 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Visual Question Answering Pipeline for Autonomous Driving via Scene Region Compression
Jan 11, 2026Autonomous driving increasingly relies on Visual Question Answering (VQA) to enable vehicles to understand complex surroundings by analyzing visual inputs and textual queries. Currently, a paramount concern for VQA in this domain is the stringent requirement for fast latency and real-time processing, as delays directly impact real-world safety in this safety-critical application. However, current state-of-the-art VQA models, particularly large vision-language models (VLMs), often prioritize performance over computational efficiency. These models typically process dense patch tokens for every frame, leading to prohibitive computational costs (FLOPs) and significant inference latency, especially with long video sequences. This focus limits their practical deployment in real-time autonomous driving scenarios. To tackle this issue, we propose an efficient VLM framework for autonomous driving VQA tasks, SRC-Pipeline. It learns to compress early frame tokens into a small number of high-level tokens while retaining full patch tokens for recent frames. Experiments on autonomous driving video question answering tasks show that our approach achieves 66% FLOPs reduction while maintaining comparable performance, enabling VLMs to operate more effectively in real-time, safety-critical autonomous driving settings.
Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Nov 15, 2025Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of "Seeing is Believing", we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o's capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
VideoSAM: Open-World Video Segmentation
Oct 11, 2024



Video segmentation is essential for advancing robotics and autonomous driving, particularly in open-world settings where continuous perception and object association across video frames are critical. While the Segment Anything Model (SAM) has excelled in static image segmentation, extending its capabilities to video segmentation poses significant challenges. We tackle two major hurdles: a) SAM's embedding limitations in associating objects across frames, and b) granularity inconsistencies in object segmentation. To this end, we introduce VideoSAM, an end-to-end framework designed to address these challenges by improving object tracking and segmentation consistency in dynamic environments. VideoSAM integrates an agglomerated backbone, RADIO, enabling object association through similarity metrics and introduces Cycle-ack-Pairs Propagation with a memory mechanism for stable object tracking. Additionally, we incorporate an autoregressive object-token mechanism within the SAM decoder to maintain consistent granularity across frames. Our method is extensively evaluated on the UVO and BURST benchmarks, and robotic videos from RoboTAP, demonstrating its effectiveness and robustness in real-world scenarios. All codes will be available.
A Unified Efficient Pyramid Transformer for Semantic Segmentation
Jul 29, 2021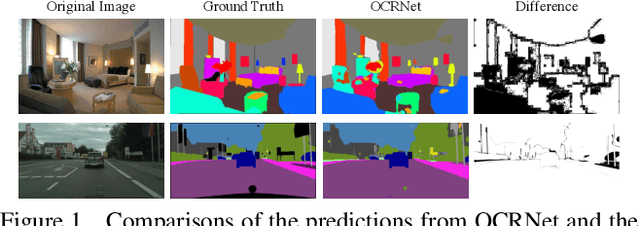
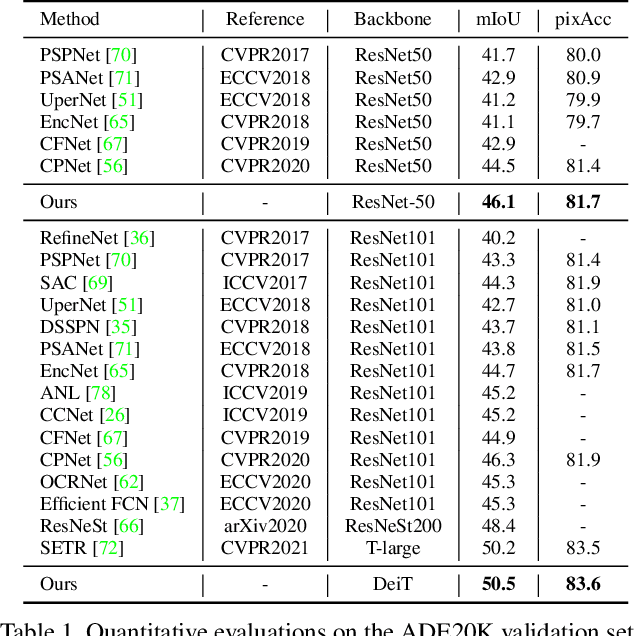
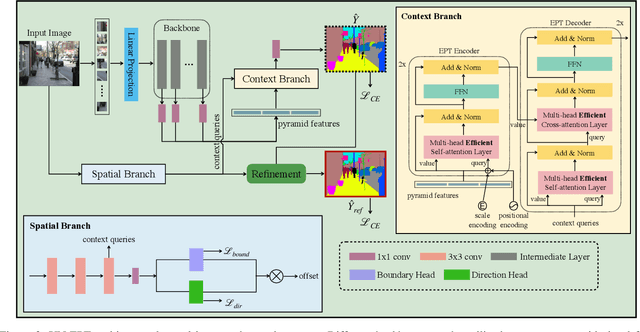
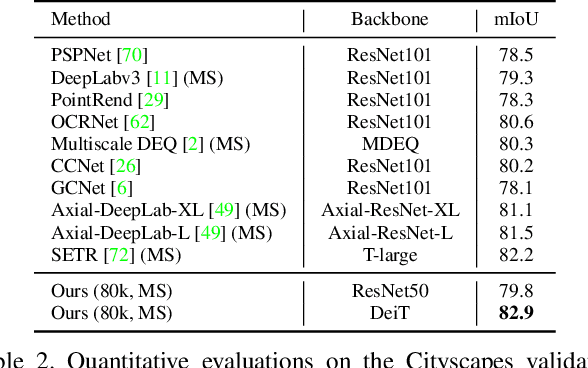
Semantic segmentation is a challenging problem due to difficulties in modeling context in complex scenes and class confusions along boundaries. Most literature either focuses on context modeling or boundary refinement, which is less generalizable in open-world scenarios. In this work, we advocate a unified framework(UN-EPT) to segment objects by considering both context information and boundary artifacts. We first adapt a sparse