 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIET: Learning to Distill Dataset Continually for Recommender Systems
Mar 26, 2026Modern deep recommender models are trained under a continual learning paradigm, relying on massive and continuously growing streaming behavioral logs. In large-scale platforms, retraining models on full historical data for architecture comparison or iteration is prohibitively expensive, severely slowing down model development. This challenge calls for data-efficient approaches that can faithfully approximate full-data training behavior without repeatedly processing the entire evolving data stream. We formulate this problem as \emph{streaming dataset distillation for recommender systems} and propose \textbf{DIET}, a unified framework that maintains a compact distilled dataset which evolves alongside streaming data while preserving training-critical signals. Unlike existing dataset distillation methods that construct a static distilled set, DIET models distilled data as an evolving training memory and updates it in a stage-wise manner to remain aligned with long-term training dynamics. DIET enables effective continual distillation through principled initialization from influential samples and selective updates guided by influence-aware memory addressing within a bi-level optimization framework. Experiments on large-scale recommendation benchmarks demonstrate that DIET compresses training data to as little as \textbf{1-2\%} of the original size while preserving performance trends consistent with full-data training, reducing model iteration cost by up to \textbf{60$\times$}. Moreover, the distilled datasets produced by DIET generalize well across different model architectures, highlighting streaming dataset distillation as a scalable and reusable data foundation for recommender system development.
Generative Data Transformation: From Mixed to Unified Data
Feb 26, 2026Recommendation model performance is intrinsically tied to the quality, volume, and relevance of their training data. To address common challenges like data sparsity and cold start, recent researchs have leveraged data from multiple auxiliary domains to enrich information within the target domain. However, inherent domain gaps can degrade the quality of mixed-domain data, leading to negative transfer and diminished model performance. Existing prevailing \emph{model-centric} paradigm -- which relies on complex, customized architectures -- struggles to capture the subtle, non-structural sequence dependencies across domains, leading to poor generalization and high demands on computational resources. To address these shortcomings, we propose \textsc{Taesar}, a \emph{data-centric} framework for \textbf{t}arget-\textbf{a}lign\textbf{e}d \textbf{s}equenti\textbf{a}l \textbf{r}egeneration, which employs a contrastive decoding mechanism to adaptively encode cross-domain context into target-domain sequences. It employs contrastive decoding to encode cross-domain context into target sequences, enabling standard models to learn intricate dependencies without complex fusion architectures. Experiments show \textsc{Taesar} outperforms model-centric solutions and generalizes to various sequential models. By generating enriched datasets, \textsc{Taesar} effectively combines the strengths of data- and model-centric paradigms. The code accompanying this paper is available at~ \textcolor{blue}{https://github.com/USTC-StarTeam/Taesar}.
ToolGym: an Open-world Tool-using Environment for Scalable Agent Testing and Data Curation
Jan 09, 2026Tool-using LLM agents still struggle in open-world settings with large tool pools, long-horizon objectives, wild constraints, and unreliable tool states. For scalable and realistic training and testing, we introduce an open-world tool-using environment, built on 5,571 format unified tools across 204 commonly used apps. It includes a task creation engine that synthesizes long-horizon, multi-tool workflows with wild constraints, and a state controller that injects interruptions and failures to stress-test robustness. On top of this environment, we develop a tool select-then-execute agent framework with a planner-actor decomposition to separate deliberate reasoning and self-correction from step-wise execution. Comprehensive evaluation of state-of-the-art LLMs reveals the misalignment between tool planning and execution abilities, the constraint following weakness of existing LLMs, and DeepSeek-v3.2's strongest robustness. Finally, we collect 1,170 trajectories from our environment to fine-tune LLMs, achieving superior performance to baselines using 119k samples, indicating the environment's value as both a realistic benchmark and a data engine for tool-using agents. Our code and data will be publicly released.
