 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionCom: Structure-Aware Multimodal Diffusion Model for Multimodal Knowledge Graph Completion
Apr 09, 2025Most current MKGC approaches are predominantly based on discriminative models that maximize conditional likelihood. These approaches struggle to efficiently capture the complex connections in real-world knowledge graphs, thereby limiting their overall performance. To address this issue, we propose a structure-aware multimodal Diffusion model for multimodal knowledge graph Completion (DiffusionCom). DiffusionCom innovatively approaches the problem from the perspective of generative models, modeling the association between the $(head, relation)$ pair and candidate tail entities as their joint probability distribution $p((head, relation), (tail))$, and framing the MKGC task as a process of gradually generating the joint probability distribution from noise. Furthermore, to fully leverage the structural information in MKGs, we propose Structure-MKGformer, an adaptive and structure-aware multimodal knowledge representation learning method, as the encoder for DiffusionCom. Structure-MKGformer captures rich structural information through a multimodal graph attention network (MGAT) and adaptively fuses it with entity representations, thereby enhancing the structural awareness of these representations. This design effectively addresses the limitations of existing MKGC methods, particularly those based on multimodal pre-trained models, in utilizing structural information. DiffusionCom is trained using both generative and discriminative losses for the generator, while the feature extractor is optimized exclusively with discriminative loss. This dual approach allows DiffusionCom to harness the strengths of both generative and discriminative models. Extensive experiments on the FB15k-237-IMG and WN18-IMG datasets demonstrate that DiffusionCom outperforms state-of-the-art models.
Relation Extraction Model Based on Semantic Enhancement Mechanism
Nov 05, 2023



Relational extraction is one of the basic tasks related to information extraction in the field of natural language processing, and is an important link and core task in the fields of information extraction, natural language understanding, and information retrieval. None of the existing relation extraction methods can effectively solve the problem of triple overlap. The CasAug model proposed in this paper based on the CasRel framework combined with the semantic enhancement mechanism can solve this problem to a certain extent. The CasAug model enhances the semantics of the identified possible subjects by adding a semantic enhancement mechanism, First, based on the semantic coding of possible subjects, pre-classify the possible subjects, and then combine the subject lexicon to calculate the semantic similarity to obtain the similar vocabulary of possible subjects. According to the similar vocabulary obtained, each word in different relations is calculated through the attention mechanism. For the contribution of the possible subject, finally combine the relationship pre-classification results to weight the enhanced semantics of each relationship to find the enhanced semantics of the possible subject, and send the enhanced semantics combined with the possible subject to the object and relationship extraction module. Complete the final relation triplet extraction. The experimental results show that, compared with the baseline model, the CasAug model proposed in this paper has improved the effect of relation extraction, and CasAug's ability to deal with overlapping problems and extract multiple relations is also better than the baseline model, indicating that the semantic enhancement mechanism proposed in this paper It can further reduce the judgment of redundant relations and alleviate the problem of triple overlap.
Topic model based on co-occurrence word networks for unbalanced short text datasets
Nov 05, 2023
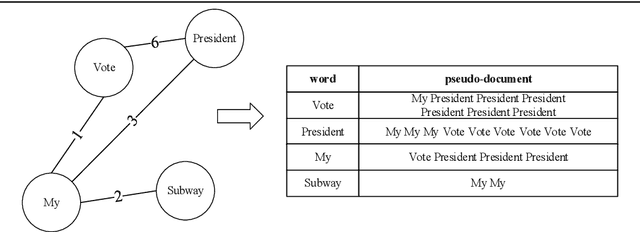
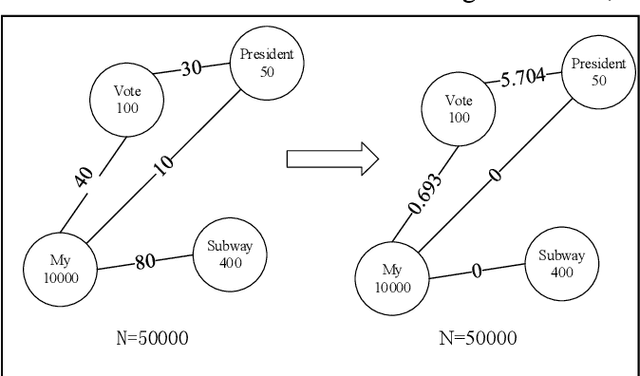
We propose a straightforward solution for detecting scarce topics in unbalanced short-text datasets. Our approach, named CWUTM (Topic model based on co-occurrence word networks for unbalanced short text datasets), Our approach addresses the challenge of sparse and unbalanced short text topics by mitigating the effects of incidental word co-occurrence. This allows our model to prioritize the identification of scarce topics (Low-frequency topics). Unlike previous methods, CWUTM leverages co-occurrence word networks to capture the topic distribution of each word, and we enhanced the sensitivity in identifying scarce topics by redefining the calculation of node activity and normalizing the representation of both scarce and abundant topics to some extent. Moreover, CWUTM adopts Gibbs sampling, similar to LDA, making it easily adaptable to various application scenarios. Our extensive experimental validation on unbalanced short-text datasets demonstrates the superiority of CWUTM compared to baseline approaches in discovering scarce topics. According to the experimental results the proposed model is effective in early and accurate detection of emerging topics or unexpected events on social platforms.
