 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMatrix: A Skill-centric Hierarchical Framework for Scalable Robot Task Planning and Execution in Open-World
Nov 29, 2024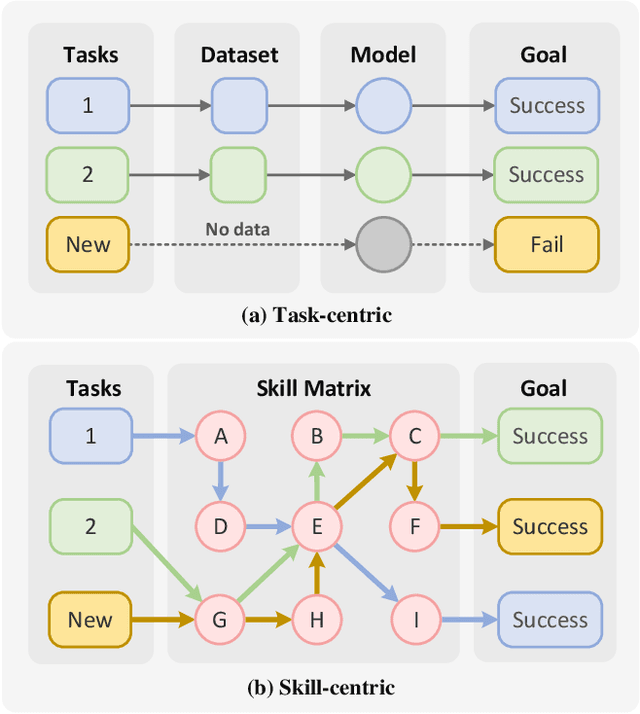

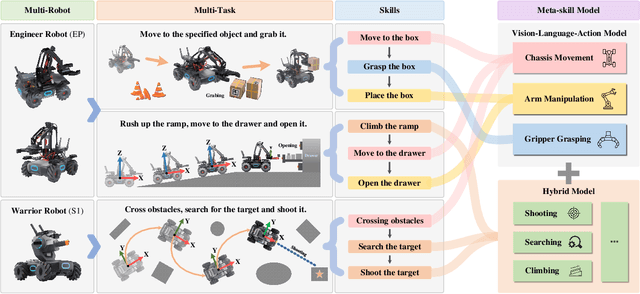

Existing policy learning methods predominantly adopt the task-centric paradigm, necessitating the collection of task data in an end-to-end manner. Consequently, the learned policy tends to fail to tackle novel tasks. Moreover, it is hard to localize the errors for a complex task with multiple stages due to end-to-end learning. To address these challenges, we propose RoboMatrix, a skill-centric and hierarchical framework for scalable task planning and execution. We first introduce a novel skill-centric paradigm that extracts the common meta-skills from different complex tasks. This allows for the capture of embodied demonstrations through a kill-centric approach, enabling the completion of open-world tasks by combining learned meta-skills. To fully leverage meta-skills, we further develop a hierarchical framework that decouples complex robot tasks into three interconnected layers: (1) a high-level modular scheduling layer; (2) a middle-level skill layer; and (3) a low-level hardware layer. Experimental results illustrate that our skill-centric and hierarchical framework achieves remarkable generalization performance across novel objects, scenes, tasks, and embodiments. This framework offers a novel solution for robot task planning and execution in open-world scenarios. Our software and hardware are available at https://github.com/WayneMao/RoboMatrix.
Improving Semantic Segmentation via Self-Training
May 06, 2020
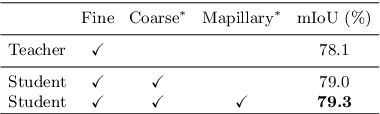
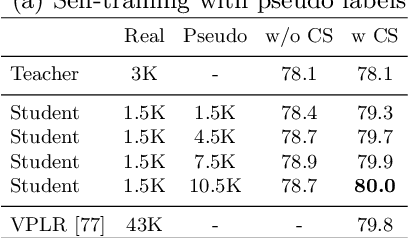
Deep learning usually achieves the best results with complete supervision. In the case of semantic segmentation, this means that large amounts of pixelwise annotations are required to learn accurate models. In this paper, we show that we can obtain state-of-the-art results using a semi-supervised approach, specifically a self-training paradigm. We first train a teacher model on labeled data, and then generate pseudo labels on a large set of unlabeled data. Our robust training framework can digest human-annotated and pseudo labels jointly and achieve top performances on Cityscapes, CamVid and KITTI datasets while requiring significantly less supervision. We also demonstrate the effectiveness of self-training on a challenging cross-domain generalization task, outperforming conventional finetuning method by a large margin. Lastly, to alleviate the computational burden caused by the large amount of pseudo labels, we propose a fast training schedule to accelerate the training of segmentation models by up to 2x without performance degradation.
