 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025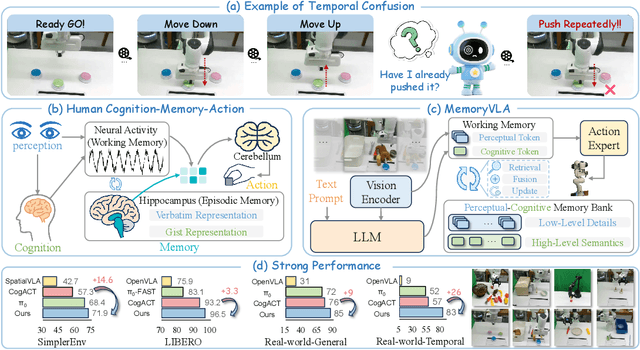
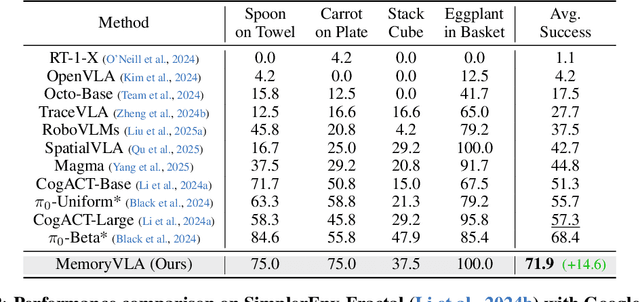
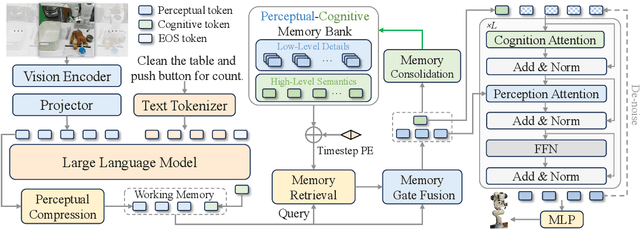
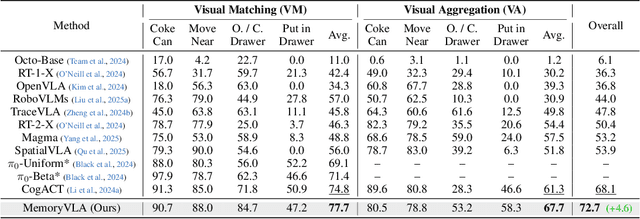
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
GeoVLA: Empowering 3D Representations in Vision-Language-Action Models
Aug 12, 2025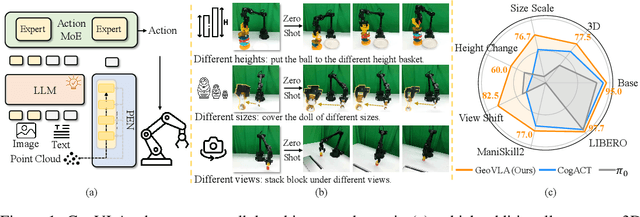
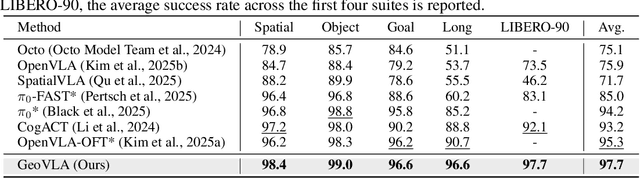
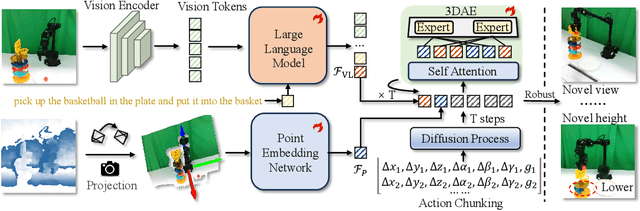
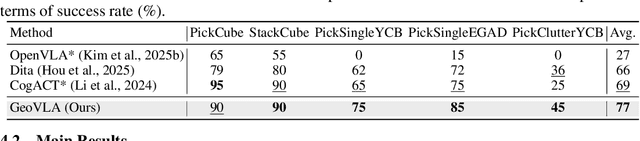
Vision-Language-Action (VLA) models have emerged as a promising approach for enabling robots to follow language instructions and predict corresponding actions.However, current VLA models mainly rely on 2D visual inputs, neglecting the rich geometric information in the 3D physical world, which limits their spatial awareness and adaptability. In this paper, we present GeoVLA, a novel VLA framework that effectively integrates 3D information to advance robotic manipulation. It uses a vision-language model (VLM) to process images and language instructions,extracting fused vision-language embeddings. In parallel, it converts depth maps into point clouds and employs a customized point encoder, called Point Embedding Network, to generate 3D geometric embeddings independently. These produced embeddings are then concatenated and processed by our proposed spatial-aware action expert, called 3D-enhanced Action Expert, which combines information from different sensor modalities to produce precise action sequences. Through extensive experiments in both simulation and real-world environments, GeoVLA demonstrates superior performance and robustness. It achieves state-of-the-art results in the LIBERO and ManiSkill2 simulation benchmarks and shows remarkable robustness in real-world tasks requiring height adaptability, scale awareness and viewpoint invariance.
