 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video
May 13, 2026Egocentric human video data, which captures rich human-environment interactions and can be collected at scale, has become a key driver of embodied intelligence research. However, existing egocentric datasets typically lack tactile sensing, a critical modality that provides direct cues about contact, force, and pressure in human-object interaction. Without such signals, models struggle to learn physically grounded representations of real-world interaction dynamics. While tactile sensors provide these cues, deploying high-quality tactile hardware at scale remains expensive and cumbersome. This raises a central question: can tactile feedback be inferred directly from visual observations, enabling scalable tactile supervision for egocentric video data and supporting physically grounded embodied learning? To enable research in this direction, we introduce EgoTouch, a large-scale multi-view egocentric dataset with dense tactile supervision for bimanual hand-object interaction. EgoTouch comprises 208 manipulation tasks spanning 1,891 episodes in diverse indoor and outdoor environments, with synchronized multi-view RGB (head-mounted egocentric and dual wrist-mounted cameras), bimanual 3D hand pose, and continuous pressure maps from wearable tactile sensors. Building on EgoTouch, we introduce TouchAnything, a baseline multi-view vision-to-touch prediction framework that uses the egocentric view as the primary input and flexibly leverages available wrist-mounted views at inference time. Experiments show that incorporating wrist-mounted views generally improves tactile prediction over egocentric-only input, achieving up to 5.0% relative improvement in Contact IoU and 6.1% relative improvement in Volumetric IoU. We will publicly release the dataset, code, and benchmark.
D-AR: Diffusion via Autoregressive Models
