 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySpeech-100: A Large-Scale Benchmark for Speech Understanding Across 100+ Languages and Dialects
May 31, 2026While End-to-End (E2E) Speech-Large Language Models (Speech-LLMs) are rapidly evolving, their evaluation methodologies remain limited to the era of simple transcription. Existing benchmarks suffer from three critical limitations: a pronounced bias towards high-resource languages, a focus on low-level recognition (ASR) rather than semantic reasoning, and a neglect of regional dialects. To bridge this gap, we introduce PolySpeech-100, a massive-scale benchmark designed to assess `native-level' speech comprehension across 110 linguistic variants. We employ a novel hybrid construction pipeline that augments gold-standard human recordings with instruction-driven synthetic speech, allowing us to cover 19 distinct Chinese dialects and over 80 low-resource languages. Extensive evaluation of 22 state-of-the-art models (including Gemini-3, GPT-Audio, and Qwen2.5-Omni) yields pivotal insights. First, we demonstrate that open-source E2E models outperform Cascade (ASR+LLM) systems on heavy dialects, proving that direct audio processing preserves critical paralinguistic cues and prosodic features (e.g., intonation, stress) that are often lost in standard transcription. Second, we reveal a significant performance gap: while commercial models maintain robustness, open-source models suffer catastrophic degradation on low-resource languages. Finally, counter-intuitively, we observe that under standard zero-shot settings, Chain-of-Thought prompting frequently degrades speech understanding performance for most evaluated models, revealing a potential modality alignment gap in current architectures. PolySpeech-100 establishes a rigorous standard for the next generation of inclusive, omni-capable Speech-LLMs. The data, demo, and code are publicly available at https://github.com/YoungSeng/PolySpeech-100.
ActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning
Apr 10, 2026Recent advances in Multimodal Large Language Models (MLLMs) have created new opportunities for facial expression recognition (FER), moving it beyond pure label prediction toward reasoning-based affect understanding. However, existing MLLM-based FER methods still follow a passive paradigm: they rely on externally prepared facial inputs and perform single-pass reasoning over fixed visual evidence, without the capability for active facial perception. To address this limitation, we propose ActFER, an agentic framework that reformulates FER as active visual evidence acquisition followed by multimodal reasoning. Specifically, ActFER dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units (AUs) and emotions through a visual Chain-of-Thought. To realize such behavior, we further develop Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm tailored to agentic FER. UC-GRPO uses AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation to enable sample-aware dynamic credit assignment for local inspection, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies. This algorithm enables ActFER to learn both when local inspection is beneficial and how to reason over the acquired evidence. Comprehensive experiments show that ActFER trained with UC-GRPO consistently outperforms passive MLLM-based FER baselines and substantially improves AU prediction accuracy.
Beyond Token Eviction: Mixed-Dimension Budget Allocation for Efficient KV Cache Compression
Mar 21, 2026Key-value (KV) caching is widely used to accelerate transformer inference, but its memory cost grows linearly with input length, limiting long-context deployment. Existing token eviction methods reduce memory by discarding less important tokens, which can be viewed as a coarse form of dimensionality reduction that assigns each token either zero or full dimension. We propose MixedDimKV, a mixed-dimension KV cache compression method that allocates dimensions to tokens at a more granular level, and MixedDimKV-H, which further integrates head-level importance information. Experiments on long-context benchmarks show that MixedDimKV outperforms prior KV cache compression methods that do not rely on head-level importance profiling. When equipped with the same head-level importance information, MixedDimKV-H consistently outperforms HeadKV. Notably, our approach achieves comparable performance to full attention on LongBench with only 6.25% of the KV cache. Furthermore, in the Needle-in-a-Haystack test, our solution maintains 100% accuracy at a 50K context length while using as little as 0.26% of the cache.