ResNeSt: Split-Attention Networks
Apr 19, 2020
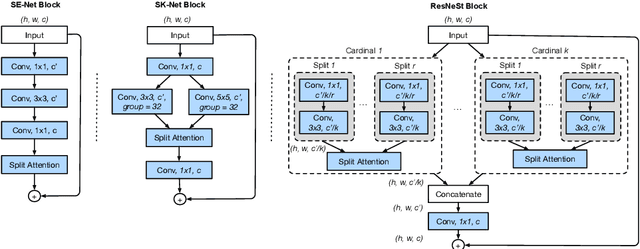
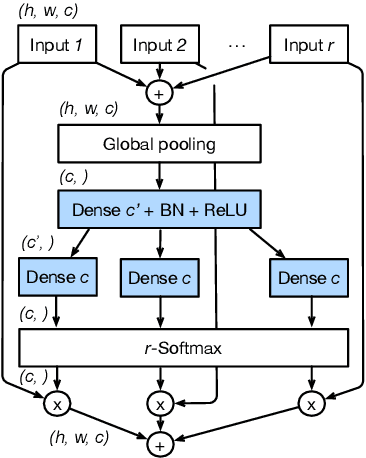
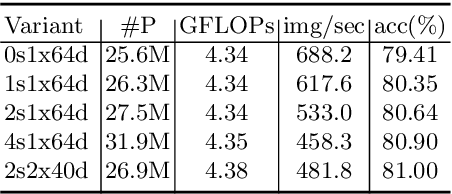
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing
Jul 09, 2019
We present GluonCV and GluonNLP, the deep learning toolkits for computer vision and natural language processing based on Apache MXNet (incubating). These toolkits provide state-of-the-art pre-trained models, training scripts, and training logs, to facilitate rapid prototyping and promote reproducible research. We also provide modular APIs with flexible building blocks to enable efficient customization. Leveraging the MXNet ecosystem, the deep learning models in GluonCV and GluonNLP can be deployed onto a variety of platforms with different programming languages. Benefiting from open source under the Apache 2.0 license, GluonCV and GluonNLP have attracted 100 contributors worldwide on GitHub. Models of GluonCV and GluonNLP have been downloaded for more than 1.6 million times in fewer than 10 months.
Predicting Retrosynthetic Reaction using Self-Corrected Transformer Neural Networks
Jul 03, 2019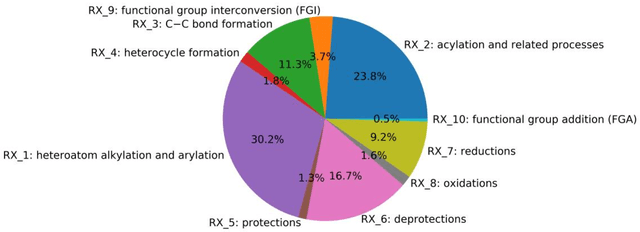
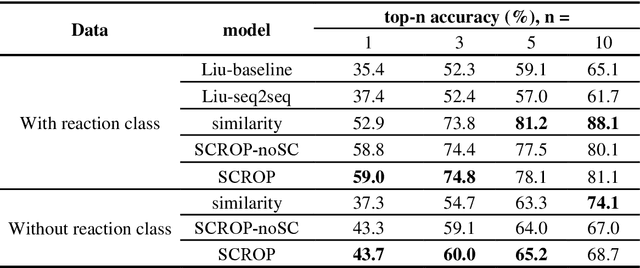
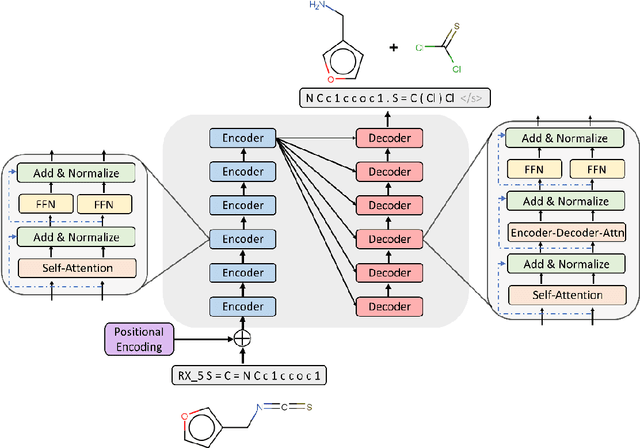
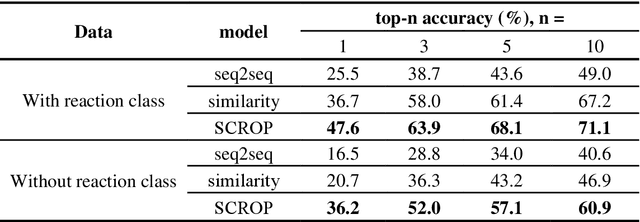
Synthesis planning is the process of recursively decomposing target molecules into available precursors. Computer-aided retrosynthesis can potentially assist chemists in designing synthetic routes, but at present it is cumbersome and provides