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
Grounding Beyond Detection: Enhancing Contextual Understanding in Embodied 3D Grounding
Jun 05, 2025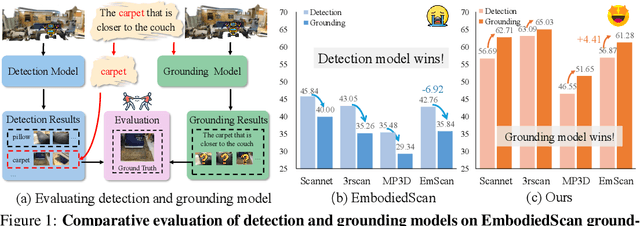
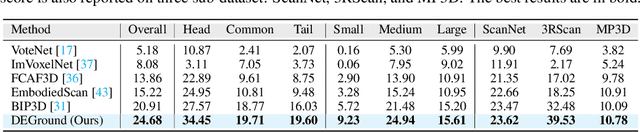
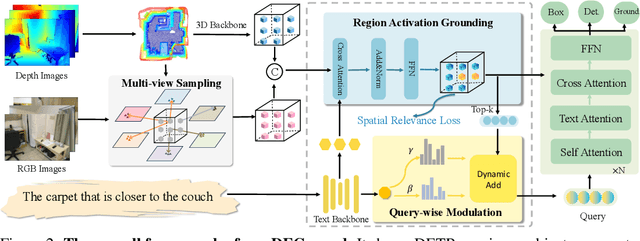
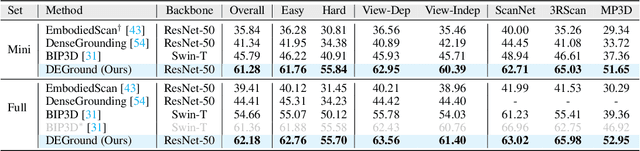
Embodied 3D grounding aims to localize target objects described in human instructions from ego-centric viewpoint. Most methods typically follow a two-stage paradigm where a trained 3D detector's optimized backbone parameters are used to initialize a grounding model. In this study, we explore a fundamental question: Does embodied 3D grounding benefit enough from detection? To answer this question, we assess the grounding performance of detection models using predicted boxes filtered by the target category. Surprisingly, these detection models without any instruction-specific training outperform the grounding models explicitly trained with language instructions. This indicates that even category-level embodied 3D grounding may not be well resolved, let alone more fine-grained context-aware grounding. Motivated by this finding, we propose DEGround, which shares DETR queries as object representation for both DEtection and Grounding and enables the grounding to benefit from basic category classification and box detection. Based on this framework, we further introduce a regional activation grounding module that highlights instruction-related regions and a query-wise modulation module that incorporates sentence-level semantic into the query representation, strengthening the context-aware understanding of language instructions. Remarkably, DEGround outperforms state-of-the-art model BIP3D by 7.52\% at overall accuracy on the EmbodiedScan validation set. The source code will be publicly available at https://github.com/zyn213/DEGround.
