 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Thought, Watermarking the Answer: A Principle Semantic Guided Watermark for Large Reasoning Models
Jan 08, 2026Reasoning Large Language Models (RLLMs) excelling in complex tasks present unique challenges for digital watermarking, as existing methods often disrupt logical coherence or incur high computational costs. Token-based watermarking techniques can corrupt the reasoning flow by applying pseudo-random biases, while semantic-aware approaches improve quality but introduce significant latency or require auxiliary models. This paper introduces ReasonMark, a novel watermarking framework specifically designed for reasoning-intensive LLMs. Our approach decouples generation into an undisturbed Thinking Phase and a watermarked Answering Phase. We propose a Criticality Score to identify semantically pivotal tokens from the reasoning trace, which are distilled into a Principal Semantic Vector (PSV). The PSV then guides a semantically-adaptive mechanism that modulates watermark strength based on token-PSV alignment, ensuring robustness without compromising logical integrity. Extensive experiments show ReasonMark surpasses state-of-the-art methods by reducing text Perplexity by 0.35, increasing translation BLEU score by 0.164, and raising mathematical accuracy by 0.67 points. These advancements are achieved alongside a 0.34% higher watermark detection AUC and stronger robustness to attacks, all with a negligible increase in latency. This work enables the traceable and trustworthy deployment of reasoning LLMs in real-world applications.
Vision-Language Introspection: Mitigating Overconfident Hallucinations in MLLMs via Interpretable Bi-Causal Steering
Jan 08, 2026Object hallucination critically undermines the reliability of Multimodal Large Language Models, often stemming from a fundamental failure in cognitive introspection, where models blindly trust linguistic priors over specific visual evidence. Existing mitigations remain limited: contrastive decoding approaches operate superficially without rectifying internal semantic misalignments, while current latent steering methods rely on static vectors that lack instance-specific precision. We introduce Vision-Language Introspection (VLI), a training-free inference framework that simulates a metacognitive self-correction process. VLI first performs Attributive Introspection to diagnose hallucination risks via probabilistic conflict detection and localize the causal visual anchors. It then employs Interpretable Bi-Causal Steering to actively modulate the inference process, dynamically isolating visual evidence from background noise while neutralizing blind confidence through adaptive calibration. VLI achieves state-of-the-art performance on advanced models, reducing object hallucination rates by 12.67% on MMHal-Bench and improving accuracy by 5.8% on POPE.
RoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024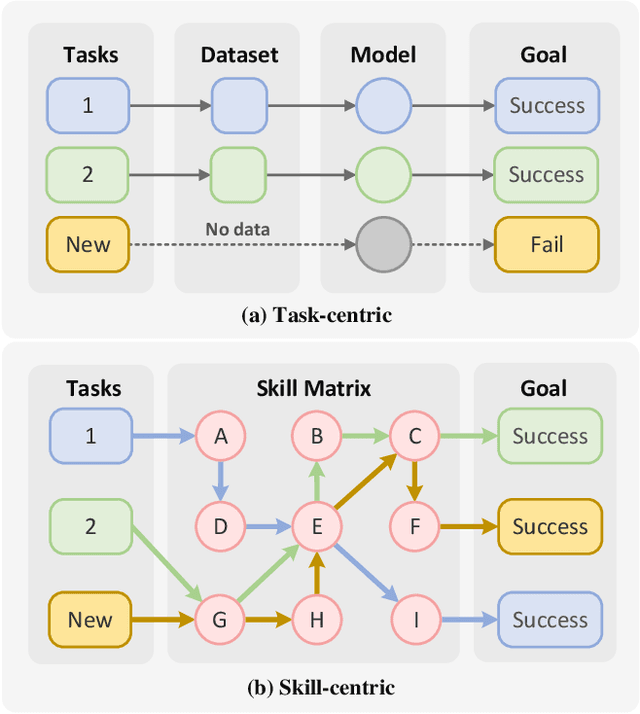

