 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: Advantage Reward Modeling for Long-Horizon Manipulation
Apr 03, 2026Long-horizon robotic manipulation remains challenging for reinforcement learning (RL) because sparse rewards provide limited guidance for credit assignment. Practical policy improvement thus relies on richer intermediate supervision, such as dense progress rewards, which are costly to obtain and ill-suited to non-monotonic behaviors such as backtracking and recovery. To address this, we propose Advantage Reward Modeling (ARM), a framework that shifts from hard-to-quantify absolute progress to estimating relative advantage. We introduce a cost-effective tri-state labeling strategy -- Progressive, Regressive, and Stagnant -- that reduces human cognitive overhead while ensuring high cross-annotator consistency. By training on these intuitive signals, ARM enables automated progress annotation for both complete demonstrations and fragmented DAgger-style data. Integrating ARM into an offline RL pipeline allows for adaptive action-reward reweighting, effectively filtering suboptimal samples. Our approach achieves a 99.4% success rate on a challenging long-horizon towel-folding task, demonstrating improved stability and data efficiency over current VLA baselines with near-zero human intervention during policy training.
BFA++: Hierarchical Best-Feature-Aware Token Prune for Multi-View Vision Language Action Model
Feb 24, 2026Vision-Language-Action (VLA) models have achieved significant breakthroughs by leveraging Large Vision Language Models (VLMs) to jointly interpret instructions and visual inputs. However, the substantial increase in visual tokens, particularly from multi-view inputs, poses serious challenges to real-time robotic manipulation. Existing acceleration techniques for VLMs, such as token pruning, often result in degraded performance when directly applied to VLA models, as they overlook the relationships between different views and fail to account for the dynamic and task-specific characteristics of robotic operation. To address this, we propose BFA++, a dynamic token pruning framework designed specifically for VLA models. BFA++ introduces a hierarchical pruning strategy guided by two-level importance predictors: an intra-view predictor highlights task-relevant regions within each image to suppress spatial noise, while an inter-view predictor identifies critical camera views throughout different manipulation phases to reduce cross-view redundancy. This design enables efficient token selection while preserving essential visual cues, resulting in improved computational efficiency and higher manipulation success rates. Evaluations on the RoboTwin benchmark and real-world robotic tasks demonstrate that BFA++ consistently outperforms existing methods. BFA++ improves the success rate by about 10% on both the π0 and RDT models, achieving speedup of 1.8X and 1.5X, respectively. Our results highlight that context-sensitive and task-aware token pruning serves as a more effective strategy than full visual processing, enabling faster inference and improved manipulation accuracy in real-world robotic systems.
See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
PADriver: Towards Personalized Autonomous Driving
May 08, 2025In this paper, we propose PADriver, a novel closed-loop framework for personalized autonomous driving (PAD). Built upon Multi-modal Large Language Model (MLLM), PADriver takes streaming frames and personalized textual prompts as inputs. It autoaggressively performs scene understanding, danger level estimation and action decision. The predicted danger level reflects the risk of the potential action and provides an explicit reference for the final action, which corresponds to the preset personalized prompt. Moreover, we construct a closed-loop benchmark named PAD-Highway based on Highway-Env simulator to comprehensively evaluate the decision performance under traffic rules. The dataset contains 250 hours videos with high-quality annotation to facilitate the development of PAD behavior analysis. Experimental results on the constructed benchmark show that PADriver outperforms state-of-the-art approaches on different evaluation metrics, and enables various driving modes.
Multi-GraspLLM: A Multimodal LLM for Multi-Hand Semantic Guided Grasp Generation
Dec 11, 2024


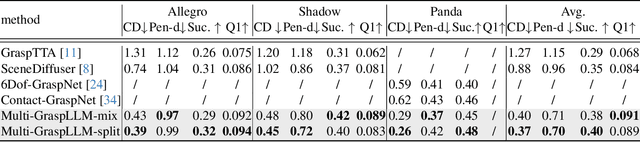
Multi-hand semantic grasp generation aims to generate feasible and semantically appropriate grasp poses for different robotic hands based on natural language instructions. Although the task is highly valuable, due to the lack of multi-hand grasp datasets with fine-grained contact description between robotic hands and objects, it is still a long-standing difficult task. In this paper, we present Multi-GraspSet, the first large-scale multi-hand grasp dataset with automatically contact annotations. Based on Multi-GraspSet, we propose Multi-GraspLLM, a unified language-guided grasp generation framework. It leverages large language models (LLM) to handle variable-length sequences, generating grasp poses for diverse robotic hands in a single unified architecture. Multi-GraspLLM first aligns the encoded point cloud features and text features into a unified semantic space. It then generates grasp bin tokens which are subsequently converted into grasp pose for each robotic hand via hand-aware linear mapping. The experimental results demonstrate that our approach significantly outperforms existing methods on Multi-GraspSet. More information can be found on our project page https://multi-graspllm.github.io.
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024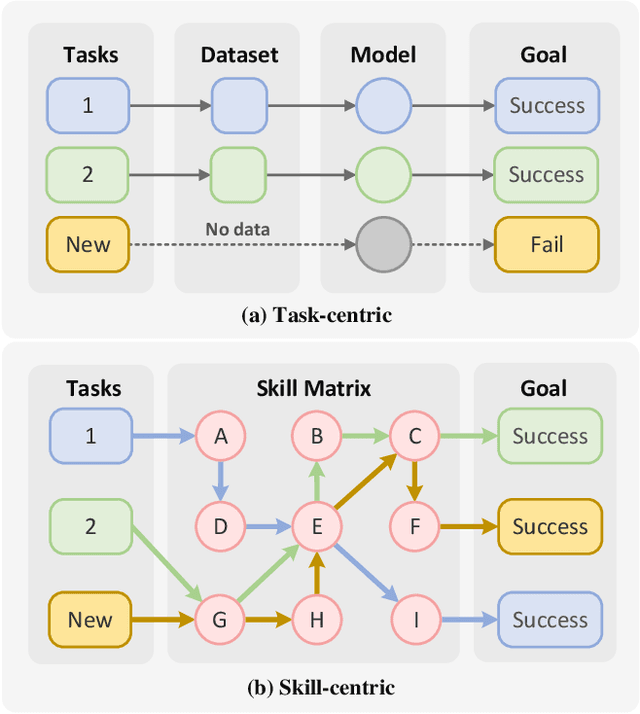

