 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionCom: Structure-Aware Multimodal Diffusion Model for Multimodal Knowledge Graph Completion
Apr 09, 2025Most current MKGC approaches are predominantly based on discriminative models that maximize conditional likelihood. These approaches struggle to efficiently capture the complex connections in real-world knowledge graphs, thereby limiting their overall performance. To address this issue, we propose a structure-aware multimodal Diffusion model for multimodal knowledge graph Completion (DiffusionCom). DiffusionCom innovatively approaches the problem from the perspective of generative models, modeling the association between the $(head, relation)$ pair and candidate tail entities as their joint probability distribution $p((head, relation), (tail))$, and framing the MKGC task as a process of gradually generating the joint probability distribution from noise. Furthermore, to fully leverage the structural information in MKGs, we propose Structure-MKGformer, an adaptive and structure-aware multimodal knowledge representation learning method, as the encoder for DiffusionCom. Structure-MKGformer captures rich structural information through a multimodal graph attention network (MGAT) and adaptively fuses it with entity representations, thereby enhancing the structural awareness of these representations. This design effectively addresses the limitations of existing MKGC methods, particularly those based on multimodal pre-trained models, in utilizing structural information. DiffusionCom is trained using both generative and discriminative losses for the generator, while the feature extractor is optimized exclusively with discriminative loss. This dual approach allows DiffusionCom to harness the strengths of both generative and discriminative models. Extensive experiments on the FB15k-237-IMG and WN18-IMG datasets demonstrate that DiffusionCom outperforms state-of-the-art models.
TD3: Tucker Decomposition Based Dataset Distillation Method for Sequential Recommendation
Feb 06, 2025



In the era of data-centric AI, the focus of recommender systems has shifted from model-centric innovations to data-centric approaches. The success of modern AI models is built on large-scale datasets, but this also results in significant training costs. Dataset distillation has emerged as a key solution, condensing large datasets to accelerate model training while preserving model performance. However, condensing discrete and sequentially correlated user-item interactions, particularly with extensive item sets, presents considerable challenges. This paper introduces \textbf{TD3}, a novel \textbf{T}ucker \textbf{D}ecomposition based \textbf{D}ataset \textbf{D}istillation method within a meta-learning framework, designed for sequential recommendation. TD3 distills a fully expressive \emph{synthetic sequence summary} from original data. To efficiently reduce computational complexity and extract refined latent patterns, Tucker decomposition decouples the summary into four factors: \emph{synthetic user latent factor}, \emph{temporal dynamics latent factor}, \emph{shared item latent factor}, and a \emph{relation core} that models their interconnections. Additionally, a surrogate objective in bi-level optimization is proposed to align feature spaces extracted from models trained on both original data and synthetic sequence summary beyond the na\"ive performance matching approach. In the \emph{inner-loop}, an augmentation technique allows the learner to closely fit the synthetic summary, ensuring an accurate update of it in the \emph{outer-loop}. To accelerate the optimization process and address long dependencies, RaT-BPTT is employed for bi-level optimization. Experiments and analyses on multiple public datasets have confirmed the superiority and cross-architecture generalizability of the proposed designs. Codes are released at https://github.com/USTC-StarTeam/TD3.
Rethinking Byzantine Robustness in Federated Recommendation from Sparse Aggregation Perspective
Jan 08, 2025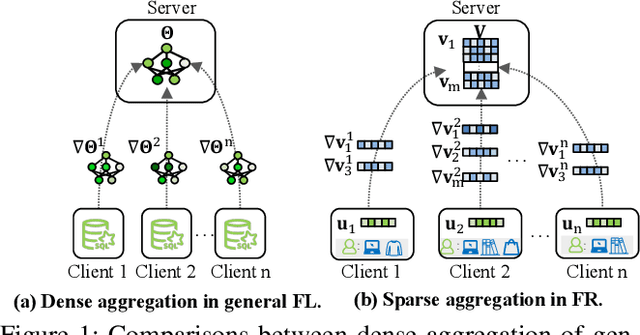

