research and introduce WebEye, an object-anchored benchmark with verifiable evidence, knowledge-intensive queries, precise box/mask annotations, and three task views: Search-based Grounding, Search-based Segmentation, and Search-based VQA. WebEyes contains 120 images, 473 annotated object instances, 645 unique QA pairs, and 1,927 task samples. We further propose Pixel-Searcher, an agentic search-to-pixel workflow that resolves hidden target identities and binds them to boxes, masks, or grounded answers. Experiments show that Pixel-Searcher achieves the strongest open-source performance across all three task views, while failures mainly arise from evidence acquisition, identity resolution, and visual instance binding.
QASA: Quality-Guided K-Adaptive Slot Attention for Unsupervised Object-Centric Learning
Jan 19, 2026Slot Attention, an approach that binds different objects in a scene to a set of "slots", has become a leading method in unsupervised object-centric learning. Most methods assume a fixed slot count K, and to better accommodate the dynamic nature of object cardinality, a few works have explored K-adaptive variants. However, existing K-adaptive methods still suffer from two limitations. First, they do not explicitly constrain slot-binding quality, so low-quality slots lead to ambiguous feature attribution. Second, adding a slot-count penalty to the reconstruction objective creates conflicting optimization goals between reducing the number of active slots and maintaining reconstruction fidelity. As a result, they still lag significantly behind strong K-fixed baselines. To address these challenges, we propose Quality-Guided K-Adaptive Slot Attention (QASA). First, we decouple slot selection from reconstruction, eliminating the mutual constraints between the two objectives. Then, we propose an unsupervised Slot-Quality metric to assess per-slot quality, providing a principled signal for fine-grained slot--object binding. Based on this metric, we design a Quality-Guided Slot Selection scheme that dynamically selects a subset of high-quality slots and feeds them into our newly designed gated decoder for reconstruction during training. At inference, token-wise competition on slot attention yields a K-adaptive outcome. Experiments show that QASA substantially outperforms existing K-adaptive methods on both real and synthetic datasets. Moreover, on real-world datasets QASA surpasses K-fixed methods.
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Jun 05, 2025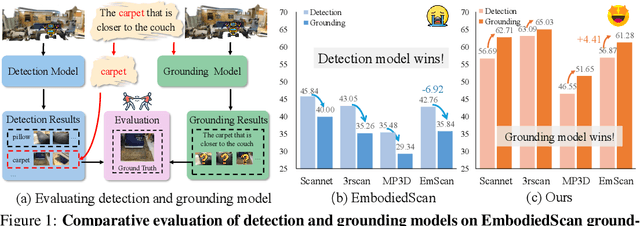
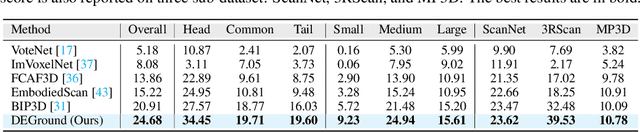
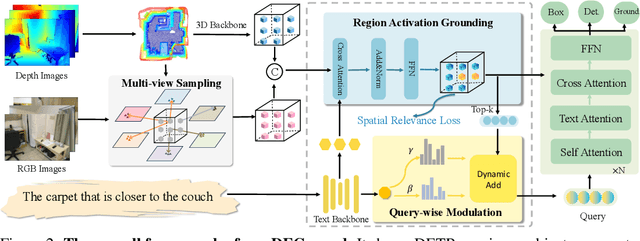
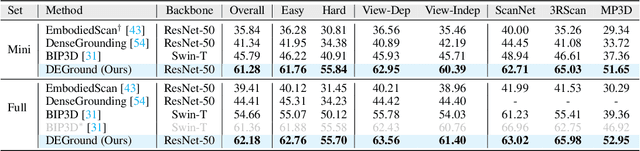
Embodied 3D grounding aims to localize target objects described in human instructions from ego-centric viewpoint. Most methods typically follow a two-stage paradigm where a trained 3D detector's optimized backbone parameters are used to initialize a grounding model. In this study, we explore a fundamental question: Does embodied 3D grounding benefit enough from detection? To answer this question, we assess the grounding performance of detection models using predicted boxes filtered by the target category. Surprisingly, these detection models without any instruction-specific training outperform the grounding models explicitly trained with language instructions. This indicates that even category-level embodied 3D grounding may not be well resolved, let alone more fine-grained context-aware grounding. Motivated by this finding, we propose DEGround, which shares DETR queries as object representation for both DEtection and Grounding and enables the grounding to benefit from basic category classification and box detection. Based on this framework, we further introduce a regional activation grounding module that highlights instruction-related regions and a query-wise modulation module that incorporates sentence-level semantic into the query representation, strengthening the context-aware understanding of language instructions. Remarkably, DEGround outperforms state-of-the-art model BIP3D by 7.52\% at overall accuracy on the EmbodiedScan validation set. The source code will be publicly available at https://github.com/zyn213/DEGround.