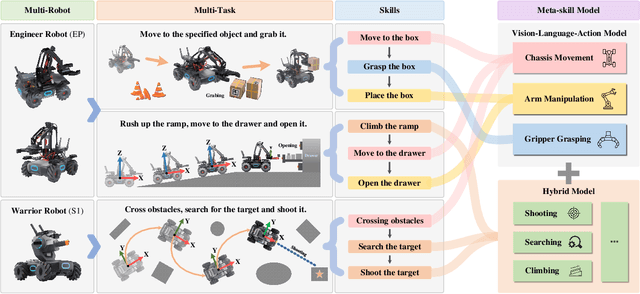

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
SegGrasp: Zero-Shot Task-Oriented Grasping via Semantic and Geometric Guided Segmentation
Oct 11, 2024



Task-oriented grasping, which involves grasping specific parts of objects based on their functions, is crucial for developing advanced robotic systems capable of performing complex tasks in dynamic environments. In this paper, we propose a training-free framework that incorporates both semantic and geometric priors for zero-shot task-oriented grasp generation. The proposed framework, SegGrasp, first leverages the vision-language models like GLIP for coarse segmentation. It then uses detailed geometric information from convex decomposition to improve segmentation quality through a fusion policy named GeoFusion. An effective grasp pose can be generated by a grasping network with improved segmentation. We conducted the experiments on both segmentation benchmark and real-world robot grasping. The experimental results show that SegGrasp surpasses the baseline by more than 15\% in grasp and segmentation performance.
Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
May 28, 2024Rapid advancements in Autonomous Driving (AD) tasks turned a significant shift toward end-to-end fashion, particularly in the utilization of vision-language models (VLMs) that integrate robust logical reasoning and cognitive abilities to enable comprehensive end-to-end planning. However, these VLM-based approaches tend to integrate 2D vision tokenizers and a large language model (LLM) for ego-car planning, which lack 3D geometric priors as a cornerstone of reliable planning. Naturally, this observation raises a critical concern: Can a 2D-tokenized LLM accurately perceive the 3D environment? Our evaluation of current VLM-based methods across 3D object detection, vectorized map construction, and environmental caption suggests that the answer is, unfortunately, NO. In other words, 2D-tokenized LLM fails to provide reliable autonomous driving. In response, we introduce DETR-style 3D perceptrons as 3D tokenizers, which connect LLM with a one-layer linear projector. This simple yet elegant strategy, termed Atlas, harnesses the inherent priors of the 3D physical world, enabling it to simultaneously process high-resolution multi-view images and employ spatiotemporal modeling. Despite its simplicity, Atlas demonstrates superior performance in both 3D detection and ego planning tasks on nuScenes dataset, proving that 3D-tokenized LLM is the key to reliable autonomous driving. The code and datasets will be released.
SubjectDrive: Scaling Generative Data in Autonomous Driving via Subject Control
Mar 28, 2024



Autonomous driving progress relies on large-scale annotated datasets. In this work, we explore the potential of generative models to produce vast quantities of freely-labeled data for autonomous driving applications and present SubjectDrive, the first model proven to scale generative data production in a way that could continuously improve autonomous driving applications. We investigate the impact of scaling up the quantity of generative data on the performance of downstream perception models and find that enhancing data diversity plays a crucial role in effectively scaling generative data production. Therefore, we have developed a novel model equipped with a subject control mechanism, which allows the generative model to leverage diverse external data sources for producing varied and useful data. Extensive evaluations confirm SubjectDrive's efficacy in generating scalable autonomous driving training data, marking a significant step toward revolutionizing data production methods in this field.
PillarNeSt: Embracing Backbone Scaling and Pretraining for Pillar-based 3D Object Detection
Nov 29, 2023This paper shows the effectiveness of 2D backbone scaling and pretraining for pillar-based 3D object detectors. Pillar-based methods mainly employ randomly initialized 2D convolution neural network (ConvNet) for feature extraction and fail to enjoy the benefits from the backbone scaling and pretraining in the image domain. To show the scaling-up capacity in point clouds, we introduce the dense ConvNet pretrained on large-scale image datasets (e.g., ImageNet) as the 2D backbone of pillar-based detectors. The ConvNets are adaptively designed based on the model size according to the specific features of point clouds, such as sparsity and irregularity. Equipped with the pretrained ConvNets, our proposed pillar-based detector, termed PillarNeSt, outperforms the existing 3D object detectors by a large margin on the nuScenes and Argoversev2 datasets. Our code shall be released upon acceptance.