Quantifying Circadian Desynchrony in ICU Patients and Its Association with Delirium
Mar 11, 2025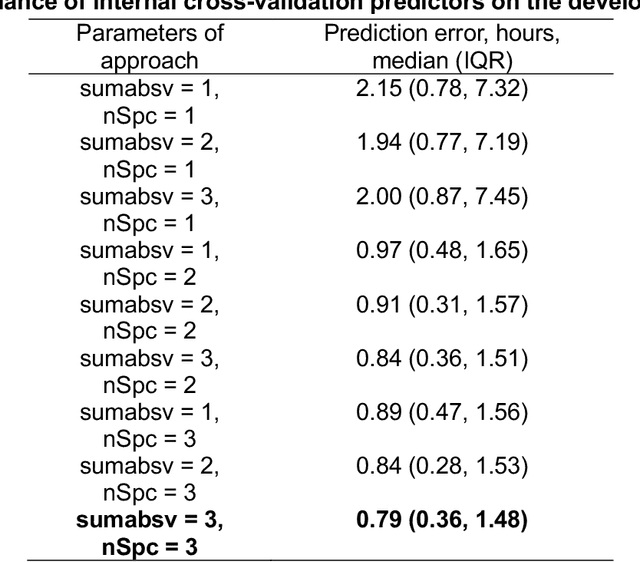
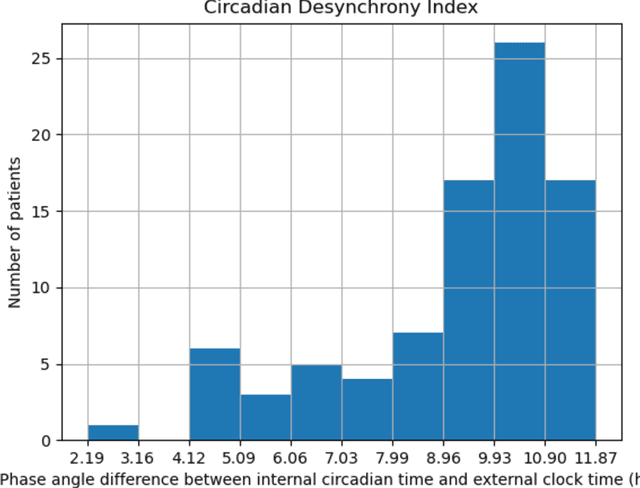


Background: Circadian desynchrony characterized by the misalignment between an individual's internal biological rhythms and external environmental cues, significantly affects various physiological processes and health outcomes. Quantifying circadian desynchrony often requires prolonged and frequent monitoring, and currently, an easy tool for this purpose is missing. Additionally, its association with the incidence of delirium has not been clearly explored. Methods: A prospective observational study was carried out in intensive care units (ICU) of a tertiary hospital. Circadian transcriptomics of blood monocytes from 86 individuals were collected on two consecutive days, although a second sample could not be obtained from all participants. Using two public datasets comprised of healthy volunteers, we replicated a model for determining internal circadian time. We developed an approach to quantify circadian desynchrony by comparing internal circadian time and external blood collection time. We applied the model and quantified circadian desynchrony index among ICU patients, and investigated its association with the incidence of delirium. Results: The replicated model for determining internal circadian time achieved comparable high accuracy. The quantified circadian desynchrony index was significantly higher among critically ill ICU patients compared to healthy subjects, with values of 10.03 hours vs 2.50-2.95 hours (p < 0.001). Most ICU patients had a circadian desynchrony index greater than 9 hours. Additionally, the index was lower in patients whose blood samples were drawn after 3pm, with values of 5.00 hours compared to 10.01-10.90 hours in other groups (p < 0.001)...
M$^3$amba: CLIP-driven Mamba Model for Multi-modal Remote Sensing Classification
Mar 09, 2025Multi-modal fusion holds great promise for integrating information from different modalities. However, due to a lack of consideration for modal consistency, existing multi-modal fusion methods in the field of remote sensing still face challenges of incomplete semantic information and low computational efficiency in their fusion designs. Inspired by the observation that the visual language pre-training model CLIP can effectively extract strong semantic information from visual features, we propose M$^3$amba, a novel end-to-end CLIP-driven Mamba model for multi-modal fusion to address these challenges. Specifically, we introduce CLIP-driven modality-specific adapters in the fusion architecture to avoid the bias of understanding specific domains caused by direct inference, making the original CLIP encoder modality-specific perception. This unified framework enables minimal training to achieve a comprehensive semantic understanding of different modalities, thereby guiding cross-modal feature fusion. To further enhance the consistent association between modality mappings, a multi-modal Mamba fusion architecture with linear complexity and a cross-attention module Cross-SS2D are designed, which fully considers effective and efficient information interaction to achieve complete fusion. Extensive experiments have shown that M$^3$amba has an average performance improvement of at least 5.98\% compared with the state-of-the-art methods in multi-modal hyperspectral image classification tasks in the remote sensing field, while also demonstrating excellent training efficiency, achieving a double improvement in accuracy and efficiency. The code is released at https://github.com/kaka-Cao/M3amba.
