 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Pre-Training and Customized Prompt Learning for Efficient Multi-Behavior Sequential Recommendation
Aug 21, 2024

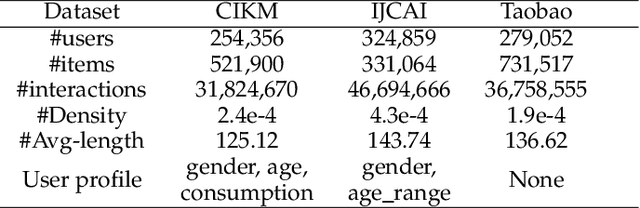
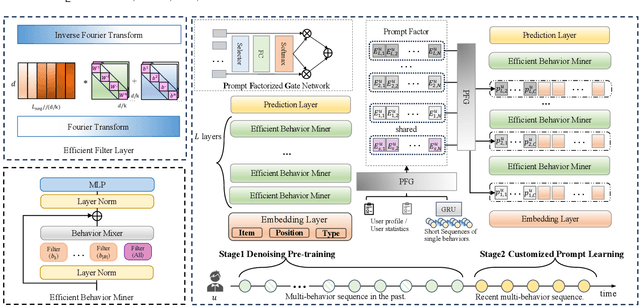
In the realm of recommendation systems, users exhibit a diverse array of behaviors when interacting with items. This phenomenon has spurred research into learning the implicit semantic relationships between these behaviors to enhance recommendation performance. However, these methods often entail high computational complexity. To address concerns regarding efficiency, pre-training presents a viable solution. Its objective is to extract knowledge from extensive pre-training data and fine-tune the model for downstream tasks. Nevertheless, previous pre-training methods have primarily focused on single-behavior data, while multi-behavior data contains significant noise. Additionally, the fully fine-tuning strategy adopted by these methods still imposes a considerable computational burden. In response to this challenge, we propose DPCPL, the first pre-training and prompt-tuning paradigm tailored for Multi-Behavior Sequential Recommendation. Specifically, in the pre-training stage, we commence by proposing a novel Efficient Behavior Miner (EBM) to filter out the noise at multiple time scales, thereby facilitating the comprehension of the contextual semantics of multi-behavior sequences. Subsequently, we propose to tune the pre-trained model in a highly efficient manner with the proposed Customized Prompt Learning (CPL) module, which generates personalized, progressive, and diverse prompts to fully exploit the potential of the pre-trained model effectively. Extensive experiments on three real-world datasets have unequivocally demonstrated that DPCPL not only exhibits high efficiency and effectiveness, requiring minimal parameter adjustments but also surpasses the state-of-the-art performance across a diverse range of downstream tasks.
A Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation
Mar 30, 2024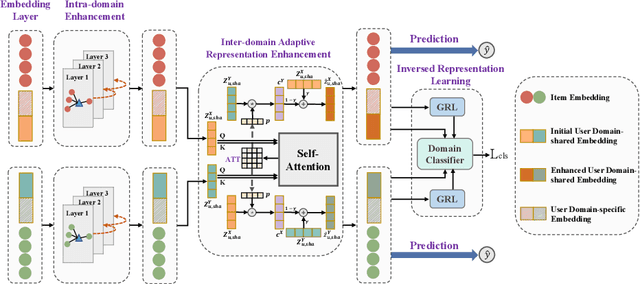
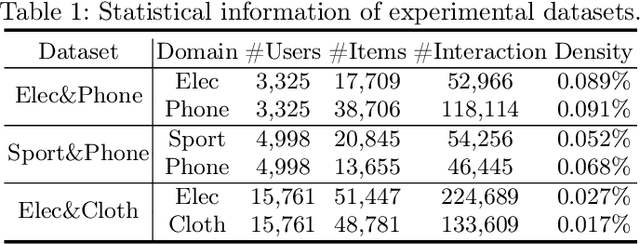
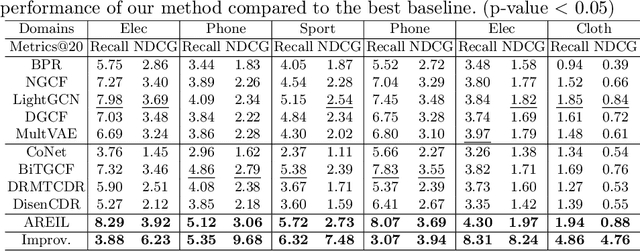
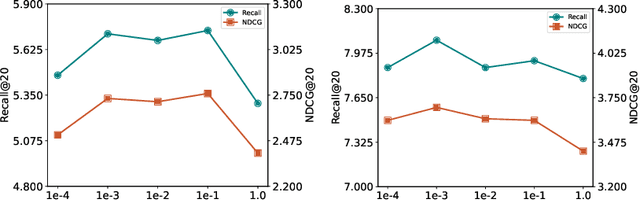
Cross-domain recommendation (CDR), aiming to extract and transfer knowledge across domains, has attracted wide attention for its efficacy in addressing data sparsity and cold-start problems. Despite significant advances in representation disentanglement to capture diverse user preferences, existing methods usually neglect representation enhancement and lack rigorous decoupling constraints, thereby limiting the transfer of relevant information. To this end, we propose a Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation (AREIL). Specifically, we first divide user embeddings into domain-shared and domain-specific components to disentangle mixed user preferences. Then, we incorporate intra-domain and inter-domain information to adaptively enhance the ability of user representations. In particular, we propose a graph convolution module to capture high-order information, and a self-attention module to reveal inter-domain correlations and accomplish adaptive fusion. Next, we adopt domain classifiers and gradient reversal layers to achieve inversed representation learning in a unified framework. Finally, we employ a cross-entropy loss for measuring recommendation performance and jointly optimize the entire framework via multi-task learning. Extensive experiments on multiple datasets validate the substantial improvement in the recommendation performance of AREIL. Moreover, ablation studies and representation visualizations further illustrate the effectiveness of adaptive enhancement and inversed learning in CDR.