sampling strategy to incorporate the transformer-based attention mechanism for efficient context modeling. In addition, a separate spatial branch is introduced to capture image details for boundary refinement. The whole model can be trained in an end-to-end manner. We demonstrate promising performance on three popular benchmarks for semantic segmentation with low memory footprint. Code will be released soon.
A Comprehensive Study of Deep Video Action Recognition
Dec 11, 2020
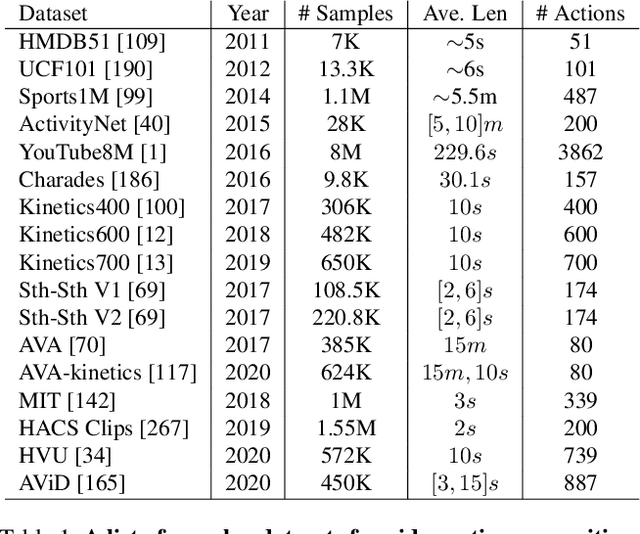
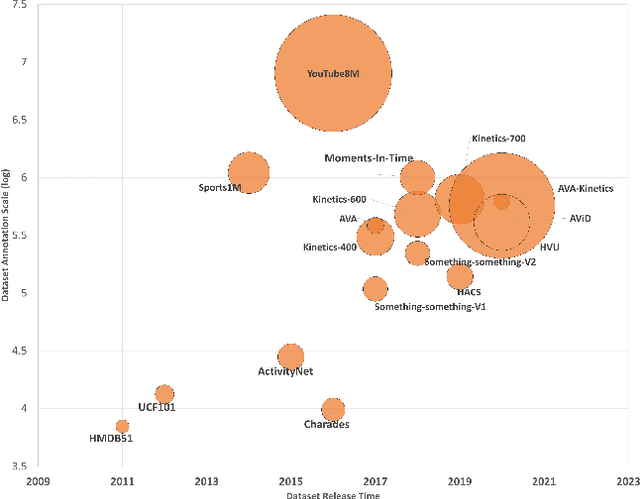
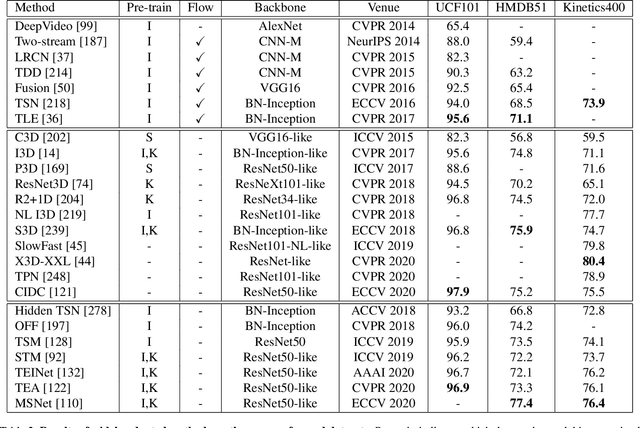
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
Improving Semantic Segmentation via Self-Training
May 06, 2020
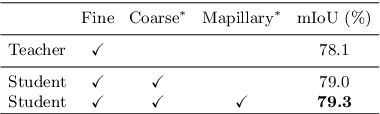
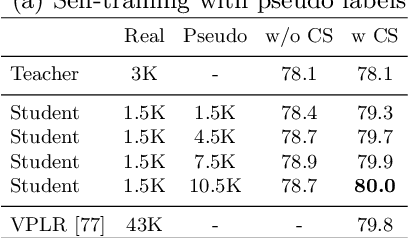
Deep learning usually achieves the best results with complete supervision. In the case of semantic segmentation, this means that large amounts of pixelwise annotations are required to learn accurate models. In this paper, we show that we can obtain state-of-the-art results using a semi-supervised approach, specifically a self-training paradigm. We first train a teacher model on labeled data, and then generate pseudo labels on a large set of unlabeled data. Our robust training framework can digest human-annotated and pseudo labels jointly and achieve top performances on Cityscapes, CamVid and KITTI datasets while requiring significantly less supervision. We also demonstrate the effectiveness of self-training on a challenging cross-domain generalization task, outperforming conventional finetuning method by a large margin. Lastly, to alleviate the computational burden caused by the large amount of pseudo labels, we propose a fast training schedule to accelerate the training of segmentation models by up to 2x without performance degradation.
