 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoLLM-online: Online Video Large Language Model for Streaming Video
Jun 17, 2024
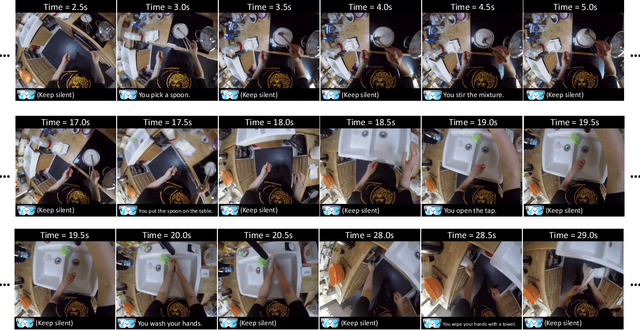
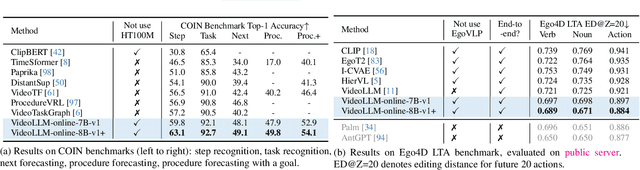
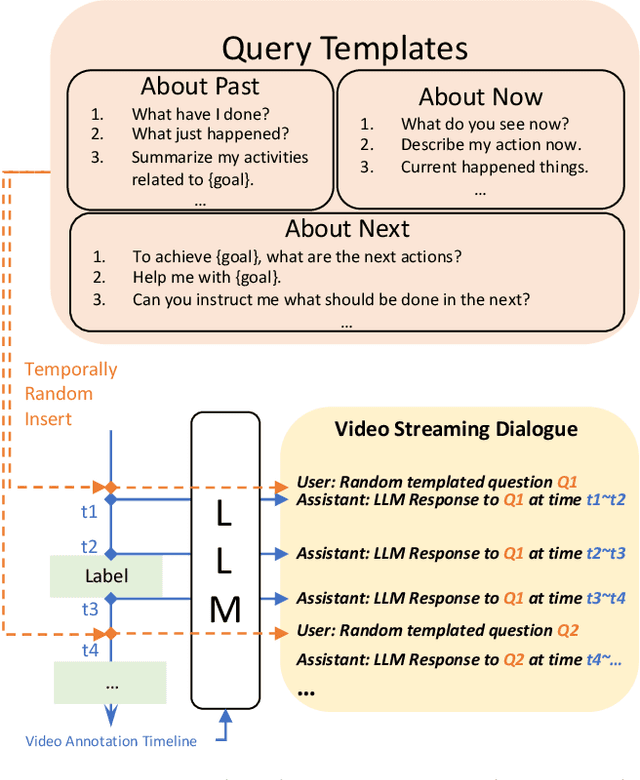
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.