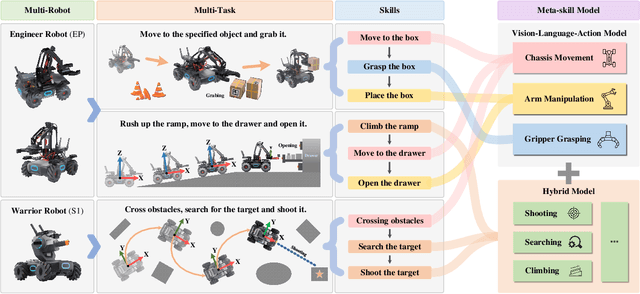

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
Make Your Home Safe: Time-aware Unsupervised User Behavior Anomaly Detection in Smart Homes via Loss-guided Mask
Jun 18, 2024



Smart homes, powered by the Internet of Things, offer great convenience but also pose security concerns due to abnormal behaviors, such as improper operations of users and potential attacks from malicious attackers. Several behavior modeling methods have been proposed to identify abnormal behaviors and mitigate potential risks. However, their performance often falls short because they do not effectively learn less frequent behaviors, consider temporal context, or account for the impact of noise in human behaviors. In this paper, we propose SmartGuard, an autoencoder-based unsupervised user behavior anomaly detection framework. First, we design a Loss-guided Dynamic Mask Strategy (LDMS) to encourage the model to learn less frequent behaviors, which are often overlooked during learning. Second, we propose a Three-level Time-aware Position Embedding (TTPE) to incorporate temporal information into positional embedding to detect temporal context anomaly. Third, we propose a Noise-aware Weighted Reconstruction Loss (NWRL) that assigns different weights for routine behaviors and noise behaviors to mitigate the interference of noise behaviors during inference. Comprehensive experiments on three datasets with ten types of anomaly behaviors demonstrates that SmartGuard consistently outperforms state-of-the-art baselines and also offers highly interpretable results.
RFormer: Transformer-based Generative Adversarial Network for Real Fundus Image Restoration on A New Clinical Benchmark
Jan 03, 2022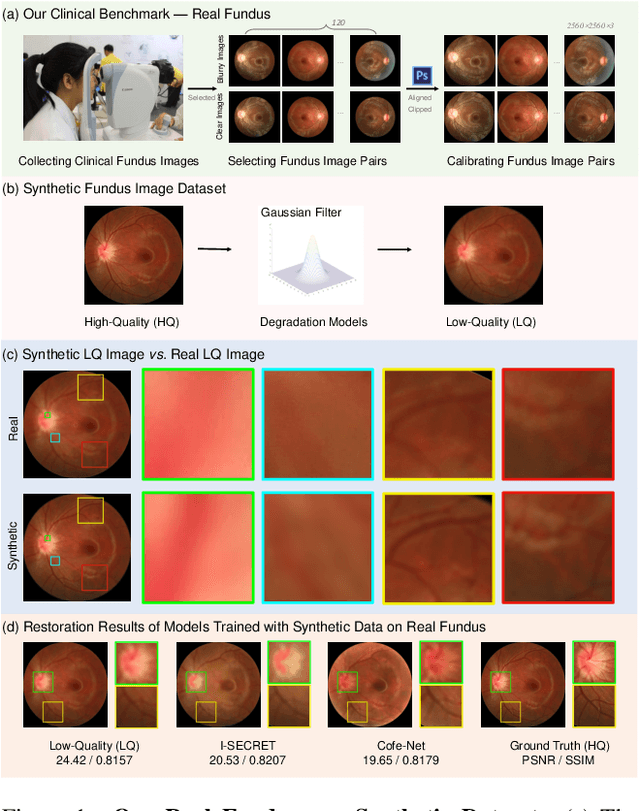

