 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
CineBrain: A Large-Scale Multi-Modal Brain Dataset During Naturalistic Audiovisual Narrative Processing
Mar 10, 2025In this paper, we introduce CineBrain, the first large-scale dataset featuring simultaneous EEG and fMRI recordings during dynamic audiovisual stimulation. Recognizing the complementary strengths of EEG's high temporal resolution and fMRI's deep-brain spatial coverage, CineBrain provides approximately six hours of narrative-driven content from the popular television series The Big Bang Theory for each of six participants. Building upon this unique dataset, we propose CineSync, an innovative multimodal decoding framework integrates a Multi-Modal Fusion Encoder with a diffusion-based Neural Latent Decoder. Our approach effectively fuses EEG and fMRI signals, significantly improving the reconstruction quality of complex audiovisual stimuli. To facilitate rigorous evaluation, we introduce Cine-Benchmark, a comprehensive evaluation protocol that assesses reconstructions across semantic and perceptual dimensions. Experimental results demonstrate that CineSync achieves state-of-the-art video reconstruction performance and highlight our initial success in combining fMRI and EEG for reconstructing both video and audio stimuli. Project Page: https://jianxgao.github.io/CineBrain.
Making Your Dreams A Reality: Decoding the Dreams into a Coherent Video Story from fMRI Signals
Jan 16, 2025



This paper studies the brave new idea for Multimedia community, and proposes a novel framework to convert dreams into coherent video narratives using fMRI data. Essentially, dreams have intrigued humanity for centuries, offering glimpses into our subconscious minds. Recent advancements in brain imaging, particularly functional magnetic resonance imaging (fMRI), have provided new ways to explore the neural basis of dreaming. By combining subjective dream experiences with objective neurophysiological data, we aim to understand the visual aspects of dreams and create complete video narratives. Our process involves three main steps: reconstructing visual perception, decoding dream imagery, and integrating dream stories. Using innovative techniques in fMRI analysis and language modeling, we seek to push the boundaries of dream research and gain deeper insights into visual experiences during sleep. This technical report introduces a novel approach to visually decoding dreams using fMRI signals and weaving dream visuals into narratives using language models. We gather a dataset of dreams along with descriptions to assess the effectiveness of our framework.
Factorized Visual Tokenization and Generation
Nov 25, 2024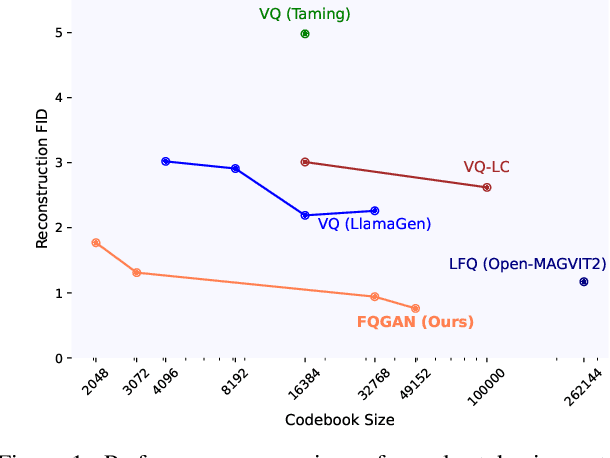
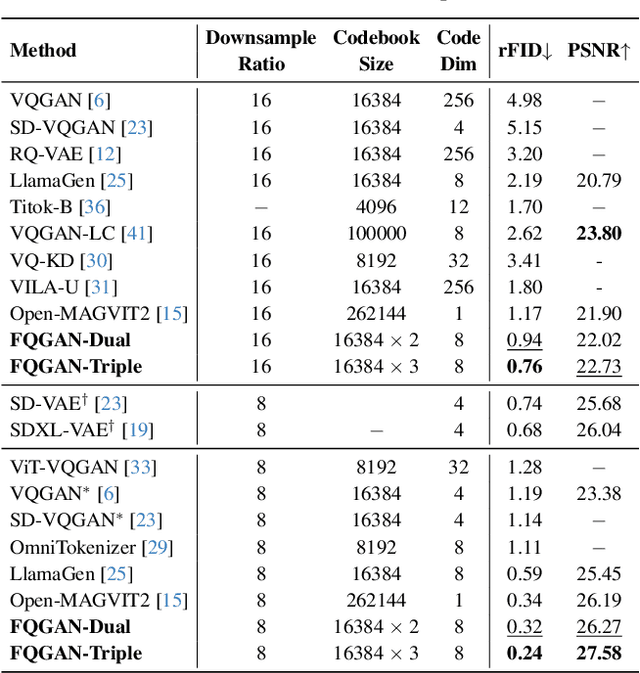
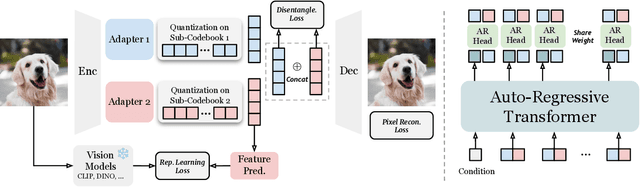
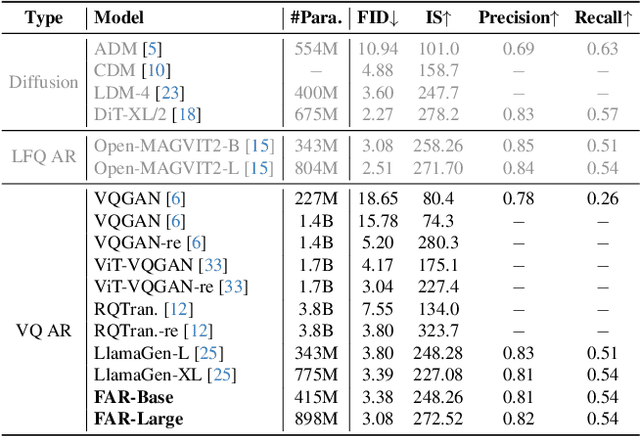
Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN
VideoSAM: Open-World Video Segmentation
Oct 11, 2024