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Nov 26, 2024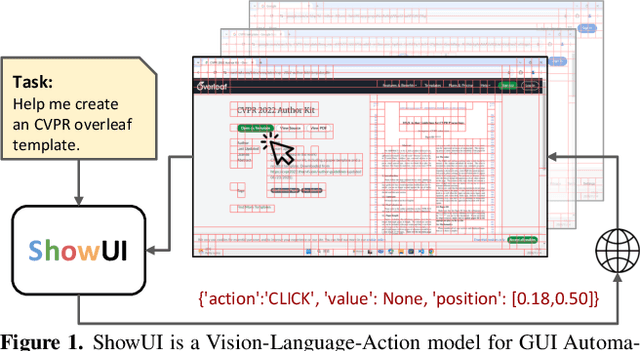
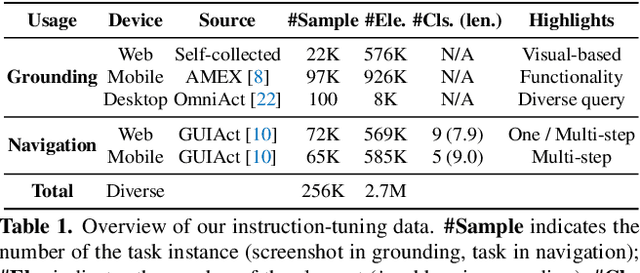
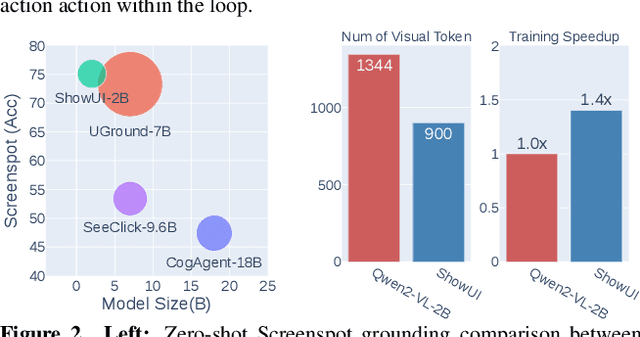
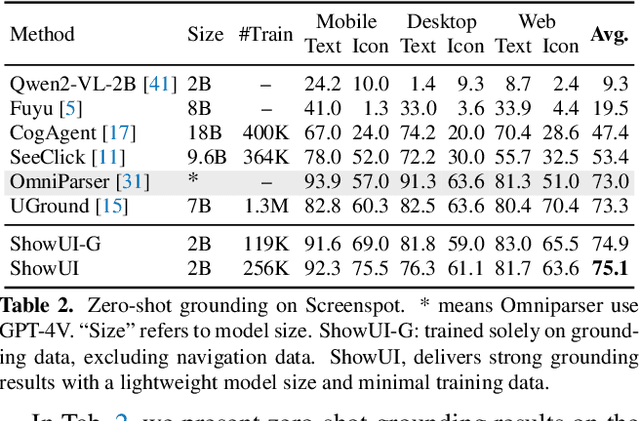
Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents. In this work, we develop a vision-language-action model in digital world, namely ShowUI, which features the following innovations: (i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks; (ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency; (iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x. Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents. The models are available at https://github.com/showlab/ShowUI.
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
Aug 29, 2024



A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens "skipping layers" rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately \textasciitilde42\% time and \textasciitilde30\% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization
Aug 06, 2024The rapid increase in multimedia data has spurred advancements in Multimodal Summarization with Multimodal Output (MSMO), which aims to produce a multimodal summary that integrates both text and relevant images. The inherent heterogeneity of content within multimodal inputs and outputs presents a significant challenge to the execution of MSMO. Traditional approaches typically adopt a holistic perspective on coarse image-text data or individual visual objects, overlooking the essential connections between objects and the entities they represent. To integrate the fine-grained entity knowledge, we propose an Entity-Guided Multimodal Summarization model (EGMS). Our model, building on BART, utilizes dual multimodal encoders with shared weights to process text-image and entity-image information concurrently. A gating mechanism then combines visual data for enhanced textual summary generation, while image selection is refined through knowledge distillation from a pre-trained vision-language model. Extensive experiments on public MSMO dataset validate the superiority of the EGMS method, which also prove the necessity to incorporate entity information into MSMO problem.
