 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
ReInAgent: A Context-Aware GUI Agent Enabling Human-in-the-Loop Mobile Task Navigation
Oct 09, 2025



Mobile GUI agents exhibit substantial potential to facilitate and automate the execution of user tasks on mobile phones. However, exist mobile GUI agents predominantly privilege autonomous operation and neglect the necessity of active user engagement during task execution. This omission undermines their adaptability to information dilemmas including ambiguous, dynamically evolving, and conflicting task scenarios, leading to execution outcomes that deviate from genuine user requirements and preferences. To address these shortcomings, we propose ReInAgent, a context-aware multi-agent framework that leverages dynamic information management to enable human-in-the-loop mobile task navigation. ReInAgent integrates three specialized agents around a shared memory module: an information-managing agent for slot-based information management and proactive interaction with the user, a decision-making agent for conflict-aware planning, and a reflecting agent for task reflection and information consistency validation. Through continuous contextual information analysis and sustained user-agent collaboration, ReInAgent overcomes the limitation of existing approaches that rely on clear and static task assumptions. Consequently, it enables more adaptive and reliable mobile task navigation in complex, real-world scenarios. Experimental results demonstrate that ReInAgent effectively resolves information dilemmas and produces outcomes that are more closely aligned with genuine user preferences. Notably, on complex tasks involving information dilemmas, ReInAgent achieves a 25% higher success rate than Mobile-Agent-v2.
Bridging the Last Mile of Prediction: Enhancing Time Series Forecasting with Conditional Guided Flow Matching
Jul 09, 2025Diffusion models, a type of generative model, have shown promise in time series forecasting. But they face limitations like rigid source distributions and limited sampling paths, which hinder their performance. Flow matching offers faster generation, higher-quality outputs, and greater flexibility, while also possessing the ability to utilize valuable information from the prediction errors of prior models, which were previously inaccessible yet critically important. To address these challenges and fully unlock the untapped potential of flow matching, we propose Conditional Guided Flow Matching (CGFM). CGFM extends flow matching by incorporating the outputs of an auxiliary model, enabling a previously unattainable capability in the field: learning from the errors of the auxiliary model. For time series forecasting tasks, it integrates historical data as conditions and guidance, constructs two-sided conditional probability paths, and uses a general affine path to expand the space of probability paths, ultimately leading to improved predictions. Extensive experiments show that CGFM consistently enhances and outperforms state-of-the-art models, highlighting its effectiveness in advancing forecasting methods.
Attention Mechanisms Perspective: Exploring LLM Processing of Graph-Structured Data
May 04, 2025Attention mechanisms are critical to the success of large language models (LLMs), driving significant advancements in multiple fields. However, for graph-structured data, which requires emphasis on topological connections, they fall short compared to message-passing mechanisms on fixed links, such as those employed by Graph Neural Networks (GNNs). This raises a question: ``Does attention fail for graphs in natural language settings?'' Motivated by these observations, we embarked on an empirical study from the perspective of attention mechanisms to explore how LLMs process graph-structured data. The goal is to gain deeper insights into the attention behavior of LLMs over graph structures. We uncovered unique phenomena regarding how LLMs apply attention to graph-structured data and analyzed these findings to improve the modeling of such data by LLMs. The primary findings of our research are: 1) While LLMs can recognize graph data and capture text-node interactions, they struggle to model inter-node relationships within graph structures due to inherent architectural constraints. 2) The attention distribution of LLMs across graph nodes does not align with ideal structural patterns, indicating a failure to adapt to graph topology nuances. 3) Neither fully connected attention nor fixed connectivity is optimal; each has specific limitations in its application scenarios. Instead, intermediate-state attention windows improve LLM training performance and seamlessly transition to fully connected windows during inference. Source code: \href{https://github.com/millioniron/LLM_exploration}{LLM4Exploration}
Instruct-of-Reflection: Enhancing Large Language Models Iterative Reflection Capabilities via Dynamic-Meta Instruction
Mar 02, 2025



Self-reflection for Large Language Models (LLMs) has gained significant attention. Existing approaches involve models iterating and improving their previous responses based on LLMs' internal reflection ability or external feedback. However, recent research has raised doubts about whether intrinsic self-correction without external feedback may even degrade performance. Based on our empirical evidence, we find that current static reflection methods may lead to redundant, drift, and stubborn issues. To mitigate this, we introduce Instruct-of-Reflection (IoRT), a novel and general reflection framework that leverages dynamic-meta instruction to enhance the iterative reflection capability of LLMs. Specifically, we propose the instructor driven by the meta-thoughts and self-consistency classifier, generates various instructions, including refresh, stop, and select, to guide the next reflection iteration. Our experiments demonstrate that IoRT achieves an average improvement of 10.1% over established baselines in mathematical and commonsense reasoning tasks, highlighting its efficacy and applicability.
GANPrompt: Enhancing Robustness in LLM-Based Recommendations with GAN-Enhanced Diversity Prompts
Aug 19, 2024