May 29, 2025This paper presents Diffusion via Autoregressive models (D-AR), a new paradigm recasting the image diffusion process as a vanilla autoregressive procedure in the standard next-token-prediction fashion. We start by designing the tokenizer that converts images into sequences of discrete tokens, where tokens in different positions can be decoded into different diffusion denoising steps in the pixel space. Thanks to the diffusion properties, these tokens naturally follow a coarse-to-fine order, which directly lends itself to autoregressive modeling. Therefore, we apply standard next-token prediction on these tokens, without modifying any underlying designs (either causal masks or training/inference strategies), and such sequential autoregressive token generation directly mirrors the diffusion procedure in image space. That is, once the autoregressive model generates an increment of tokens, we can directly decode these tokens into the corresponding diffusion denoising step in the streaming manner. Our pipeline naturally reveals several intriguing properties, for example, it supports consistent previews when generating only a subset of tokens and enables zero-shot layout-controlled synthesis. On the standard ImageNet benchmark, our method achieves 2.09 FID using a 775M Llama backbone with 256 discrete tokens. We hope our work can inspire future research on unified autoregressive architectures of visual synthesis, especially with large language models. Code and models will be available at https://github.com/showlab/D-AR
Factorized Visual Tokenization and Generation
Nov 25, 2024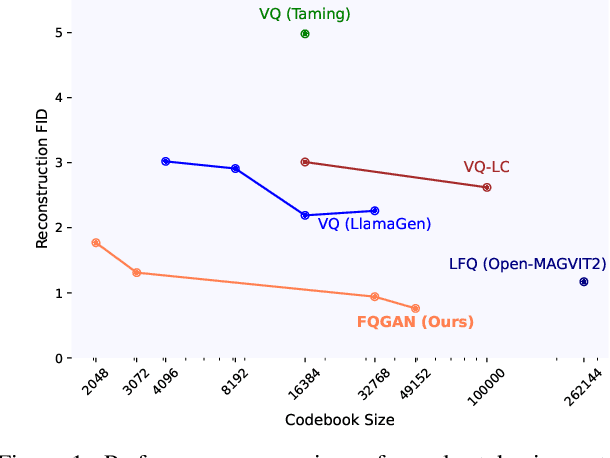
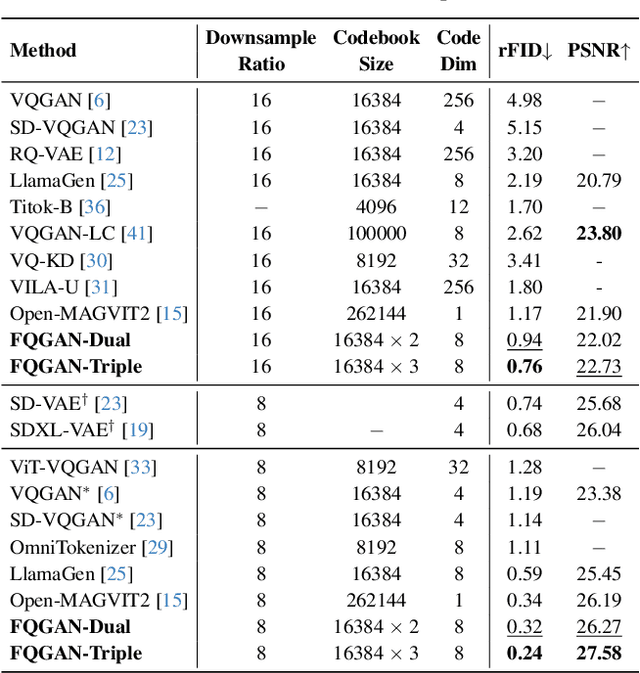
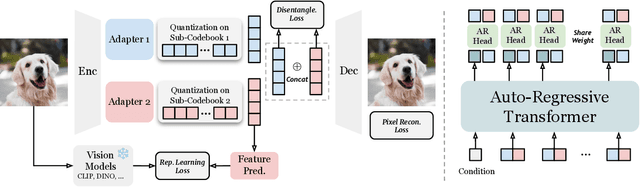
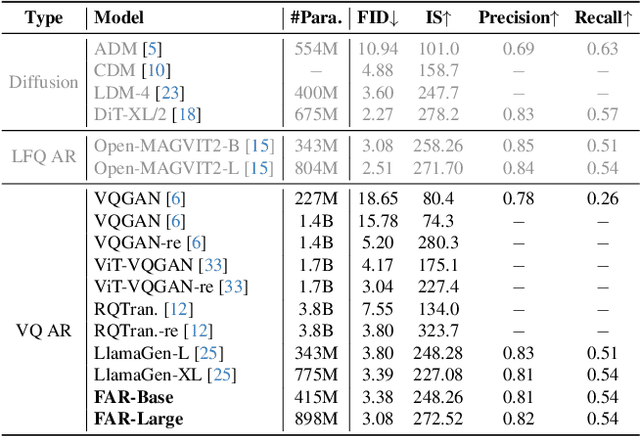
Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos
Sep 29, 2024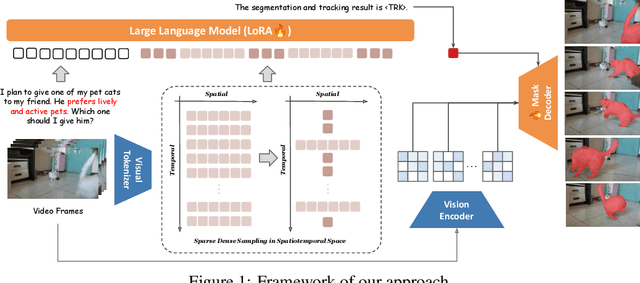
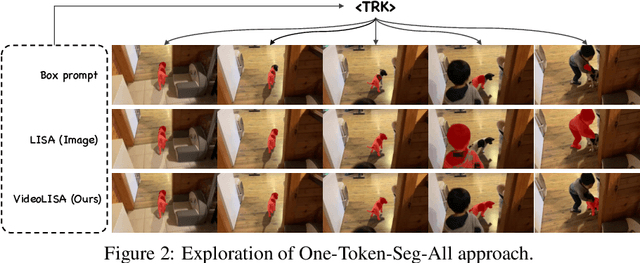


We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions. Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints. Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames. Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA's superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking. While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation. Code and model will be available at: https://github.com/showlab/VideoLISA.