results of dissatisfactory quality. In this study, we develop a template-free self-corrected retrosynthesis predictor (SCROP) to perform a retrosynthesis prediction task trained by using the Transformer neural network architecture. In the method, the retrosynthesis planning is converted as a machine translation problem between molecular linear notations of reactants and the products. Coupled with a neural network-based syntax corrector, our method achieves an accuracy of 59.0% on a standard benchmark dataset, which increases >21% over other deep learning methods, and >6% over template-based methods. More importantly, our method shows an accuracy 1.7 times higher than other state-of-the-art methods for compounds not appearing in the training set.
Bag of Freebies for Training Object Detection Neural Networks
Apr 12, 2019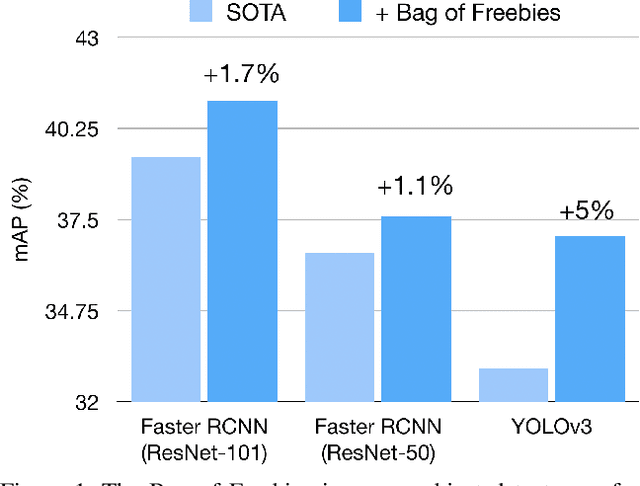
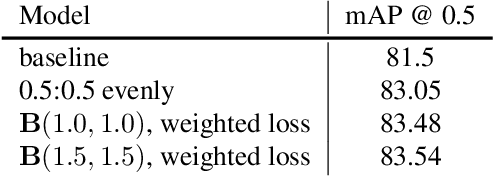


Training heuristics greatly improve various image classification model accuracies~\cite{he2018bag}. Object detection models, however, have more complex neural network structures and optimization targets. The training strategies and pipelines dramatically vary among different models. In this works, we explore training tweaks that apply to various models including Faster R-CNN and YOLOv3. These tweaks do not change the model architectures, therefore, the inference costs remain the same. Our empirical results demonstrate that, however, these freebies can improve up to 5% absolute precision compared to state-of-the-art baselines.