VideoLLM-online: Online Video Large Language Model for Streaming Video
Jun 17, 2024
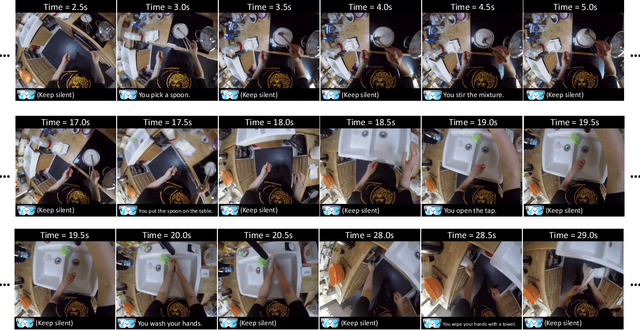
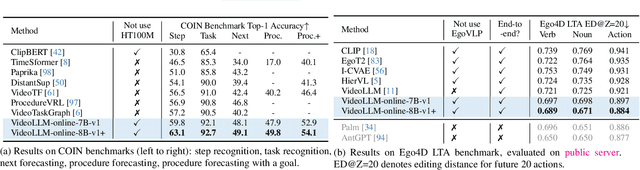
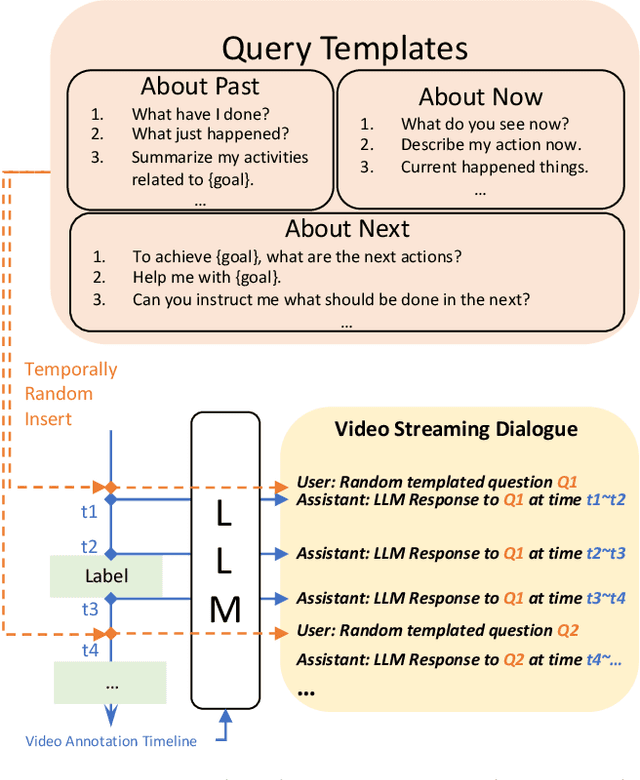
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
From a Social Cognitive Perspective: Context-aware Visual Social Relationship Recognition
Jun 12, 2024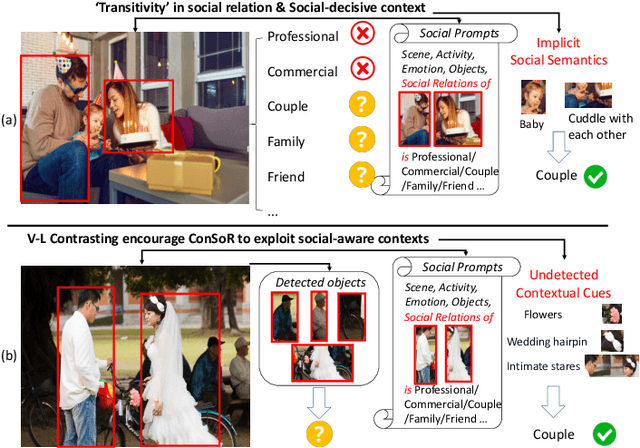



People's social relationships are often manifested through their surroundings, with certain objects or interactions acting as symbols for specific relationships, e.g., wedding rings, roses, hugs, or holding hands. This brings unique challenges to recognizing social relationships, requiring understanding and capturing the essence of these contexts from visual appearances. However, current methods of social relationship understanding rely on the basic classification paradigm of detected persons and objects, which fails to understand the comprehensive context and often overlooks decisive social factors, especially subtle visual cues. To highlight the social-aware context and intricate details, we propose a novel approach that recognizes \textbf{Con}textual \textbf{So}cial \textbf{R}elationships (\textbf{ConSoR}) from a social cognitive perspective. Specifically, to incorporate social-aware semantics, we build a lightweight adapter upon the frozen CLIP to learn social concepts via our novel multi-modal side adapter tuning mechanism. Further, we construct social-aware descriptive language prompts (e.g., scene, activity, objects, emotions) with social relationships for each image, and then compel ConSoR to concentrate more intensively on the decisive visual social factors via visual-linguistic contrasting. Impressively, ConSoR outperforms previous methods with a 12.2\% gain on the People-in-Social-Context (PISC) dataset and a 9.8\% increase on the People-in-Photo-Album (PIPA) benchmark. Furthermore, we observe that ConSoR excels at finding critical visual evidence to reveal social relationships.