Learning Video Context as Interleaved Multimodal Sequences
Jul 31, 2024



Narrative videos, such as movies, pose significant challenges in video understanding due to their rich contexts (characters, dialogues, storylines) and diverse demands (identify who, relationship, and reason). In this paper, we introduce MovieSeq, a multimodal language model developed to address the wide range of challenges in understanding video contexts. Our core idea is to represent videos as interleaved multimodal sequences (including images, plots, videos, and subtitles), either by linking external knowledge databases or using offline models (such as whisper for subtitles). Through instruction-tuning, this approach empowers the language model to interact with videos using interleaved multimodal instructions. For example, instead of solely relying on video as input, we jointly provide character photos alongside their names and dialogues, allowing the model to associate these elements and generate more comprehensive responses. To demonstrate its effectiveness, we validate MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA) across five settings (video classification, audio description, video-text retrieval, video captioning, and video question-answering). The code will be public at https://github.com/showlab/MovieSeq.
VideoLLM-online: Online Video Large Language Model for Streaming Video
Jun 17, 2024
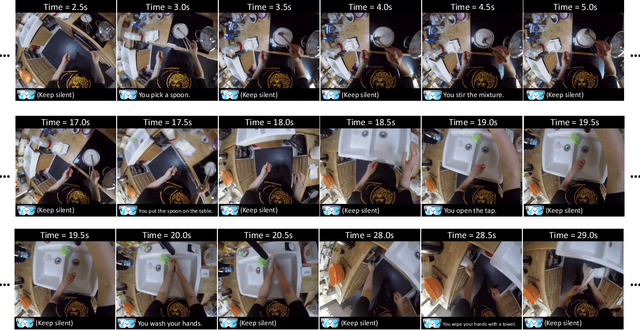
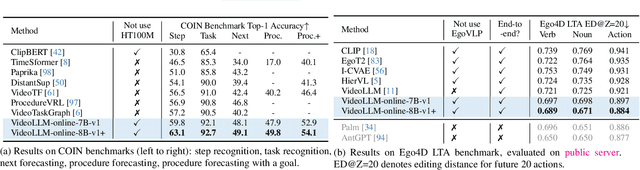
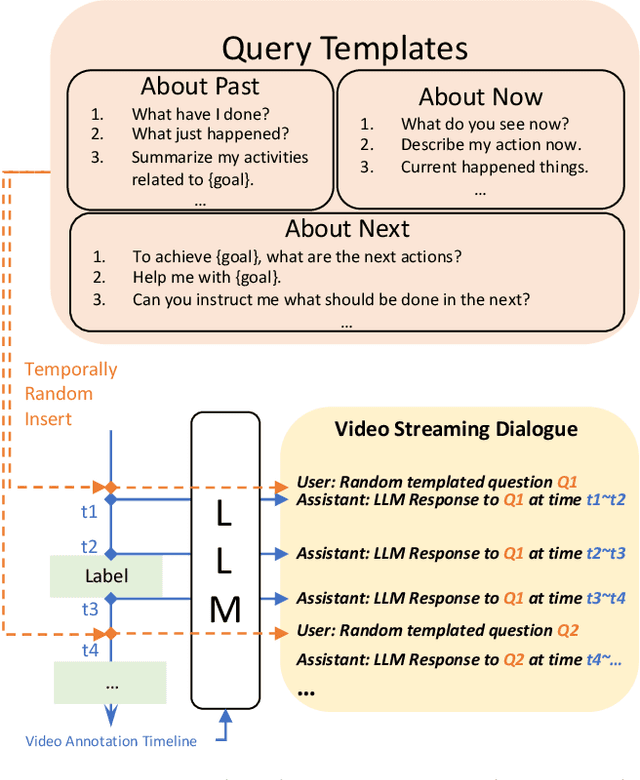
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
Bootstrapping SparseFormers from Vision Foundation Models
Dec 04, 2023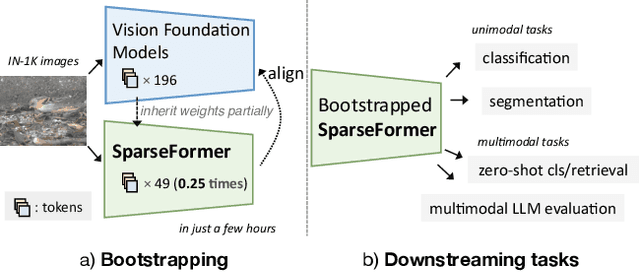
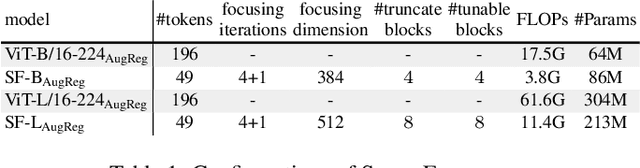
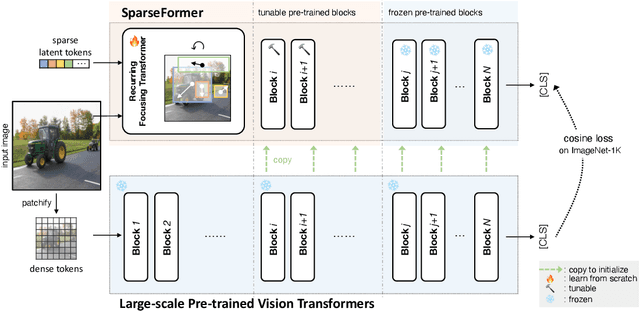
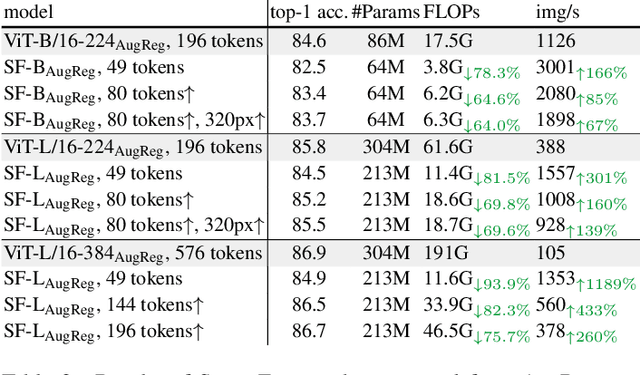
The recently proposed SparseFormer architecture provides an alternative approach to visual understanding by utilizing a significantly lower number of visual tokens via adjusting RoIs, greatly reducing computational costs while still achieving promising performance. However, training SparseFormers from scratch is still expensive, and scaling up the number of parameters can be challenging. In this paper, we propose to bootstrap SparseFormers from ViT-based vision foundation models in a simple and efficient way. Since the majority of SparseFormer blocks are the standard transformer ones, we can inherit weights from large-scale pre-trained vision transformers and freeze them as much as possible. Therefore, we only need to train the SparseFormer-specific lightweight focusing transformer to adjust token RoIs and fine-tune a few early pre-trained blocks to align the final token representation. In