Entity Alignment Method of Science and Technology Patent based on Graph Convolution Network and Information Fusion
Nov 01, 2023



The entity alignment of science and technology patents aims to link the equivalent entities in the knowledge graph of different science and technology patent data sources. Most entity alignment methods only use graph neural network to obtain the embedding of graph structure or use attribute text description to obtain semantic representation, ignoring the process of multi-information fusion in science and technology patents. In order to make use of the graphic structure and auxiliary information such as the name, description and attribute of the patent entity, this paper proposes an entity alignment method based on the graph convolution network for science and technology patent information fusion. Through the graph convolution network and BERT model, the structure information and entity attribute information of the science and technology patent knowledge graph are embedded and represented to achieve multi-information fusion, thus improving the performance of entity alignment. Experiments on three benchmark data sets show that the proposed method Hit@K The evaluation indicators are better than the existing methods.
Semantic Representation Learning of Scientific Literature based on Adaptive Feature and Graph Neural Network
Nov 01, 2023



Because most of the scientific literature data is unmarked, it makes semantic representation learning based on unsupervised graph become crucial. At the same time, in order to enrich the features of scientific literature, a learning method of semantic representation of scientific literature based on adaptive features and graph neural network is proposed. By introducing the adaptive feature method, the features of scientific literature are considered globally and locally. The graph attention mechanism is used to sum the features of scientific literature with citation relationship, and give each scientific literature different feature weights, so as to better express the correlation between the features of different scientific literature. In addition, an unsupervised graph neural network semantic representation learning method is proposed. By comparing the mutual information between the positive and negative local semantic representation of scientific literature and the global graph semantic representation in the potential space, the graph neural network can capture the local and global information, thus improving the learning ability of the semantic representation of scientific literature. The experimental results show that the proposed learning method of semantic representation of scientific literature based on adaptive feature and graph neural network is competitive on the basis of scientific literature classification, and has achieved good results.
Efficient Partitioning Method of Large-Scale Public Safety Spatio-Temporal Data based on Information Loss Constraints
Jun 30, 2023



The storage, management, and application of massive spatio-temporal data are widely applied in various practical scenarios, including public safety. However, due to the unique spatio-temporal distribution characteristics of re-al-world data, most existing methods have limitations in terms of the spatio-temporal proximity of data and load balancing in distributed storage. There-fore, this paper proposes an efficient partitioning method of large-scale public safety spatio-temporal data based on information loss constraints (IFL-LSTP). The IFL-LSTP model specifically targets large-scale spatio-temporal point da-ta by combining the spatio-temporal partitioning module (STPM) with the graph partitioning module (GPM). This approach can significantly reduce the scale of data while maintaining the model's accuracy, in order to improve the partitioning efficiency. It can also ensure the load balancing of distributed storage while maintaining spatio-temporal proximity of the data partitioning results. This method provides a new solution for distributed storage of mas-sive spatio-temporal data. The experimental results on multiple real-world da-tasets demonstrate the effectiveness and superiority of IFL-LSTP.
Reinforcement Federated Learning Method Based on Adaptive OPTICS Clustering
Jun 23, 2023Federated learning is a distributed machine learning technology, which realizes the balance between data privacy protection and data sharing computing. To protect data privacy, feder-ated learning learns shared models by locally executing distributed training on participating devices and aggregating local models into global models. There is a problem in federated learning, that is, the negative impact caused by the non-independent and identical distribu-tion of data across different user terminals. In order to alleviate this problem, this paper pro-poses a strengthened federation aggregation method based on adaptive OPTICS clustering. Specifically, this method perceives the clustering environment as a Markov decision process, and models the adjustment process of parameter search direction, so as to find the best clus-tering parameters to achieve the best federated aggregation method. The core contribution of this paper is to propose an adaptive OPTICS clustering algorithm for federated learning. The algorithm combines OPTICS clustering and adaptive learning technology, and can effective-ly deal with the problem of non-independent and identically distributed data across different user terminals. By perceiving the clustering environment as a Markov decision process, the goal is to find the best parameters of the OPTICS cluster without artificial assistance, so as to obtain the best federated aggregation method and achieve better performance. The reliability and practicability of this method have been verified on the experimental data, and its effec-tiveness and superiority have been proved.