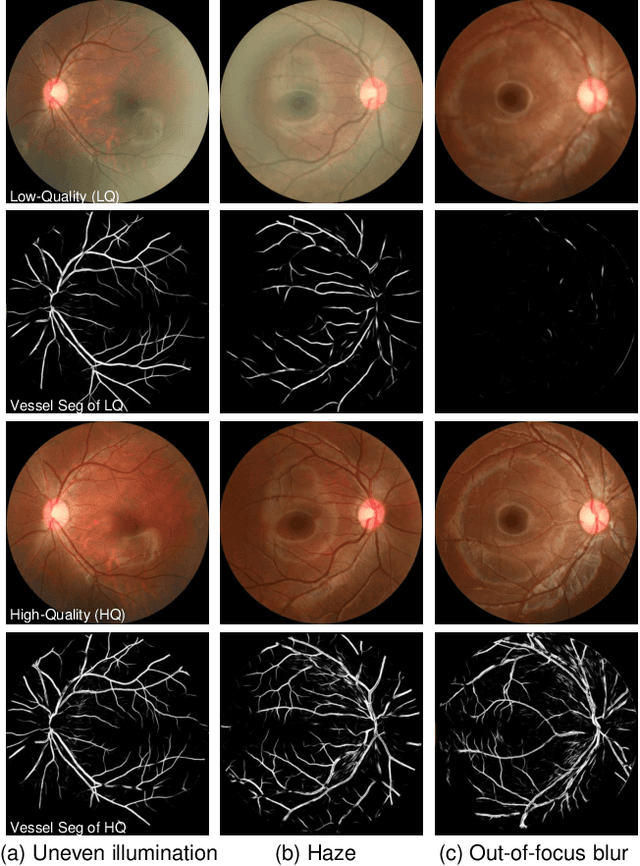

Ophthalmologists have used fundus images to screen and diagnose eye diseases. However, different equipments and ophthalmologists pose large variations to the quality of fundus images. Low-quality (LQ) degraded fundus images easily lead to uncertainty in clinical screening and generally increase the risk of misdiagnosis. Thus, real fundus image restoration is worth studying. Unfortunately, real clinical benchmark has not been explored for this task so far. In this paper, we investigate the real clinical fundus image restoration problem. Firstly, We establish a clinical dataset, Real Fundus (RF), including 120 low- and high-quality (HQ) image pairs. Then we propose a novel Transformer-based Generative Adversarial Network (RFormer) to restore the real degradation of clinical fundus images. The key component in our network is the Window-based Self-Attention Block (WSAB) which captures non-local self-similarity and long-range dependencies. To produce more visually pleasant results, a Transformer-based discriminator is introduced. Extensive experiments on our clinical benchmark show that the proposed RFormer significantly outperforms the state-of-the-art (SOTA) methods. In addition, experiments of downstream tasks such as vessel segmentation and optic disc/cup detection demonstrate that our proposed RFormer benefits clinical fundus image analysis and applications. The dataset, code, and models will be released.
Effect of surface treatment on vibration energy transfer of ultrasonic sonotrode
Oct 07, 2021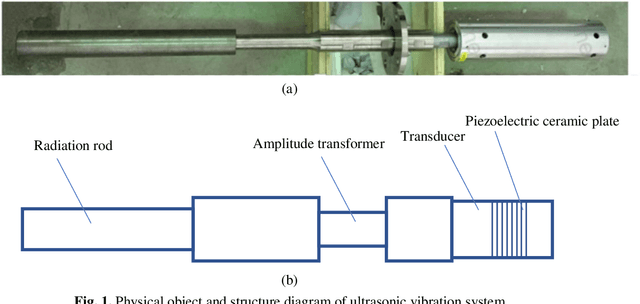


In this paper, two kinds of ultrasonic radiation rod with surface treatment (ion nitriding and vacuum carburizing) are selected to carry out finite element analysis on ultrasonic vibration system and casting system, and explore the influence of surface treatment on vibration energy transmission of radiation rod. The cavitation field of radiation rod with different surface treatment in water was obtained through the cavitation erosion area of aluminum foil in water by using the aluminum foil cavitation experiment, so as to verify the simulation results of sound pressure field in aluminum melt. The results show that the surface treatment weakens the vibration response of the radiating rod, reduces the longitudinal amplitude of the radiating rod, and reduces the amplitude of sound pressure transmitted into the aluminum melt.