such a way, we can bootstrap SparseFormer architectures from various large-scale pre-trained models (e.g., IN-21K pre-trained AugRegs or CLIPs) using a rather smaller amount of training samples (e.g., IN-1K) and without labels or captions within just a few hours. As a result, the bootstrapped unimodal SparseFormer (from AugReg-ViT-L/16-384) can reach 84.9% accuracy on IN-1K with only 49 tokens, and the multimodal SparseFormer from CLIPs also demonstrates notable zero-shot performance with highly reduced computational cost without seeing any caption during the bootstrapping procedure. In addition, CLIP-bootstrapped SparseFormers, which align the output space with language without seeing a word, can serve as efficient vision encoders in multimodal large language models. Code will be publicly available at https://github.com/showlab/sparseformer
SparseFormer: Sparse Visual Recognition via Limited Latent Tokens
Apr 07, 2023



Human visual recognition is a sparse process, where only a few salient visual cues are attended to rather than traversing every detail uniformly. However, most current vision networks follow a dense paradigm, processing every single visual unit (e.g,, pixel or patch) in a uniform manner. In this paper, we challenge this dense paradigm and present a new method, coined SparseFormer, to imitate human's sparse visual recognition in an end-to-end manner. SparseFormer learns to represent images using a highly limited number of tokens (down to 49) in the latent space with sparse feature sampling procedure instead of processing dense units in the original pixel space. Therefore, SparseFormer circumvents most of dense operations on the image space and has much lower computational costs. Experiments on the ImageNet classification benchmark dataset show that SparseFormer achieves performance on par with canonical or well-established models while offering better accuracy-throughput tradeoff. Moreover, the design of our network can be easily extended to the video classification with promising performance at lower computational costs. We hope that our work can provide an alternative way for visual modeling and inspire further research on sparse neural architectures. The code will be publicly available at https://github.com/showlab/sparseformer
STMixer: A One-Stage Sparse Action Detector