Adaptive Dual Channel Convolution Hypergraph Representation Learning for Technological Intellectual Property
Oct 12, 2022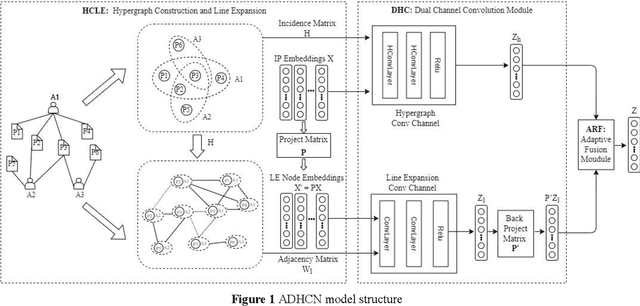
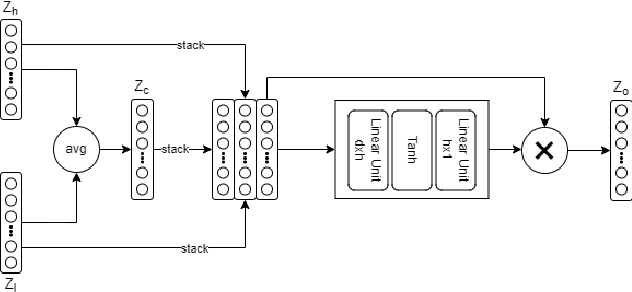
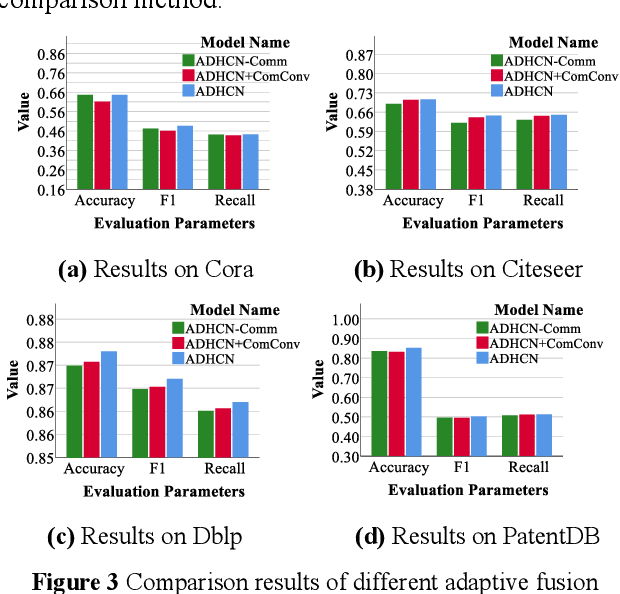
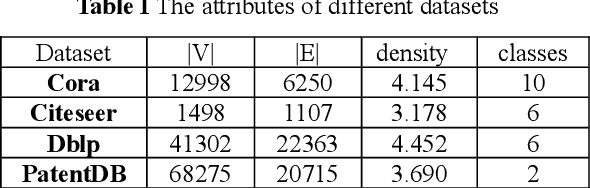
In the age of big data, the demand for hidden information mining in technological intellectual property is increasing in discrete countries. Definitely, a considerable number of graph learning algorithms for technological intellectual property have been proposed. The goal is to model the technological intellectual property entities and their relationships through the graph structure and use the neural network algorithm to extract the hidden structure information in the graph. However, most of the existing graph learning algorithms merely focus on the information mining of binary relations in technological intellectual property, ignoring the higherorder information hidden in non-binary relations. Therefore, a hypergraph neural network model based on dual channel convolution is proposed. For the hypergraph constructed from technological intellectual property data, the hypergraph channel and the line expanded graph channel of the hypergraph are used to learn the hypergraph, and the attention mechanism is introduced to adaptively fuse the output representations of the two channels. The proposed model outperforms the existing approaches on a variety of datasets.