END4Rec: Efficient Noise-Decoupling for Multi-Behavior Sequential Recommendation
Mar 26, 2024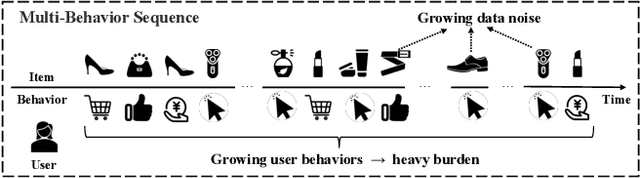
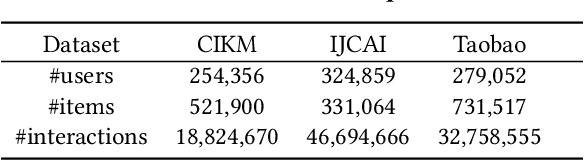
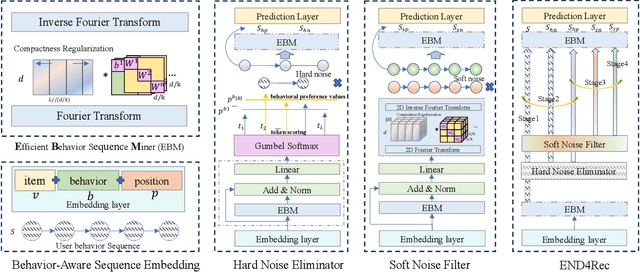
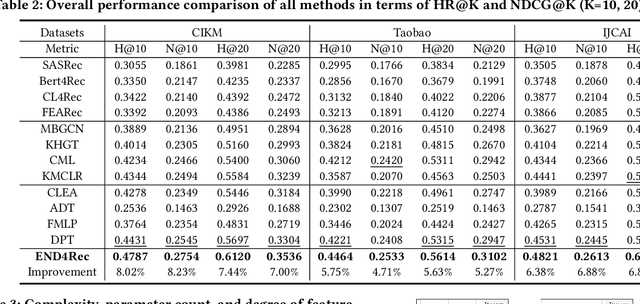
In recommendation systems, users frequently engage in multiple types of behaviors, such as clicking, adding to a cart, and purchasing. However, with diversified behavior data, user behavior sequences will become very long in the short term, which brings challenges to the efficiency of the sequence recommendation model. Meanwhile, some behavior data will also bring inevitable noise to the modeling of user interests. To address the aforementioned issues, firstly, we develop the Efficient Behavior Sequence Miner (EBM) that efficiently captures intricate patterns in user behavior while maintaining low time complexity and parameter count. Secondly, we design hard and soft denoising modules for different noise types and fully explore the relationship between behaviors and noise. Finally, we introduce a contrastive loss function along with a guided training strategy to compare the valid information in the data with the noisy signal, and seamlessly integrate the two denoising processes to achieve a high degree of decoupling of the noisy signal. Sufficient experiments on real-world datasets demonstrate the effectiveness and efficiency of our approach in dealing with multi-behavior sequential recommendation.
GUESR: A Global Unsupervised Data-Enhancement with Bucket-Cluster Sampling for Sequential Recommendation
Mar 01, 2023



Sequential Recommendation is a widely studied paradigm for learning users' dynamic interests from historical interactions for predicting the next potential item. Although lots of research work has achieved remarkable progress, they are still plagued by the common issues: data sparsity of limited supervised signals and data noise of accidentally clicking. To this end, several works have attempted to address these issues, which ignored the complex association of items across several sequences. Along this line, with the aim of learning representative item embedding to alleviate this dilemma, we propose GUESR, from the view of graph contrastive learning. Specifically, we first construct the Global Item Relationship Graph (GIRG) from all interaction sequences and present the Bucket-Cluster Sampling (BCS) method to conduct the sub-graphs. Then, graph contrastive learning on this reduced graph is developed to enhance item representations with complex associations from the global view. We subsequently extend the CapsNet module with the elaborately introduced target-attention mechanism to derive users' dynamic preferences. Extensive experimental results have demonstrated our proposed GUESR could not only achieve significant improvements but also could be regarded as a general enhancement strategy to improve the performance in combination with other sequential recommendation methods.