MANDARIN: Mixture-of-Experts Framework for Dynamic Delirium and Coma Prediction in ICU Patients: Development and Validation of an Acute Brain Dysfunction Prediction Model
Mar 08, 2025Acute brain dysfunction (ABD) is a common, severe ICU complication, presenting as delirium or coma and leading to prolonged stays, increased mortality, and cognitive decline. Traditional screening tools like the Glasgow Coma Scale (GCS), Confusion Assessment Method (CAM), and Richmond Agitation-Sedation Scale (RASS) rely on intermittent assessments, causing delays and inconsistencies. In this study, we propose MANDARIN (Mixture-of-Experts Framework for Dynamic Delirium and Coma Prediction in ICU Patients), a 1.5M-parameter mixture-of-experts neural network to predict ABD in real-time among ICU patients. The model integrates temporal and static data from the ICU to predict the brain status in the next 12 to 72 hours, using a multi-branch approach to account for current brain status. The MANDARIN model was trained on data from 92,734 patients (132,997 ICU admissions) from 2 hospitals between 2008-2019 and validated externally on data from 11,719 patients (14,519 ICU admissions) from 15 hospitals and prospectively on data from 304 patients (503 ICU admissions) from one hospital in 2021-2024. Three datasets were used: the University of Florida Health (UFH) dataset, the electronic ICU Collaborative Research Database (eICU), and the Medical Information Mart for Intensive Care (MIMIC)-IV dataset. MANDARIN significantly outperforms the baseline neurological assessment scores (GCS, CAM, and RASS) for delirium prediction in both external (AUROC 75.5% CI: 74.2%-76.8% vs 68.3% CI: 66.9%-69.5%) and prospective (AUROC 82.0% CI: 74.8%-89.2% vs 72.7% CI: 65.5%-81.0%) cohorts, as well as for coma prediction (external AUROC 87.3% CI: 85.9%-89.0% vs 72.8% CI: 70.6%-74.9%, and prospective AUROC 93.4% CI: 88.5%-97.9% vs 67.7% CI: 57.7%-76.8%) with a 12-hour lead time. This tool has the potential to assist clinicians in decision-making by continuously monitoring the brain status of patients in the ICU.
TD3: Tucker Decomposition Based Dataset Distillation Method for Sequential Recommendation
Feb 06, 2025



In the era of data-centric AI, the focus of recommender systems has shifted from model-centric innovations to data-centric approaches. The success of modern AI models is built on large-scale datasets, but this also results in significant training costs. Dataset distillation has emerged as a key solution, condensing large datasets to accelerate model training while preserving model performance. However, condensing discrete and sequentially correlated user-item interactions, particularly with extensive item sets, presents considerable challenges. This paper introduces \textbf{TD3}, a novel \textbf{T}ucker \textbf{D}ecomposition based \textbf{D}ataset \textbf{D}istillation method within a meta-learning framework, designed for sequential recommendation. TD3 distills a fully expressive \emph{synthetic sequence summary} from original data. To efficiently reduce computational complexity and extract refined latent patterns, Tucker decomposition decouples the summary into four factors: \emph{synthetic user latent factor}, \emph{temporal dynamics latent factor}, \emph{shared item latent factor}, and a \emph{relation core} that models their interconnections. Additionally, a surrogate objective in bi-level optimization is proposed to align feature spaces extracted from models trained on both original data and synthetic sequence summary beyond the na\"ive performance matching approach. In the \emph{inner-loop}, an augmentation technique allows the learner to closely fit the synthetic summary, ensuring an accurate update of it in the \emph{outer-loop}. To accelerate the optimization process and address long dependencies, RaT-BPTT is employed for bi-level optimization. Experiments and analyses on multiple public datasets have confirmed the superiority and cross-architecture generalizability of the proposed designs. Codes are released at https://github.com/USTC-StarTeam/TD3.