A Tailored Pre-Training Model for Task-Oriented Dialog Generation
Apr 24, 2020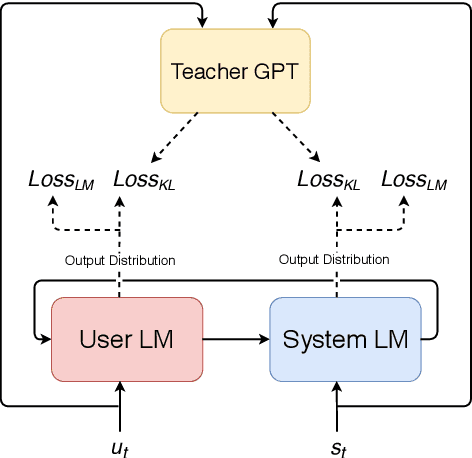

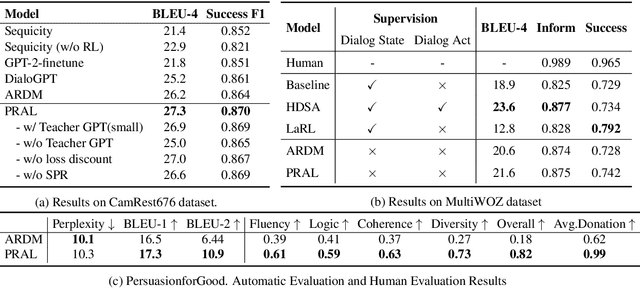
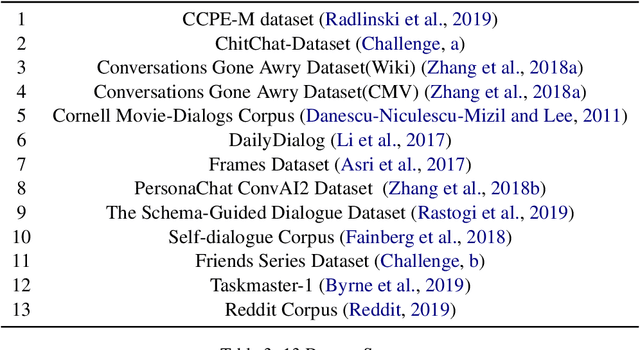
The recent success of large pre-trained language models such as BERT and GPT-2 has suggested the effectiveness of incorporating language priors in downstream dialog generation tasks. However, the performance of pre-trained models on the dialog task is not as optimal as expected. In this paper, we propose a Pre-trained Role Alternating Language model (PRAL), designed specifically for task-oriented conversational systems. We adopted (Wu et al., 2019) that models two speakers separately. We also design several techniques, such as start position randomization, knowledge distillation, and history discount to improve pre-training performance. We introduce a task-oriented dialog pretraining dataset by cleaning 13 existing data sets. We test PRAL on three different downstream tasks. The results show that PRAL performs better or on par with state-of-the-art methods.
ResNeSt: Split-Attention Networks
Apr 19, 2020
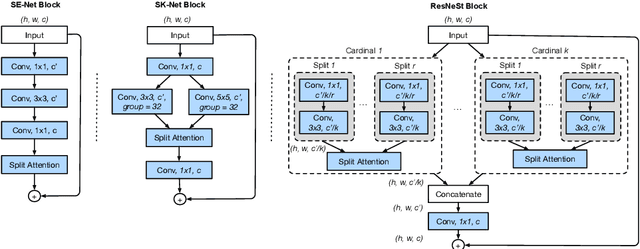
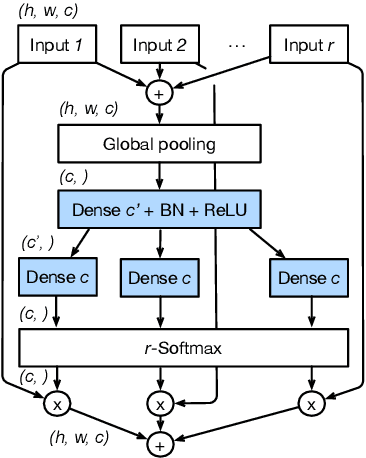
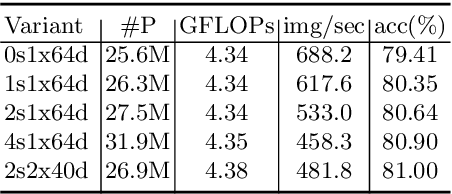
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
Adv-BNN: Improved Adversarial Defense through Robust Bayesian Neural Network
Oct 01, 2018
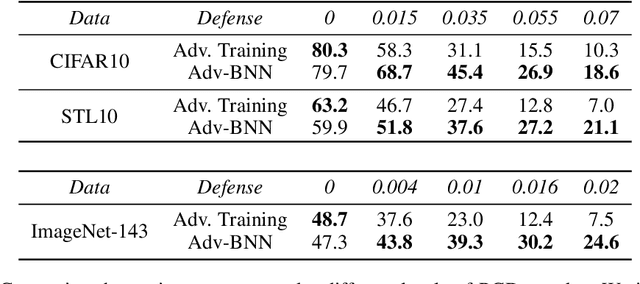
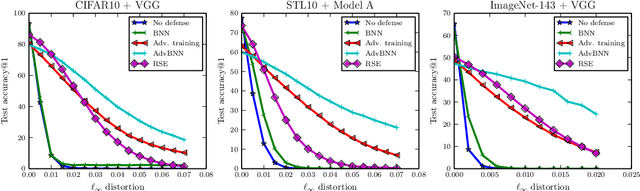

We present a new algorithm to train a robust neural network against adversarial attacks. Our algorithm is motivated by the following two ideas. First, although recent work has demonstrated that fusing randomness can improve the robustness of neural networks (Liu 2017), we noticed that adding noise blindly to all the layers is not the optimal way