Video segmentation is essential for advancing robotics and autonomous driving, particularly in open-world settings where continuous perception and object association across video frames are critical. While the Segment Anything Model (SAM) has excelled in static image segmentation, extending its capabilities to video segmentation poses significant challenges. We tackle two major hurdles: a) SAM's embedding limitations in associating objects across frames, and b) granularity inconsistencies in object segmentation. To this end, we introduce VideoSAM, an end-to-end framework designed to address these challenges by improving object tracking and segmentation consistency in dynamic environments. VideoSAM integrates an agglomerated backbone, RADIO, enabling object association through similarity metrics and introduces Cycle-ack-Pairs Propagation with a memory mechanism for stable object tracking. Additionally, we incorporate an autoregressive object-token mechanism within the SAM decoder to maintain consistent granularity across frames. Our method is extensively evaluated on the UVO and BURST benchmarks, and robotic videos from RoboTAP, demonstrating its effectiveness and robustness in real-world scenarios. All codes will be available.
fMRI-3D: A Comprehensive Dataset for Enhancing fMRI-based 3D Reconstruction
Sep 17, 2024



Reconstructing 3D visuals from functional Magnetic Resonance Imaging (fMRI) data, introduced as Recon3DMind in our conference work, is of significant interest to both cognitive neuroscience and computer vision. To advance this task, we present the fMRI-3D dataset, which includes data from 15 participants and showcases a total of 4768 3D objects. The dataset comprises two components: fMRI-Shape, previously introduced and accessible at https://huggingface.co/datasets/Fudan-fMRI/fMRI-Shape, and fMRI-Objaverse, proposed in this paper and available at https://huggingface.co/datasets/Fudan-fMRI/fMRI-Objaverse. fMRI-Objaverse includes data from 5 subjects, 4 of whom are also part of the Core set in fMRI-Shape, with each subject viewing 3142 3D objects across 117 categories, all accompanied by text captions. This significantly enhances the diversity and potential applications of the dataset. Additionally, we propose MinD-3D, a novel framework designed to decode 3D visual information from fMRI signals. The framework first extracts and aggregates features from fMRI data using a neuro-fusion encoder, then employs a feature-bridge diffusion model to generate visual features, and finally reconstructs the 3D object using a generative transformer decoder. We establish new benchmarks by designing metrics at both semantic and structural levels to evaluate model performance. Furthermore, we assess our model's effectiveness in an Out-of-Distribution setting and analyze the attribution of the extracted features and the visual ROIs in fMRI signals. Our experiments demonstrate that MinD-3D not only reconstructs 3D objects with high semantic and spatial accuracy but also deepens our understanding of how human brain processes 3D visual information. Project page at: https://jianxgao.github.io/MinD-3D.
LAC-Net: Linear-Fusion Attention-Guided Convolutional Network for Accurate Robotic Grasping Under the Occlusion
Aug 06, 2024