A Relational Triple Extraction Method Based on Feature Reasoning for Technological Patents
Oct 07, 2022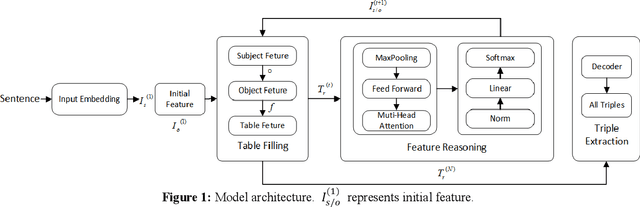


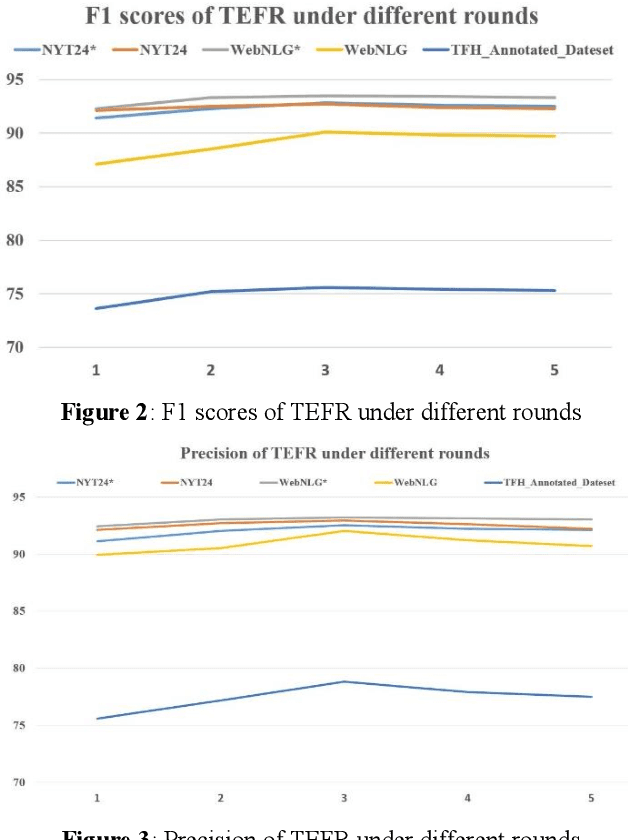
The relation triples extraction method based on table filling can address the issues of relation overlap and bias propagation. However, most of them only establish separate table features for each relationship, which ignores the implicit relationship between different entity pairs and different relationship features. Therefore, a feature reasoning relational triple extraction method based on table filling for technological patents is proposed to explore the integration of entity recognition and entity relationship, and to extract entity relationship triples from multi-source scientific and technological patents data. Compared with the previous methods, the method we proposed for relational triple extraction has the following advantages: 1) The table filling method that saves more running space enhances the speed and efficiency of the model. 2) Based on the features of existing token pairs and table relations, reasoning the implicit relationship features, and improve the accuracy of triple extraction. On five benchmark datasets, we evaluated the model we suggested. The result suggest that our model is advanced and effective, and it performed well on most of these datasets.
Unsupervised Semantic Representation Learning of Scientific Literature Based on Graph Attention Mechanism and Maximum Mutual Information
Oct 07, 2022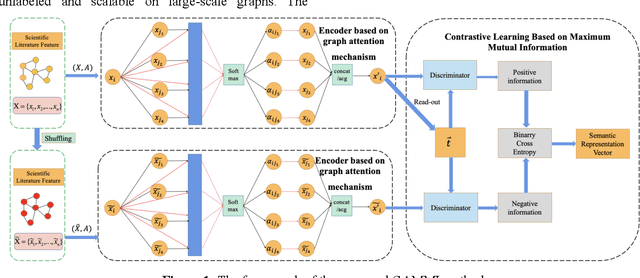


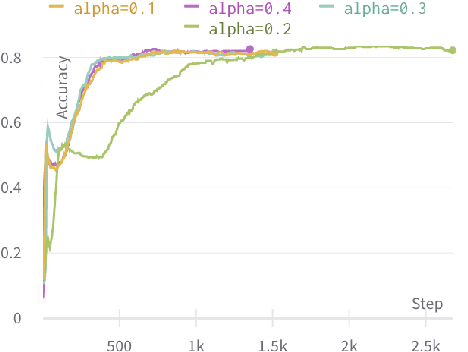
Since most scientific literature data are unlabeled, this makes unsupervised graph-based semantic representation learning crucial. Therefore, an unsupervised semantic representation learning method of scientific literature based on graph attention mechanism and maximum mutual information (GAMMI) is proposed. By introducing a graph attention mechanism, the weighted summation of nearby node features make the weights of adjacent node features entirely depend on the node features. Depending on the features of the nearby nodes, different weights can be applied to each node in the graph. Therefore, the correlations between vertex features can be better integrated into the model. In addition, an unsupervised graph contrastive learning strategy is proposed to solve the problem of being unlabeled and scalable on large-scale graphs. By comparing the mutual information between the positive and negative local node representations on the latent space and the global graph representation, the graph neural network can capture both local and global information. Experimental results demonstrate competitive performance on various node classification benchmarks, achieving good results and sometimes even surpassing the performance of supervised learning.