In recent years, LLM has demonstrated remarkable proficiency in comprehending and generating natural language, with a growing prevalence in the domain of recommender systems. However, LLM continues to face a significant challenge in that it is highly susceptible to the influence of prompt words. This inconsistency in response to minor alterations in prompt input may compromise the accuracy and resilience of recommendation models. To address this issue, this paper proposes GANPrompt, a multi-dimensional large language model prompt diversity framework based on Generative Adversarial Networks (GANs). The framework enhances the model's adaptability and stability to diverse prompts by integrating GAN generation techniques with the deep semantic understanding capabilities of LLMs. GANPrompt first trains a generator capable of producing diverse prompts by analysing multidimensional user behavioural data. These diverse prompts are then used to train the LLM to improve its performance in the face of unseen prompts. Furthermore, to ensure a high degree of diversity and relevance of the prompts, this study introduces a mathematical theory-based diversity constraint mechanism that optimises the generated prompts to ensure that they are not only superficially distinct, but also semantically cover a wide range of user intentions. Through extensive experiments on multiple datasets, we demonstrate the effectiveness of the proposed framework, especially in improving the adaptability and robustness of recommender systems in complex and dynamic environments. The experimental results demonstrate that GANPrompt yields substantial enhancements in accuracy and robustness relative to existing state-of-the-art methodologies.
An Efficient Continuous Control Perspective for Reinforcement-Learning-based Sequential Recommendation
Aug 15, 2024Sequential recommendation, where user preference is dynamically inferred from sequential historical behaviors, is a critical task in recommender systems (RSs). To further optimize long-term user engagement, offline reinforcement-learning-based RSs have become a mainstream technique as they provide an additional advantage in avoiding global explorations that may harm online users' experiences. However, previous studies mainly focus on discrete action and policy spaces, which might have difficulties in handling dramatically growing items efficiently. To mitigate this issue, in this paper, we aim to design an algorithmic framework applicable to continuous policies. To facilitate the control in the low-dimensional but dense user preference space, we propose an \underline{\textbf{E}}fficient \underline{\textbf{Co}}ntinuous \underline{\textbf{C}}ontrol framework (ECoC). Based on a statistically tested assumption, we first propose the novel unified action representation abstracted from normalized user and item spaces. Then, we develop the corresponding policy evaluation and policy improvement procedures. During this process, strategic exploration and directional control in terms of unified actions are carefully designed and crucial to final recommendation decisions. Moreover, beneficial from unified actions, the conservatism regularization for policies and value functions are combined and perfectly compatible with the continuous framework. The resulting dual regularization ensures the successful offline training of RL-based recommendation policies. Finally, we conduct extensive experiments to validate the effectiveness of our framework. The results show that compared to the discrete baselines, our ECoC is trained far more efficiently. Meanwhile, the final policies outperform baselines in both capturing the offline data and gaining long-term rewards.
LANE: Logic Alignment of Non-tuning Large Language Models and Online Recommendation Systems for Explainable Reason Generation
Jul 03, 2024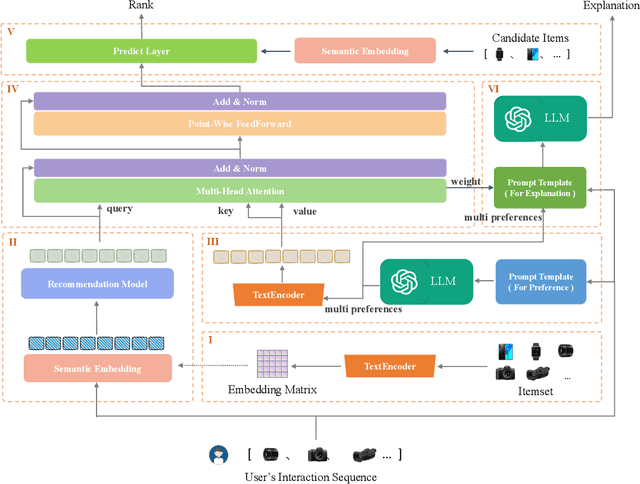
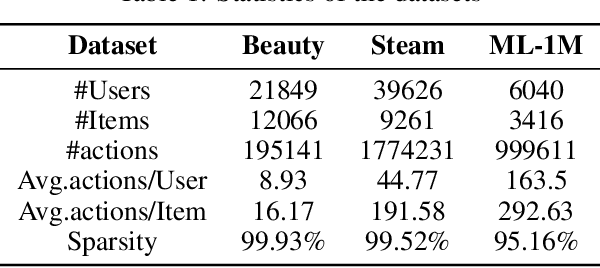