This paper addresses the challenge of perceiving complete object shapes through visual perception. While prior studies have demonstrated encouraging outcomes in segmenting the visible parts of objects within a scene, amodal segmentation, in particular, has the potential to allow robots to infer the occluded parts of objects. To this end, this paper introduces a new framework that explores amodal segmentation for robotic grasping in cluttered scenes, thus greatly enhancing robotic grasping abilities. Initially, we use a conventional segmentation algorithm to detect the visible segments of the target object, which provides shape priors for completing the full object mask. Particularly, to explore how to utilize semantic features from RGB images and geometric information from depth images, we propose a Linear-fusion Attention-guided Convolutional Network (LAC-Net). LAC-Net utilizes the linear-fusion strategy to effectively fuse this cross-modal data, and then uses the prior visible mask as attention map to guide the network to focus on target feature locations for further complete mask recovery. Using the amodal mask of the target object provides advantages in selecting more accurate and robust grasp points compared to relying solely on the visible segments. The results on different datasets show that our method achieves state-of-the-art performance. Furthermore, the robot experiments validate the feasibility and robustness of this method in the real world. Our code and demonstrations are available on the project page: https://jrryzh.github.io/LAC-Net.
Hyper-Transformer for Amodal Completion
May 30, 2024



Amodal object completion is a complex task that involves predicting the invisible parts of an object based on visible segments and background information. Learning shape priors is crucial for effective amodal completion, but traditional methods often rely on two-stage processes or additional information, leading to inefficiencies and potential error accumulation. To address these shortcomings, we introduce a novel framework named the Hyper-Transformer Amodal Network (H-TAN). This framework utilizes a hyper transformer equipped with a dynamic convolution head to directly learn shape priors and accurately predict amodal masks. Specifically, H-TAN uses a dual-branch structure to extract multi-scale features from both images and masks. The multi-scale features from the image branch guide the hyper transformer in learning shape priors and in generating the weights for dynamic convolution tailored to each instance. The dynamic convolution head then uses the features from the mask branch to predict precise amodal masks. We extensively evaluate our model on three benchmark datasets: KINS, COCOA-cls, and D2SA, where H-TAN demonstrated superior performance compared to existing methods. Additional experiments validate the effectiveness and stability of the novel hyper transformer in our framework.
MinD-3D: Reconstruct High-quality 3D objects in Human Brain
Dec 12, 2023In this paper, we introduce Recon3DMind, a groundbreaking task focused on reconstructing 3D visuals from Functional Magnetic Resonance Imaging (fMRI) signals. This represents a major step forward in cognitive neuroscience and computer vision. To support this task, we present the fMRI-Shape dataset, utilizing 360-degree view videos of 3D objects for comprehensive fMRI signal capture. Containing 55 categories of common objects from daily life, this dataset will bolster future research endeavors. We also propose MinD-3D, a novel and effective three-stage framework that decodes and reconstructs the brain's 3D visual information from fMRI signals. This method starts by extracting and aggregating features from fMRI frames using a neuro-fusion encoder, then employs a feature bridge diffusion model to generate corresponding visual features, and ultimately recovers the 3D object through a generative transformer decoder. Our experiments demonstrate that this method effectively extracts features that are valid and highly correlated with visual regions of interest (ROIs) in fMRI signals. Notably, it not only reconstructs 3D objects with high semantic relevance and spatial similarity but also significantly deepens our understanding of the human brain's 3D visual processing capabilities. Project page at: https://jianxgao.github.io/MinD-3D.