PADriver: Towards Personalized Autonomous Driving
May 08, 2025In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
Continual LLaVA: Continual Instruction Tuning in Large Vision-Language Models
Nov 04, 2024



Instruction tuning constitutes a prevalent technique for tailoring Large Vision Language Models (LVLMs) to meet individual task requirements. To date, most of the existing approaches are confined to single-task adaptation, whereas the requirements in real-world scenarios are inherently varied and continually evolving. Thus an ideal LVLM should sustain continual instruction tuning in the face of stream-task distributions (i.e., different domains, emerging capabilities, and new datasets) while minimizing the forgetting of previously acquired knowledge. To achieve this, we propose a new benchmark for COntinuAl inStruction Tuning on LVLMs (COAST), which encompasses the aforementioned domain-incremental, capability-incremental, and dataset-incremental configurations. In terms of methodology, we propose Continual LLaVA, a rehearsal-free method tailored for continual instruction tuning in LVLMs. To circumvent the additional overhead associated with experience replay, we freeze LVLMs and construct the dual increment embeddings for each input instruction to facilitate parameter-efficient tuning. Specifically, the increment embeddings can be decomposed into two principal components: 1) intrinsic increment embeddings to encode task-specific characteristics. To achieve this, we set up a low-rank pool containing candidate embeddings, from which we select the relevant ones based on their similarity with the user instructions; 2) contextual increment embeddings to investigate the inter-dependencies across tasks. In this regard, the low-rank embeddings chosen in the previous tasks are aggregated via learnable weighted sum to provide complementary hints. Extensive experiments indicate that the proposed Continual LLaVA outperforms previous methods by significantly reducing the forgetting during the continual instruction tuning process.
Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
May 28, 2024Rapid advancements in Autonomous Driving (AD) tasks turned a significant shift toward end-to-end fashion, particularly in the utilization of vision-language models (VLMs) that integrate robust logical reasoning and cognitive abilities to enable comprehensive end-to-end planning. However, these VLM-based approaches tend to integrate 2D vision tokenizers and a large language model (LLM) for ego-car planning, which lack 3D geometric priors as a cornerstone of reliable planning. Naturally, this observation raises a critical concern: Can a 2D-tokenized LLM accurately perceive the 3D environment? Our evaluation of current VLM-based methods across 3D object detection, vectorized map construction, and environmental caption suggests that the answer is, unfortunately, NO. In other words, 2D-tokenized LLM fails to provide reliable autonomous driving. In response, we introduce DETR-style 3D perceptrons as 3D tokenizers, which connect LLM with a one-layer linear projector. This simple yet elegant strategy, termed Atlas, harnesses the inherent priors of the 3D physical world, enabling it to simultaneously process high-resolution multi-view images and employ spatiotemporal modeling. Despite its simplicity, Atlas demonstrates superior performance in both 3D detection and ego planning tasks on nuScenes dataset, proving that 3D-tokenized LLM is the key to reliable autonomous driving. The code and datasets will be released.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024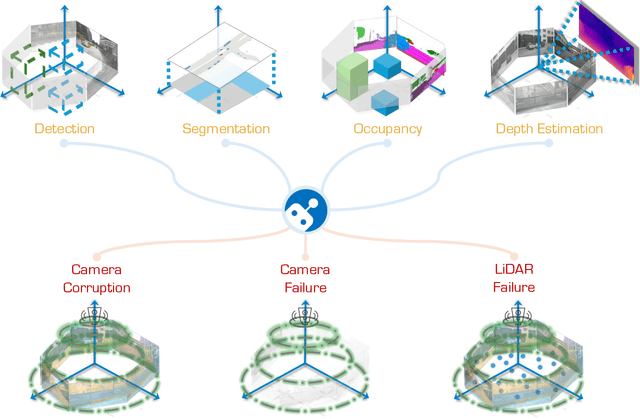


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
SubjectDrive: Scaling Generative Data in Autonomous Driving via Subject Control
Mar 28, 2024



Autonomous driving progress relies on large-scale annotated datasets. In this work, we explore the potential of generative models to produce vast quantities of freely-labeled data for autonomous driving applications and present SubjectDrive, the first model proven to scale generative data production in a way that could continuously improve autonomous driving applications. We investigate the impact of scaling up the quantity of generative data on the performance of downstream perception models and find that enhancing data diversity plays a crucial role in effectively scaling generative data production. Therefore, we have developed a novel model equipped with a subject control mechanism, which allows the generative model to leverage diverse external data sources for producing varied and useful data. Extensive evaluations confirm SubjectDrive's efficacy in generating scalable autonomous driving training data, marking a significant step toward revolutionizing data production methods in this field.