MANGO: Multimodal Acuity traNsformer for intelliGent ICU Outcomes
Dec 13, 2024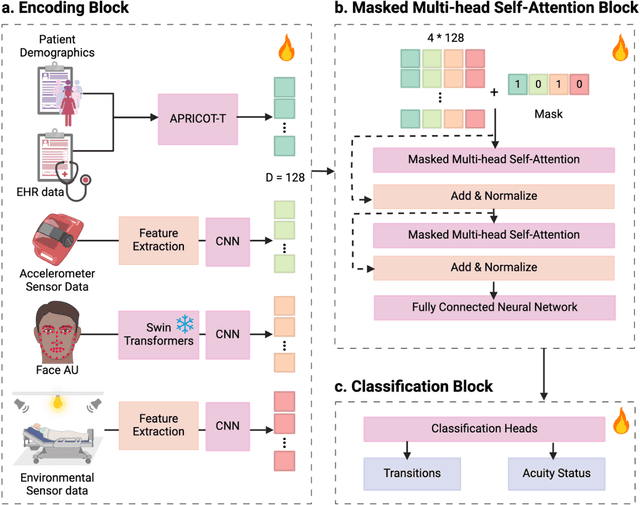
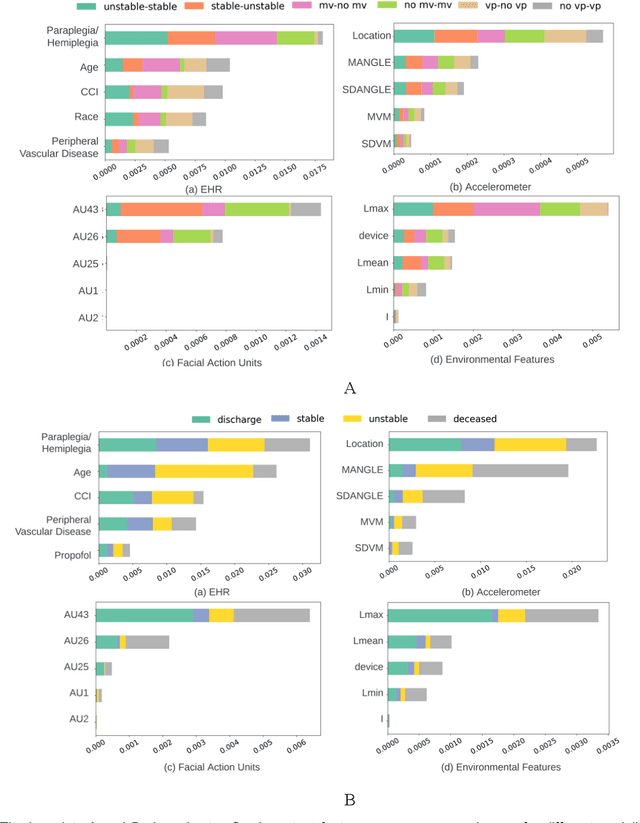
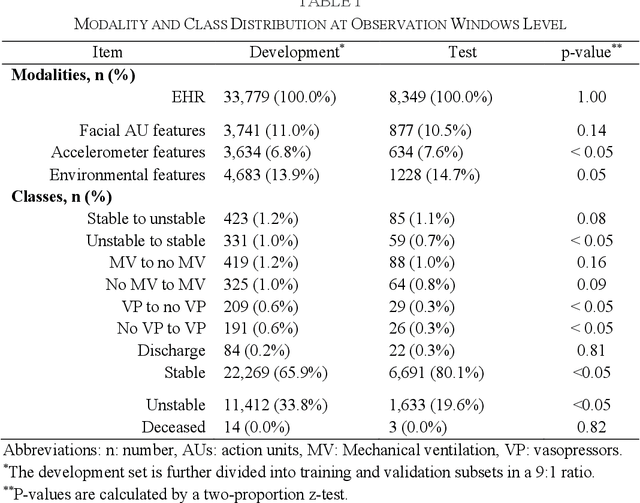

Estimation of patient acuity in the Intensive Care Unit (ICU) is vital to ensure timely and appropriate interventions. Advances in artificial intelligence (AI) technologies have significantly improved the accuracy of acuity predictions. However, prior studies using machine learning for acuity prediction have predominantly relied on electronic health records (EHR) data, often overlooking other critical aspects of ICU stay, such as patient mobility, environmental factors, and facial cues indicating pain or agitation. To address this gap, we present MANGO: the Multimodal Acuity traNsformer for intelliGent ICU Outcomes, designed to enhance the prediction of patient acuity states, transitions, and the need for life-sustaining therapy. We collected a multimodal dataset ICU-Multimodal, incorporating four key modalities, EHR data, wearable sensor data, video of patient's facial cues, and ambient sensor data, which we utilized to train MANGO. The MANGO model employs a multimodal feature fusion network powered by Transformer masked self-attention method, enabling it to capture and learn complex interactions across these diverse data modalities even when some modalities are absent. Our results demonstrated that integrating multiple modalities significantly improved the model's ability to predict acuity status, transitions, and the need for life-sustaining therapy. The best-performing models achieved an area under the receiver operating characteristic curve (AUROC) of 0.76 (95% CI: 0.72-0.79) for predicting transitions in acuity status and the need for life-sustaining therapy, while 0.82 (95% CI: 0.69-0.89) for acuity status prediction...
DiffCLIP: Few-shot Language-driven Multimodal Classifier
Dec 10, 2024



Visual language models like Contrastive Language-Image Pretraining (CLIP) have shown impressive performance in analyzing natural images with language information. However, these models often encounter challenges when applied to specialized domains such as remote sensing due to the limited availability of image-text pairs for training. To tackle this issue, we introduce DiffCLIP, a novel framework that extends CLIP to effectively convey comprehensive language-driven semantic information for accurate classification of high-dimensional multimodal remote sensing images. DiffCLIP is a few-shot learning method that leverages unlabeled images for pretraining. It employs unsupervised mask diffusion learning to capture the