to incorporate randomness. Instead, we model randomness under the framework of Bayesian Neural Network (BNN) to formally learn the posterior distribution of models in a scalable way. Second, we formulate the mini-max problem in BNN to learn the best model distribution under adversarial attacks, leading to an adversarial-trained Bayesian neural net. Experiment results demonstrate that the proposed algorithm achieves state-of-the-art performance under strong attacks. On CIFAR-10 with VGG network, our model leads to 14\% accuracy improvement compared with adversarial training (Madry 2017) and random self-ensemble (Liu 2017) under PGD attack with $0.035$ distortion, and the gap becomes even larger on a subset of ImageNet.
Cruciform: Solving Crosswords with Natural Language Processing
Nov 23, 2016
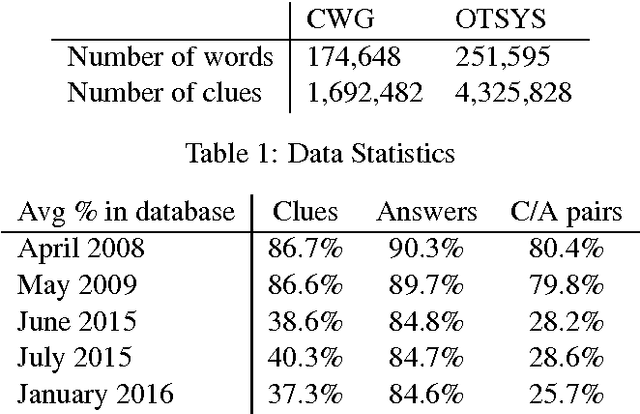
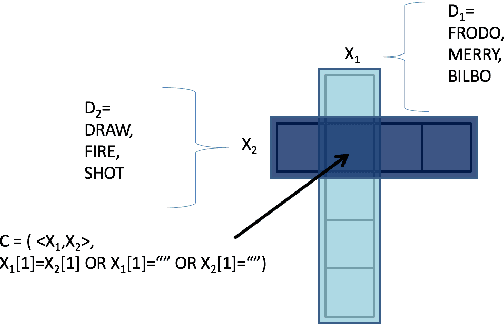
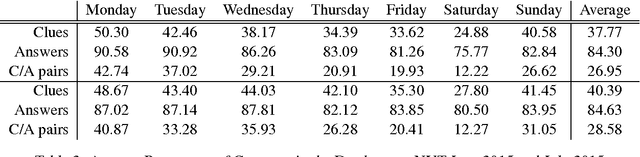
Crossword puzzles are popular word games that require not only a large vocabulary, but also a broad knowledge of topics. Answering each clue is a natural language task on its own as many clues contain nuances, puns, or counter-intuitive word definitions. Additionally, it can be extremely difficult to ascertain definitive answers without the constraints of the crossword grid itself. This task is challenging for both humans and computers. We describe here a new crossword solving system, Cruciform. We employ a group of natural language components, each of which returns a list of candidate words with scores when given a clue. These lists are used in conjunction with the fill intersections in the puzzle grid to formulate a constraint satisfaction problem, in a manner similar to the one used in the Dr. Fill system. We describe the results of several of our experiments with the system.