 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning based on Pruning and Recovery
Mar 16, 2024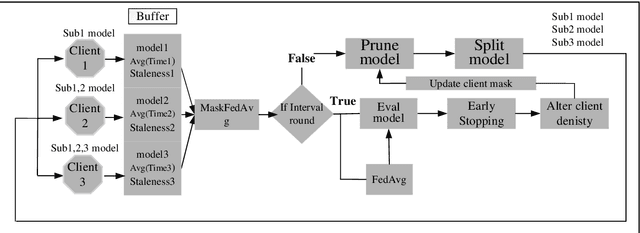
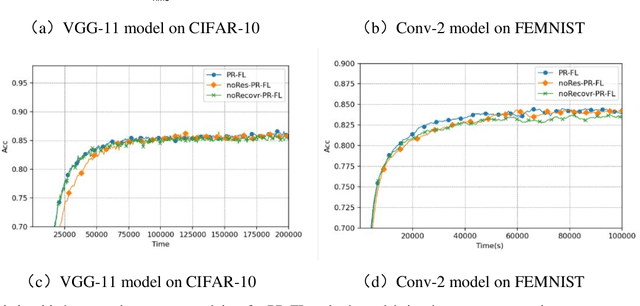
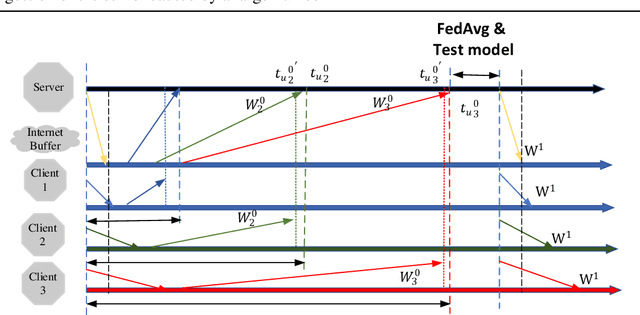
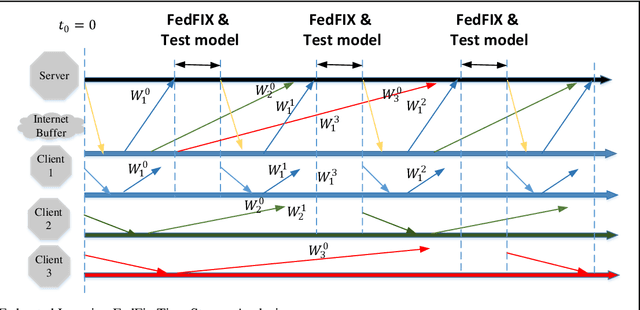
A novel federated learning training framework for heterogeneous environments is presented, taking into account the diverse network speeds of clients in realistic settings. This framework integrates asynchronous learning algorithms and pruning techniques, effectively addressing the inefficiencies of traditional federated learning algorithms in scenarios involving heterogeneous devices, as well as tackling the staleness issue and inadequate training of certain clients in asynchronous algorithms. Through the incremental restoration of model size during training, the framework expedites model training while preserving model accuracy. Furthermore, enhancements to the federated learning aggregation process are introduced, incorporating a buffering mechanism to enable asynchronous federated learning to operate akin to synchronous learning. Additionally, optimizations in the process of the server transmitting the global model to clients reduce communication overhead. Our experiments across various datasets demonstrate that: (i) significant reductions in training time and improvements in convergence accuracy are achieved compared to conventional asynchronous FL and HeteroFL; (ii) the advantages of our approach are more pronounced in scenarios with heterogeneous clients and non-IID client data.