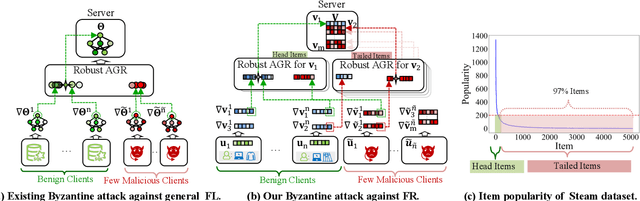
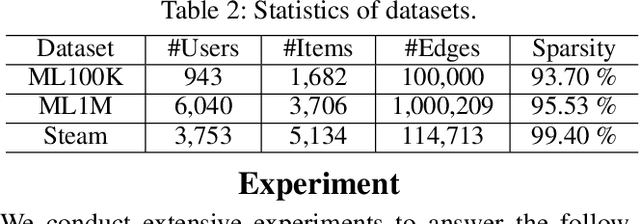
To preserve user privacy in recommender systems, federated recommendation (FR) based on federated learning (FL) emerges, keeping the personal data on the local client and updating a model collaboratively. Unlike FL, FR has a unique sparse aggregation mechanism, where the embedding of each item is updated by only partial clients, instead of full clients in a dense aggregation of general FL. Recently, as an essential principle of FL, model security has received increasing attention, especially for Byzantine attacks, where malicious clients can send arbitrary updates. The problem of exploring the Byzantine robustness of FR is particularly critical since in the domains applying FR, e.g., e-commerce, malicious clients can be injected easily by registering new accounts. However, existing Byzantine works neglect the unique sparse aggregation of FR, making them unsuitable for our problem. Thus, we make the first effort to investigate Byzantine attacks on FR from the perspective of sparse aggregation, which is non-trivial: it is not clear how to define Byzantine robustness under sparse aggregations and design Byzantine attacks under limited knowledge/capability. In this paper, we reformulate the Byzantine robustness under sparse aggregation by defining the aggregation for a single item as the smallest execution unit. Then we propose a family of effective attack strategies, named Spattack, which exploit the vulnerability in sparse aggregation and are categorized along the adversary's knowledge and capability. Extensive experimental results demonstrate that Spattack can effectively prevent convergence and even break down defenses under a few malicious clients, raising alarms for securing FR systems.
Minimum Topology Attacks for Graph Neural Networks
Mar 05, 2024



With the great popularity of Graph Neural Networks (GNNs), their robustness to adversarial topology attacks has received significant attention. Although many attack methods have been proposed, they mainly focus on fixed-budget attacks, aiming at finding the most adversarial perturbations within a fixed budget for target node. However, considering the varied robustness of each node, there is an inevitable dilemma caused by the fixed budget, i.e., no successful perturbation is found when the budget is relatively small, while if it is too large, the yielding redundant perturbations will hurt the invisibility. To break this dilemma, we propose a new type of topology attack, named minimum-budget topology attack, aiming to adaptively find the minimum perturbation sufficient for a successful attack on each node. To this end, we propose an attack model, named MiBTack, based on a dynamic projected gradient descent algorithm, which can effectively solve the involving non-convex constraint optimization on discrete topology. Extensive results on three GNNs and four real-world datasets show that MiBTack can successfully lead all target nodes misclassified with the minimum perturbation edges. Moreover, the obtained minimum budget can be used to measure node robustness, so we can explore the relationships of robustness, topology, and uncertainty for nodes, which is beyond what the current fixed-budget topology attacks can offer.
Relation Extraction Model Based on Semantic Enhancement Mechanism
Nov 05, 2023