Mar 28, 2023Traditional video action detectors typically adopt the two-stage pipeline, where a person detector is first employed to generate actor boxes and then 3D RoIAlign is used to extract actor-specific features for classification. This detection paradigm requires multi-stage training and inference, and cannot capture context information outside the bounding box. Recently, a few query-based action detectors are proposed to predict action instances in an end-to-end manner. However, they still lack adaptability in feature sampling and decoding, thus suffering from the issues of inferior performance or slower convergence. In this paper, we propose a new one-stage sparse action detector, termed STMixer. STMixer is based on two core designs. First, we present a query-based adaptive feature sampling module, which endows our STMixer with the flexibility of mining a set of discriminative features from the entire spatiotemporal domain. Second, we devise a dual-branch feature mixing module, which allows our STMixer to dynamically attend to and mix video features along the spatial and the temporal dimension respectively for better feature decoding. Coupling these two designs with a video backbone yields an efficient end-to-end action detector. Without bells and whistles, our STMixer obtains the state-of-the-art results on the datasets of AVA, UCF101-24, and JHMDB.
AdaMixer: A Fast-Converging Query-Based Object Detector
Mar 31, 2022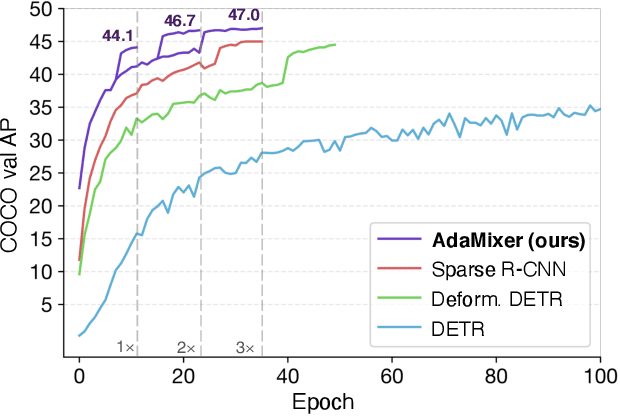


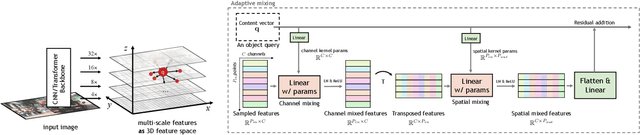
Traditional object detectors employ the dense paradigm of scanning over locations and scales in an image. The recent query-based object detectors break this convention by decoding image features with a set of learnable queries. However, this paradigm still suffers from slow convergence, limited performance, and design complexity of extra networks between backbone and decoder. In this paper, we find that the key to these issues is the adaptability of decoders for casting queries to varying objects. Accordingly, we propose a fast-converging query-based detector, named AdaMixer, by improving the adaptability of query-based decoding processes in two aspects. First, each query adaptively samples features over space and scales based on estimated offsets, which allows AdaMixer to efficiently attend to the coherent regions of objects. Then, we dynamically decode these sampled features with an adaptive MLP-Mixer under the guidance of each query. Thanks to these two critical designs, AdaMixer enjoys architectural simplicity without requiring dense attentional encoders or explicit pyramid networks. On the challenging MS COCO benchmark, AdaMixer with ResNet-50 as the backbone, with 12 training epochs, reaches up to 45.0 AP on the validation set along with 27.9 APs in detecting small objects. With the longer training scheme, AdaMixer with ResNeXt-101-DCN and Swin-S reaches 49.5 and 51.3 AP. Our work sheds light on a simple, accurate, and fast converging architecture for query-based object detectors. The code is made available at https://github.com/MCG-NJU/AdaMixer