NoteLLM-2: Multimodal Large Representation Models for Recommendation
May 27, 2024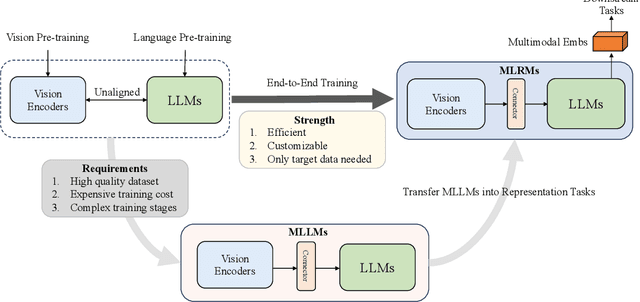
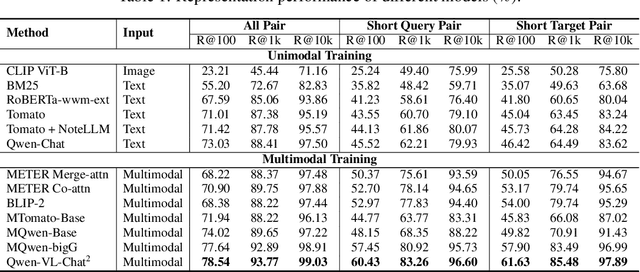
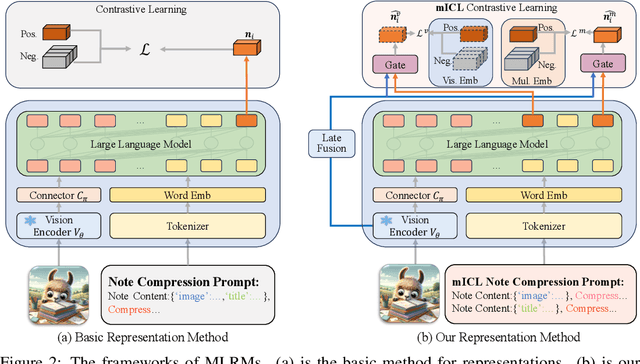
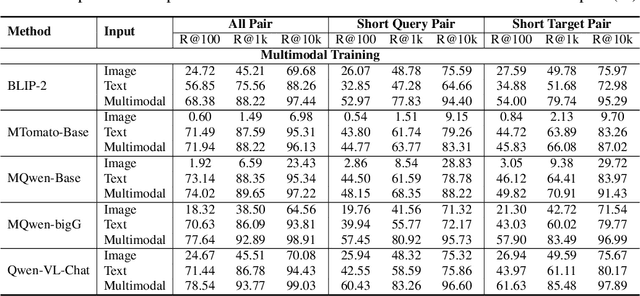
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
NoteLLM: A Retrievable Large Language Model for Note Recommendation
Mar 04, 2024



People enjoy sharing "notes" including their experiences within online communities. Therefore, recommending notes aligned with user interests has become a crucial task. Existing online methods only input notes into BERT-based models to generate note embeddings for assessing similarity. However, they may underutilize some important cues, e.g., hashtags or categories, which represent the key concepts of notes. Indeed, learning to generate hashtags/categories can potentially enhance note embeddings, both of which compress key note information into limited content. Besides, Large Language Models (LLMs) have significantly outperformed BERT in understanding natural languages. It is promising to introduce LLMs into note recommendation. In this paper, we propose a novel unified framework called NoteLLM, which leverages LLMs to address the item-to-item (I2I) note recommendation. Specifically, we utilize Note Compression Prompt to compress a note into a single special token, and further learn the potentially related notes' embeddings via a contrastive learning approach. Moreover, we use NoteLLM to summarize the note and generate the hashtag/category automatically through instruction tuning. Extensive validations on real scenarios demonstrate the effectiveness of our proposed method compared with the online baseline and show major improvements in the recommendation system of Xiaohongshu.