Relational extraction is one of the basic tasks related to information extraction in the field of natural language processing, and is an important link and core task in the fields of information extraction, natural language understanding, and information retrieval. None of the existing relation extraction methods can effectively solve the problem of triple overlap. The CasAug model proposed in this paper based on the CasRel framework combined with the semantic enhancement mechanism can solve this problem to a certain extent. The CasAug model enhances the semantics of the identified possible subjects by adding a semantic enhancement mechanism, First, based on the semantic coding of possible subjects, pre-classify the possible subjects, and then combine the subject lexicon to calculate the semantic similarity to obtain the similar vocabulary of possible subjects. According to the similar vocabulary obtained, each word in different relations is calculated through the attention mechanism. For the contribution of the possible subject, finally combine the relationship pre-classification results to weight the enhanced semantics of each relationship to find the enhanced semantics of the possible subject, and send the enhanced semantics combined with the possible subject to the object and relationship extraction module. Complete the final relation triplet extraction. The experimental results show that, compared with the baseline model, the CasAug model proposed in this paper has improved the effect of relation extraction, and CasAug's ability to deal with overlapping problems and extract multiple relations is also better than the baseline model, indicating that the semantic enhancement mechanism proposed in this paper It can further reduce the judgment of redundant relations and alleviate the problem of triple overlap.
Topic model based on co-occurrence word networks for unbalanced short text datasets
Nov 05, 2023
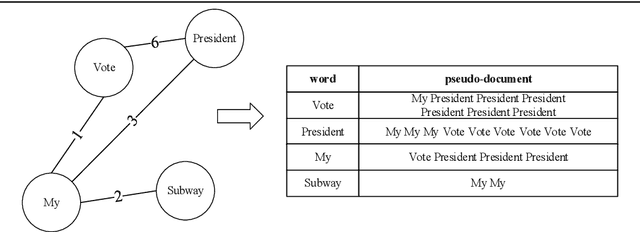
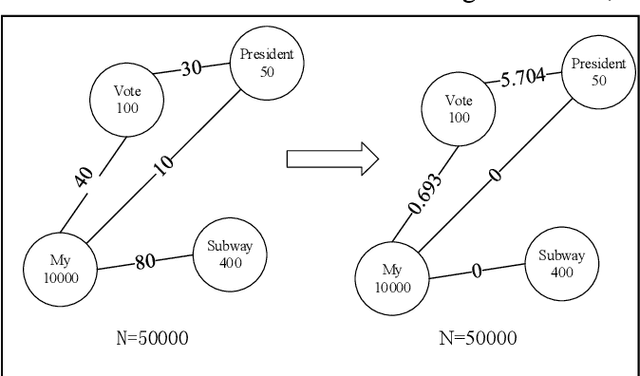
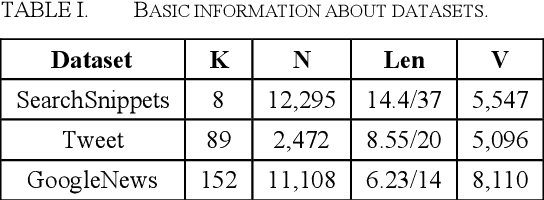
We propose a straightforward solution for detecting scarce topics in unbalanced short-text datasets. Our approach, named CWUTM (Topic model based on co-occurrence word networks for unbalanced short text datasets), Our approach addresses the challenge of sparse and unbalanced short text topics by mitigating the effects of incidental word co-occurrence. This allows our model to prioritize the identification of scarce topics (Low-frequency topics). Unlike previous methods, CWUTM leverages co-occurrence word networks to capture the topic distribution of each word, and we enhanced the sensitivity in identifying scarce topics by redefining the calculation of node activity and normalizing the representation of both scarce and abundant topics to some extent. Moreover, CWUTM adopts Gibbs sampling, similar to LDA, making it easily adaptable to various application scenarios. Our extensive experimental validation on unbalanced short-text datasets demonstrates the superiority of CWUTM compared to baseline approaches in discovering scarce topics. According to the experimental results the proposed model is effective in early and accurate detection of emerging topics or unexpected events on social platforms.
Epidemic Decision-making System Based Federated Reinforcement Learning
Nov 03, 2023