Bag of Tricks for Image Classification with Convolutional Neural Networks
Dec 05, 2018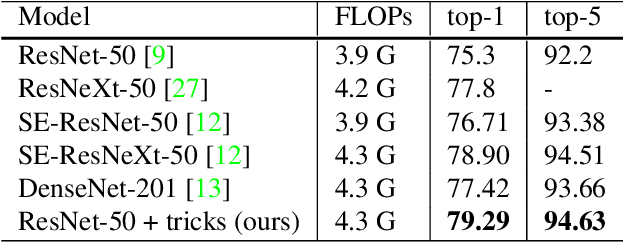
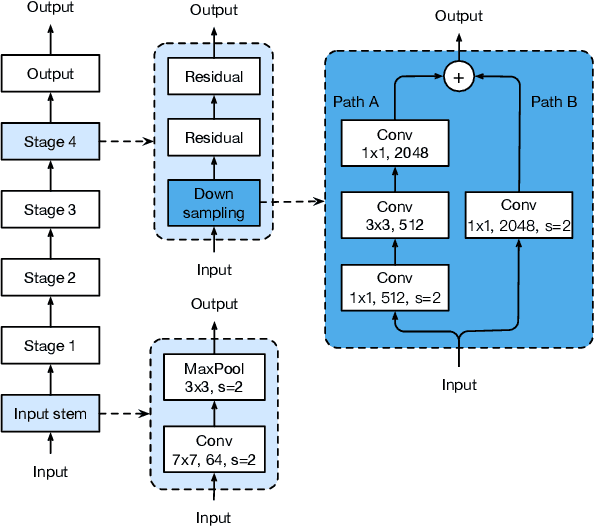
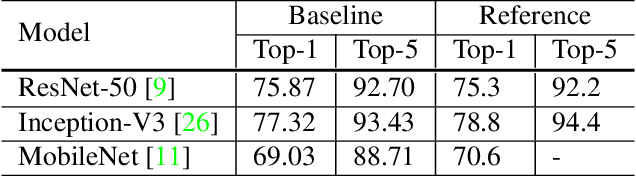
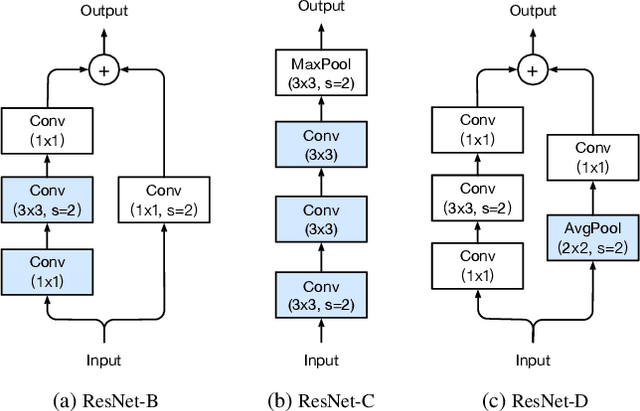
Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50's top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic segmentation.
Context Encoding for Semantic Segmentation
Mar 23, 2018
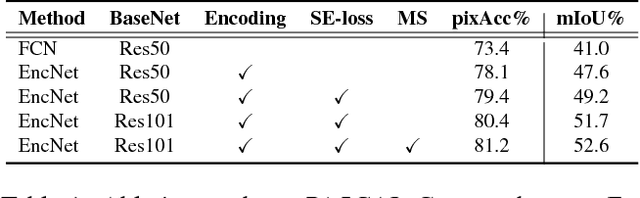
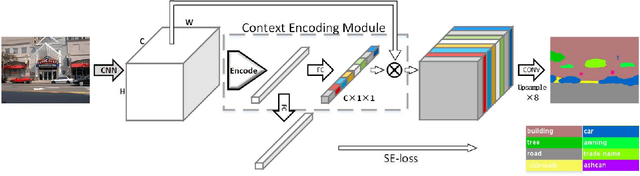
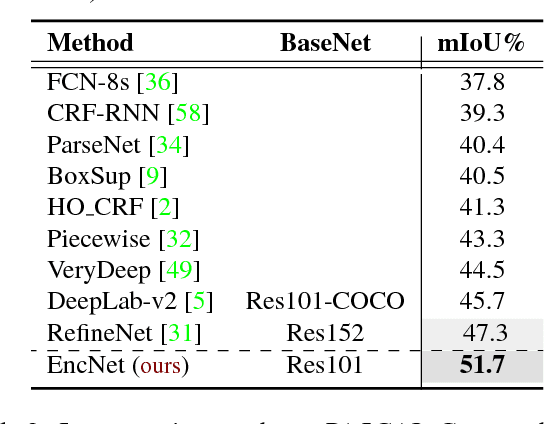
Recent work has made significant progress in improving spatial resolution for pixelwise labeling with Fully Convolutional Network (FCN) framework by employing Dilated/Atrous convolution, utilizing multi-scale features and refining boundaries. In this paper, we explore the impact of global contextual information in semantic segmentation by introducing the Context Encoding Module, which captures the semantic context of scenes and selectively highlights class-dependent featuremaps. The proposed Context Encoding Module significantly improves semantic segmentation results with only marginal extra computation cost over FCN. Our approach has achieved new state-of-the-art results 51.7% mIoU on PASCAL-Context, 85.9% mIoU on PASCAL VOC 2012. Our single model achieves a final score of 0.5567 on ADE20K test set, which surpass the winning entry of COCO-Place Challenge in 2017. In addition, we also explore how the Context Encoding Module can improve the feature representation of relatively shallow networks for the image classification on CIFAR-10 dataset. Our 14 layer network has achieved an error rate of 3.45%, which is comparable with state-of-the-art approaches with over 10 times more layers. The source code for the complete system are publicly available.
