 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Clustering-Based Pseudo-Labeling for Unsupervised Meta-Learning
Paper and Code
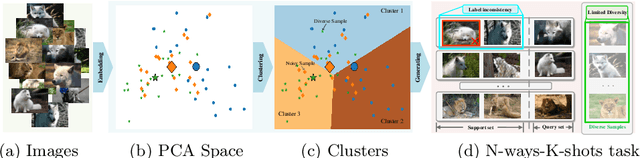
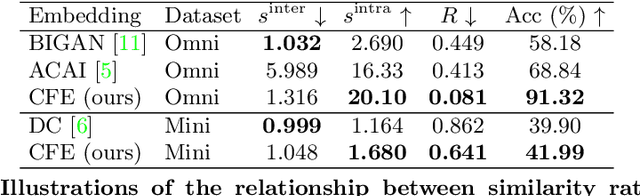
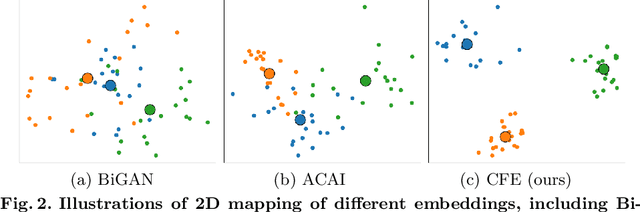
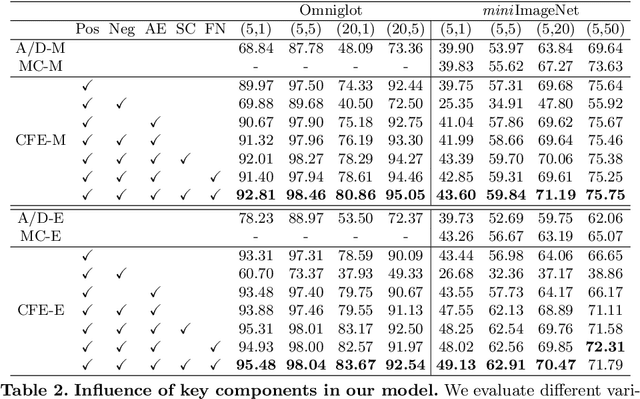
The pioneering method for unsupervised meta-learning, CACTUs, is a clustering-based approach with pseudo-labeling. This approach is model-agnostic and can be combined with supervised algorithms to learn from unlabeled data. However, it often suffers from label inconsistency or limited diversity, which leads to poor performance. In this work, we prove that the core reason for this is lack of a clustering-friendly property in the embedding space. We address this by minimizing the inter- to intra-class similarity ratio to provide clustering-friendly embedding features, and validate our approach through comprehensive experiments. Note that, despite only utilizing a simple clustering algorithm (k-means) in our embedding space to obtain the pseudo-labels, we achieve significant improvement. Moreover, we adopt a progressive evaluation mechanism to obtain more diverse samples in order to further alleviate the limited diversity problem. Finally, our approach is also model-agnostic and can easily be integrated into existing supervised methods. To demonstrate its generalization ability, we integrate it into two representative algorithms: MAML and EP. The results on three main few-shot benchmarks clearly show that the proposed method achieves significant improvement compared to state-of-the-art models. Notably, our approach also outperforms the corresponding supervised method in two tasks.