Epidemic decision-making can effectively help the government to comprehensively consider public security and economic development to respond to public health and safety emergencies. Epidemic decision-making can effectively help the government to comprehensively consider public security and economic development to respond to public health and safety emergencies. Some studies have shown that intensive learning can effectively help the government to make epidemic decision, thus achieving the balance between health security and economic development. Some studies have shown that intensive learning can effectively help the government to make epidemic decision, thus achieving the balance between health security and economic development. However, epidemic data often has the characteristics of limited samples and high privacy. However, epidemic data often has the characteristics of limited samples and high privacy. This model can combine the epidemic situation data of various provinces for cooperative training to use as an enhanced learning model for epidemic situation decision, while protecting the privacy of data. The experiment shows that the enhanced federated learning can obtain more optimized performance and return than the enhanced learning, and the enhanced federated learning can also accelerate the training convergence speed of the training model. accelerate the training convergence speed of the client. At the same time, through the experimental comparison, A2C is the most suitable reinforcement learning model for the epidemic situation decision-making. learning model for the epidemic situation decision-making scenario, followed by the PPO model, and the performance of DDPG is unsatisfactory.
Dynamic Fair Federated Learning Based on Reinforcement Learning
Nov 02, 2023



Federated learning enables a collaborative training and optimization of global models among a group of devices without sharing local data samples. However, the heterogeneity of data in federated learning can lead to unfair representation of the global model across different devices. To address the fairness issue in federated learning, we propose a dynamic q fairness federated learning algorithm with reinforcement learning, called DQFFL. DQFFL aims to mitigate the discrepancies in device aggregation and enhance the fairness of treatment for all groups involved in federated learning. To quantify fairness, DQFFL leverages the performance of the global federated model on each device and incorporates {\alpha}-fairness to transform the preservation of fairness during federated aggregation into the distribution of client weights in the aggregation process. Considering the sensitivity of parameters in measuring fairness, we propose to utilize reinforcement learning for dynamic parameters during aggregation. Experimental results demonstrate that our DQFFL outperforms the state-of-the-art methods in terms of overall performance, fairness and convergence speed.
Federated Heterogeneous Graph Neural Network for Privacy-preserving Recommendation
Oct 18, 2023



Heterogeneous information network (HIN), which contains rich semantics depicted by meta-paths, has become a powerful tool to alleviate data sparsity in recommender systems. Existing HIN-based recommendations hold the data centralized storage assumption and conduct centralized model training. However, the real-world data is often stored in a distributed manner for privacy concerns, resulting in the failure of centralized HIN-based recommendations. In this paper, we suggest the HIN is partitioned into private HINs stored in the client side and shared HINs in the server. Following this setting, we propose a federated heterogeneous graph neural network (FedHGNN) based framework, which can collaboratively train a recommendation model on distributed HINs without leaking user privacy. Specifically, we first formalize the privacy definition in the light of differential privacy for HIN-based federated recommendation, which aims to protect user-item interactions of private HIN as well as user's high-order patterns from shared HINs. To recover the broken meta-path based semantics caused by distributed data storage and satisfy the proposed privacy, we elaborately design a semantic-preserving user interactions publishing method, which locally perturbs user's high-order patterns as well as related user-item interactions for publishing. After that, we propose a HGNN model for recommendation, which conducts node- and semantic-level aggregations to capture recovered semantics. Extensive experiments on three datasets demonstrate our model outperforms existing methods by a large margin (up to 34% in HR@10 and 42% in NDCG@10) under an acceptable privacy budget.
Reinforcement Federated Learning Method Based on Adaptive OPTICS Clustering
Jun 23, 2023Federated learning is a distributed machine learning technology, which realizes the balance between data privacy protection and data sharing computing. To protect data privacy, feder-ated learning learns shared models by locally executing distributed training on participating devices and aggregating local models into global models. There is a problem in federated learning, that is, the negative impact caused by the non-independent and identical distribu-tion of data across different user terminals. In order to alleviate this problem, this paper pro-poses a strengthened federation aggregation method based on adaptive OPTICS clustering. Specifically, this method perceives the clustering environment as a Markov decision process, and models the adjustment process of parameter search direction, so as to find the best clus-tering parameters to achieve the best federated aggregation method. The core contribution of this paper is to propose an adaptive OPTICS clustering algorithm for federated learning. The algorithm combines OPTICS clustering and adaptive learning technology, and can effective-ly deal with the problem of non-independent and identically distributed data across different user terminals. By perceiving the clustering environment as a Markov decision process, the goal is to find the best parameters of the OPTICS cluster without artificial assistance, so as to obtain the best federated aggregation method and achieve better performance. The reliability and practicability of this method have been verified on the experimental data, and its effec-tiveness and superiority have been proved.