 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaDATE: Remedy Dual-Attention Transformer with Semantic Alignment via Contrast Learning for Multimodal Object Detection
Paper and Code
Oct 15, 2024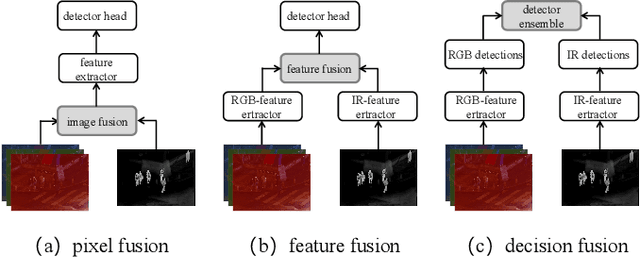
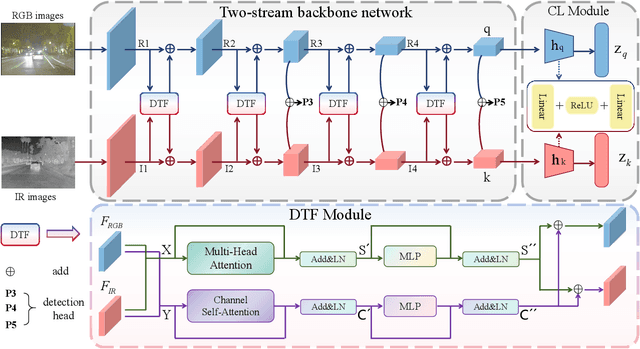
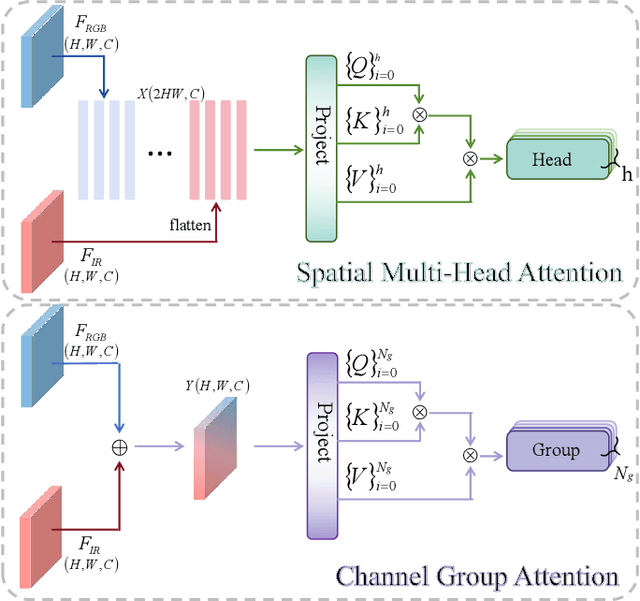
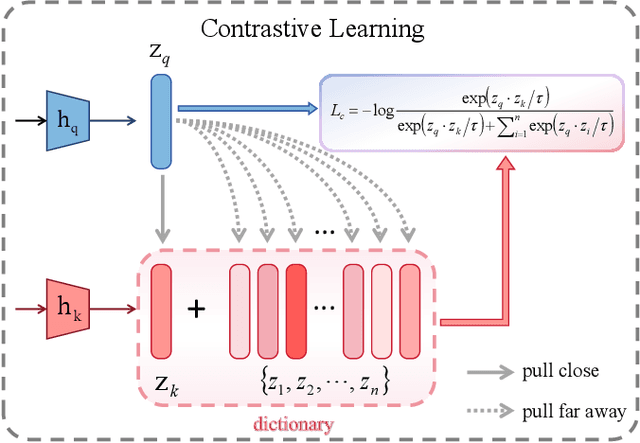
Multimodal object detection leverages diverse modal information to enhance the accuracy and robustness of detectors. By learning long-term dependencies, Transformer can effectively integrate multimodal features in the feature extraction stage, which greatly improves the performance of multimodal object detection. However, current methods merely stack Transformer-guided fusion techniques without exploring their capability to extract features at various depth layers of network, thus limiting the improvements in detection performance. In this paper, we introduce an accurate and efficient object detection method named SeaDATE. Initially, we propose a novel dual attention Feature Fusion (DTF) module that, under Transformer's guidance, integrates local and global information through a dual attention mechanism, strengthening the fusion of modal features from orthogonal perspectives using spatial and channel tokens. Meanwhile, our theoretical analysis and empirical validation demonstrate that the Transformer-guided fusion method, treating images as sequences of pixels for fusion, performs better on shallow features' detail information compared to deep semantic information. To address this, we designed a contrastive learning (CL) module aimed at learning features of multimodal samples, remedying the shortcomings of Transformer-guided fusion in extracting deep semantic features, and effectively utilizing cross-modal information. Extensive experiments and ablation studies on the FLIR, LLVIP, and M3FD datasets have proven our method to be effective, achieving state-of-the-art detection performance.