distribution of diverse modalities without requiring labels. The modality-shared image encoder maps multimodal data into a unified subspace, extracting shared features with consistent parameters across modalities. A well-trained image encoder further enhances learning by aligning visual representations with class-label text information from CLIP. By integrating these approaches, DiffCLIP significantly boosts CLIP performance using a minimal number of image-text pairs. We evaluate DiffCLIP on widely used high-dimensional multimodal datasets, demonstrating its effectiveness in addressing few-shot annotated classification tasks. DiffCLIP achieves an overall accuracy improvement of 10.65% across three remote sensing datasets compared with CLIP, while utilizing only 2-shot image-text pairs. The code has been released at https://github.com/icey-zhang/DiffCLIP.
Peri-AIIMS: Perioperative Artificial Intelligence Driven Integrated Modeling of Surgeries using Anesthetic, Physical and Cognitive Statuses for Predicting Hospital Outcomes
Oct 29, 2024



The association between preoperative cognitive status and surgical outcomes is a critical, yet scarcely explored area of research. Linking intraoperative data with postoperative outcomes is a promising and low-cost way of evaluating long-term impacts of surgical interventions. In this study, we evaluated how preoperative cognitive status as measured by the clock drawing test contributed to predicting length of hospital stay, hospital charges, average pain experienced during follow-up, and 1-year mortality over and above intraoperative variables, demographics, preoperative physical status and comorbidities. We expanded our analysis to 6 specific surgical groups where sufficient data was available for cross-validation. The clock drawing images were represented by 10 constructional features discovered by a semi-supervised deep learning algorithm, previously validated to differentiate between dementia and non-dementia patients. Different machine learning models were trained to classify postoperative outcomes in hold-out test sets. The models were compared to their relative performance, time complexity, and interpretability. Shapley Additive Explanations (SHAP) analysis was used to find the most predictive features for classifying different outcomes in different surgical contexts. Relative classification performances achieved by different feature sets showed that the perioperative cognitive dataset which included clock drawing features in addition to intraoperative variables, demographics, and comorbidities served as the best dataset for 12 of 18 possible surgery-outcome combinations...