Frequency Feature Fusion Graph Network For Depression Diagnosis Via fNIRS
Apr 29, 2025Data-driven approaches for depression diagnosis have emerged as a significant research focus in neuromedicine, driven by the development of relevant datasets. Recently, graph neural network (GNN)-based models have gained widespread adoption due to their ability to capture brain channel functional connectivity from both spatial and temporal perspectives. However, their effectiveness is hindered by the absence of a robust temporal biomarker. In this paper, we introduce a novel and effective biomarker for depression diagnosis by leveraging the discrete Fourier transform (DFT) and propose a customized graph network architecture based on Temporal Graph Convolutional Network (TGCN). Our model was trained on a dataset comprising 1,086 subjects, which is over 10 times larger than previous datasets in the field of depression diagnosis. Furthermore, to align with medical requirements, we performed propensity score matching (PSM) to create a refined subset, referred to as the PSM dataset. Experimental results demonstrate that incorporating our newly designed biomarker enhances the representation of temporal characteristics in brain channels, leading to improved F1 scores in both the real-world dataset and the PSM dataset. This advancement has the potential to contribute to the development of more effective depression diagnostic tools. In addition, we used SHapley Additive exPlaination (SHAP) to validate the interpretability of our model, ensuring its practical applicability in medical settings.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
Towards High-Fidelity 3D Portrait Generation with Rich Details by Cross-View Prior-Aware Diffusion
Nov 15, 2024Recent diffusion-based Single-image 3D portrait generation methods typically employ 2D diffusion models to provide multi-view knowledge, which is then distilled into 3D representations. However, these methods usually struggle to produce high-fidelity 3D models, frequently yielding excessively blurred textures. We attribute this issue to the insufficient consideration of cross-view consistency during the diffusion process, resulting in significant disparities between different views and ultimately leading to blurred 3D representations. In this paper, we address this issue by comprehensively exploiting multi-view priors in both the conditioning and diffusion procedures to produce consistent, detail-rich portraits. From the conditioning standpoint, we propose a Hybrid Priors Diffsion model, which explicitly and implicitly incorporates multi-view priors as conditions to enhance the status consistency of the generated multi-view portraits. From the diffusion perspective, considering the significant impact of the diffusion noise distribution on detailed texture generation, we propose a Multi-View Noise Resamplig Strategy integrated within the optimization process leveraging cross-view priors to enhance representation consistency. Extensive experiments demonstrate that our method can produce 3D portraits with accurate geometry and rich details from a single image. The project page is at \url{https://haoran-wei.github.io/Portrait-Diffusion}.
Bootstrapping Referring Multi-Object Tracking
Jun 07, 2024



Referring multi-object tracking (RMOT) aims at detecting and tracking multiple objects following human instruction represented by a natural language expression. Existing RMOT benchmarks are usually formulated through manual annotations, integrated with static regulations. This approach results in a dearth of notable diversity and a constrained scope of implementation. In this work, our key idea is to bootstrap the task of referring multi-object tracking by introducing discriminative language words as much as possible. In specific, we first develop Refer-KITTI into a large-scale dataset, named Refer-KITTI-V2. It starts with 2,719 manual annotations, addressing the issue of class imbalance and introducing more keywords to make it closer to real-world scenarios compared to Refer-KITTI. They are further expanded to a total of 9,758 annotations by prompting large language models, which create 617 different words, surpassing previous RMOT benchmarks. In addition, the end-to-end framework in RMOT is also bootstrapped by a simple yet elegant temporal advancement strategy, which achieves better performance than previous approaches. The source code and dataset is available at https://github.com/zyn213/TempRMOT.
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
Referring Multi-Object Tracking
Mar 11, 2023



Existing referring understanding tasks tend to involve the detection of a single text-referred object. In this paper, we propose a new and general referring understanding task, termed referring multi-object tracking (RMOT). Its core idea is to employ a language expression as a semantic cue to guide the prediction of multi-object tracking. To the best of our knowledge, it is the first work to achieve an arbitrary number of referent object predictions in videos. To push forward RMOT, we construct one benchmark with scalable expressions based on KITTI, named Refer-KITTI. Specifically, it provides 18 videos with 818 expressions, and each expression in a video is annotated with an average of 10.7 objects. Further, we develop a transformer-based architecture TransRMOT to tackle the new task in an online manner, which achieves impressive detection performance and outperforms other counterparts. The dataset and code will be available at https://github.com/wudongming97/RMOT.
Generalized Few-Shot 3D Object Detection of LiDAR Point Cloud for Autonomous Driving
Feb 08, 2023Recent years have witnessed huge successes in 3D object detection to recognize common objects for autonomous driving (e.g., vehicles and pedestrians). However, most methods rely heavily on a large amount of well-labeled training data. This limits their capability of detecting rare fine-grained objects (e.g., police cars and ambulances), which is important for special cases, such as emergency rescue, and so on. To achieve simultaneous detection for both common and rare objects, we propose a novel task, called generalized few-shot 3D object detection, where we have a large amount of training data for common (base) objects, but only a few data for rare (novel) classes. Specifically, we analyze in-depth differences between images and point clouds, and then present a practical principle for the few-shot setting in the 3D LiDAR dataset. To solve this task, we propose a simple and effective detection framework, including (1) an incremental fine-tuning method to extend existing 3D detection models to recognize both common and rare objects, and (2) a sample adaptive balance loss to alleviate the issue of long-tailed data distribution in autonomous driving scenarios. On the nuScenes dataset, we conduct sufficient experiments to demonstrate that our approach can successfully detect the rare (novel) classes that contain only a few training data, while also maintaining the detection accuracy of common objects.