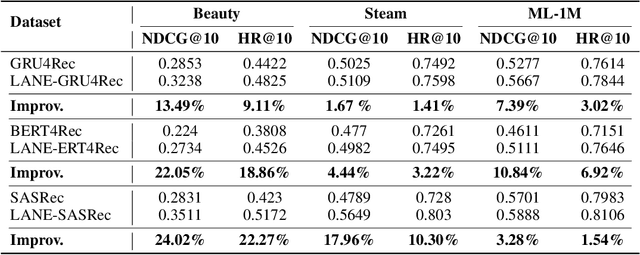
The explainability of recommendation systems is crucial for enhancing user trust and satisfaction. Leveraging large language models (LLMs) offers new opportunities for comprehensive recommendation logic generation. However, in existing related studies, fine-tuning LLM models for recommendation tasks incurs high computational costs and alignment issues with existing systems, limiting the application potential of proven proprietary/closed-source LLM models, such as GPT-4. In this work, our proposed effective strategy LANE aligns LLMs with online recommendation systems without additional LLMs tuning, reducing costs and improving explainability. This innovative approach addresses key challenges in integrating language models with recommendation systems while fully utilizing the capabilities of powerful proprietary models. Specifically, our strategy operates through several key components: semantic embedding, user multi-preference extraction using zero-shot prompting, semantic alignment, and explainable recommendation generation using Chain of Thought (CoT) prompting. By embedding item titles instead of IDs and utilizing multi-head attention mechanisms, our approach aligns the semantic features of user preferences with those of candidate items, ensuring coherent and user-aligned recommendations. Sufficient experimental results including performance comparison, questionnaire voting, and visualization cases prove that our method can not only ensure recommendation performance, but also provide easy-to-understand and reasonable recommendation logic.
LangTopo: Aligning Language Descriptions of Graphs with Tokenized Topological Modeling
Jun 19, 2024Recently, large language models (LLMs) have been widely researched in the field of graph machine learning due to their outstanding abilities in language comprehension and learning. However, the significant gap between natural language tasks and topological structure modeling poses a nonnegligible challenge. Specifically, since natural language descriptions are not sufficient for LLMs to understand and process graph-structured data, fine-tuned LLMs perform even worse than some traditional GNN models on graph tasks, lacking inherent modeling capabilities for graph structures. Existing research overly emphasizes LLMs' understanding of semantic information captured by external models, while inadequately exploring graph topological structure modeling, thereby overlooking the genuine capabilities that LLMs lack. Consequently, in this paper, we introduce a new framework, LangTopo, which aligns graph structure modeling with natural language understanding at the token level. LangTopo quantifies the graph structure modeling capabilities of GNNs and LLMs by constructing a codebook for the graph modality and performs consistency maximization. This process aligns the text description of LLM with the topological modeling of GNN, allowing LLM to learn the ability of GNN to capture graph structures, enabling LLM to handle graph-structured data independently. We demonstrate the effectiveness of our proposed method on multiple datasets.
Enhancing Collaborative Semantics of Language Model-Driven Recommendations via Graph-Aware Learning
Jun 19, 2024



Large Language Models (LLMs) are increasingly prominent in the recommendation systems domain. Existing studies usually utilize in-context learning or supervised fine-tuning on task-specific data to align LLMs into recommendations. However, the substantial bias in semantic spaces between language processing tasks and recommendation tasks poses a nonnegligible challenge. Specifically, without the adequate capturing ability of collaborative information, existing modeling paradigms struggle to capture behavior patterns within community groups, leading to LLMs' ineffectiveness in discerning implicit interaction semantic in recommendation scenarios. To address this, we consider enhancing the learning capability of language model-driven recommendation models for structured data, specifically by utilizing interaction graphs rich in collaborative semantics. We propose a Graph-Aware Learning for Language Model-Driven Recommendations (GAL-Rec). GAL-Rec enhances the understanding of user-item collaborative semantics by imitating the intent of Graph Neural Networks (GNNs) to aggregate multi-hop information, thereby fully exploiting the substantial learning capacity of LLMs to independently address the complex graphs in the recommendation system. Sufficient experimental results on three real-world datasets demonstrate that GAL-Rec significantly enhances the comprehension of collaborative semantics, and improves recommendation performance.