Topic model based on co-occurrence word networks for unbalanced short text datasets
Nov 05, 2023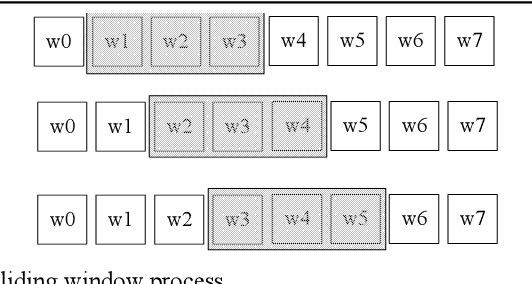
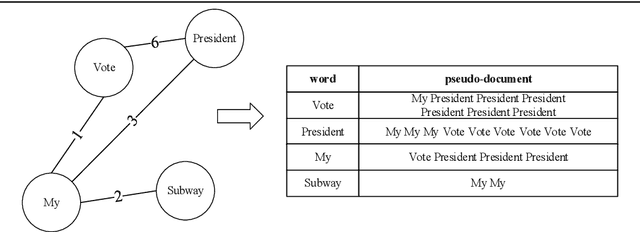
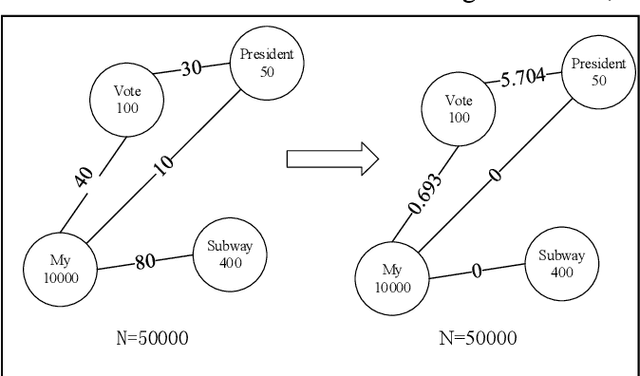
We propose a straightforward solution for detecting scarce topics in unbalanced short-text datasets. Our approach, named CWUTM (Topic model based on co-occurrence word networks for unbalanced short text datasets), Our approach addresses the challenge of sparse and unbalanced short text topics by mitigating the effects of incidental word co-occurrence. This allows our model to prioritize the identification of scarce topics (Low-frequency topics). Unlike previous methods, CWUTM leverages co-occurrence word networks to capture the topic distribution of each word, and we enhanced the sensitivity in identifying scarce topics by redefining the calculation of node activity and normalizing the representation of both scarce and abundant topics to some extent. Moreover, CWUTM adopts Gibbs sampling, similar to LDA, making it easily adaptable to various application scenarios. Our extensive experimental validation on unbalanced short-text datasets demonstrates the superiority of CWUTM compared to baseline approaches in discovering scarce topics. According to the experimental results the proposed model is effective in early and accurate detection of emerging topics or unexpected events on social platforms.
Federated Topic Model and Model Pruning Based on Variational Autoencoder
Nov 01, 2023Topic modeling has emerged as a valuable tool for discovering patterns and topics within large collections of documents. However, when cross-analysis involves multiple parties, data privacy becomes a critical concern. Federated topic modeling has been developed to address this issue, allowing multiple parties to jointly train models while protecting pri-vacy. However, there are communication and performance challenges in the federated sce-nario. In order to solve the above problems, this paper proposes a method to establish a federated topic model while ensuring the privacy of each node, and use neural network model pruning to accelerate the model, where the client periodically sends the model neu-ron cumulative gradients and model weights to the server, and the server prunes the model. To address different requirements, two different methods are proposed to determine the model pruning rate. The first method involves slow pruning throughout the entire model training process, which has limited acceleration effect on the model training process, but can ensure that the pruned model achieves higher accuracy. This can significantly reduce the model inference time during the inference process. The second strategy is to quickly reach the target pruning rate in the early stage of model training in order to accelerate the model training speed, and then continue to train the model with a smaller model size after reaching the target pruning rate. This approach may lose more useful information but can complete the model training faster. Experimental results show that the federated topic model pruning based on the variational autoencoder proposed in this paper can greatly accelerate the model training speed while ensuring the model's performance.
* 8 pages
A Rare Topic Discovery Model for Short Texts Based on Co-occurrence word Network
Jun 30, 2022

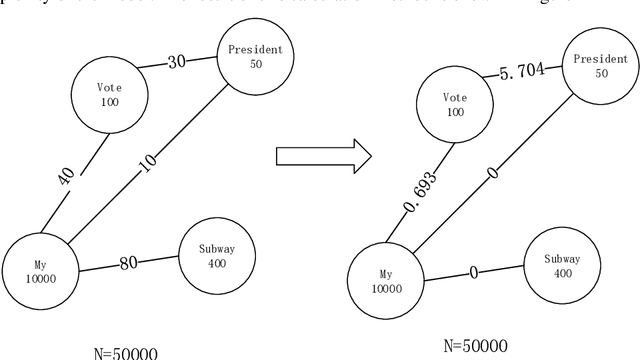

We provide a simple and general solution for the discovery of scarce topics in unbalanced short-text datasets, namely, a word co-occurrence network-based model CWIBTD, which can simultaneously address the sparsity and unbalance of short-text topics and attenuate the effect of occasional pairwise occurrences of words, allowing the model to focus more on the discovery of scarce topics. Unlike previous approaches, CWIBTD uses co-occurrence word networks to model the topic distribution of each word, which improves the semantic density of the data space and ensures its sensitivity in identify-ing rare topics by improving the way node activity is calculated and normal-izing scarce topics and large topics to some extent. In addition, using the same Gibbs sampling as LDA makes CWIBTD easy to be extended to vari-ous application scenarios. Extensive experimental validation in the unbal-anced short text dataset confirms the superiority of CWIBTD over the base-line approach in discovering rare topics. Our model can be used for early and accurate discovery of emerging topics or unexpected events on social platforms.