megaman: Manifold Learning with Millions of points
Mar 09, 2016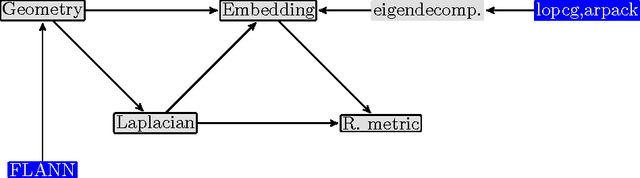
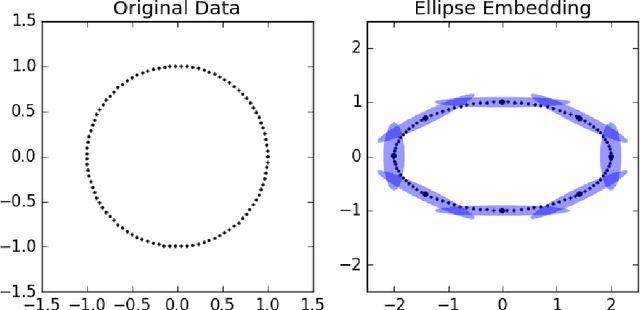
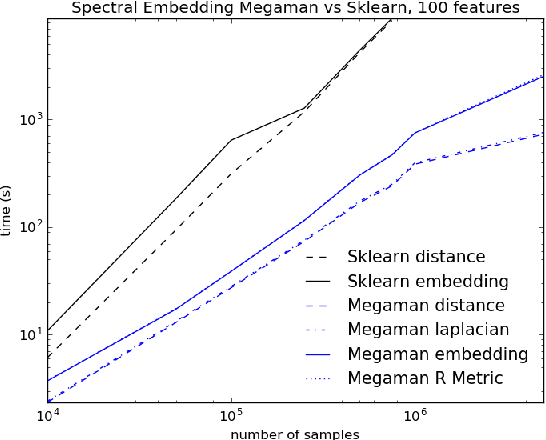
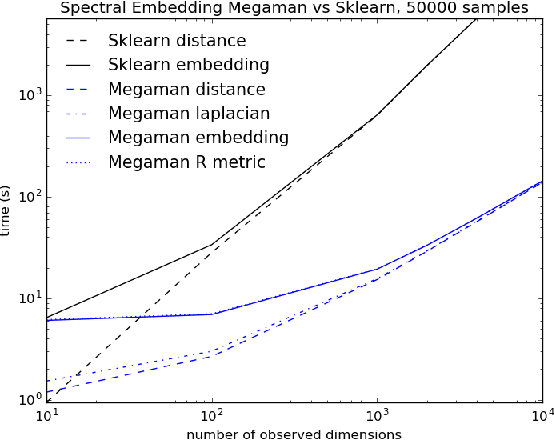
Manifold Learning is a class of algorithms seeking a low-dimensional non-linear representation of high-dimensional data. Thus manifold learning algorithms are, at least in theory, most applicable to high-dimensional data and sample sizes to enable accurate estimation of the manifold. Despite this, most existing manifold learning implementations are not particularly scalable. Here we present a Python package that implements a variety of manifold learning algorithms in a modular and scalable fashion, using fast approximate neighbors searches and fast sparse eigendecompositions. The package incorporates theoretical advances in manifold learning, such as the unbiased Laplacian estimator and the estimation of the embedding distortion by the Riemannian metric method. In benchmarks, even on a single-core desktop computer, our code embeds millions of data points in minutes, and takes just 200 minutes to embed the main sample of galaxy spectra from the Sloan Digital Sky Survey --- consisting of 0.6 million samples in 3750-dimensions --- a task which has not previously been possible.