 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rare Topic Discovery Model for Short Texts Based on Co-occurrence word Network
Paper and Code
Jun 30, 2022

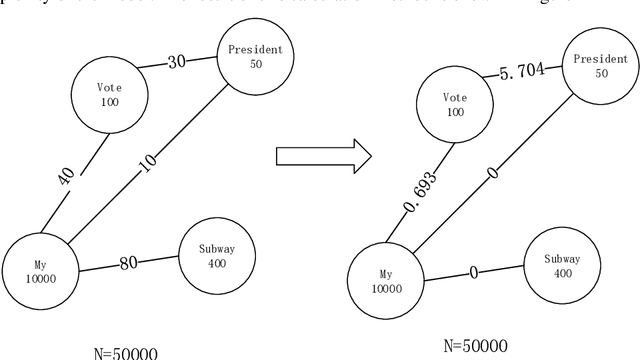

We provide a simple and general solution for the discovery of scarce topics in unbalanced short-text datasets, namely, a word co-occurrence network-based model CWIBTD, which can simultaneously address the sparsity and unbalance of short-text topics and attenuate the effect of occasional pairwise occurrences of words, allowing the model to focus more on the discovery of scarce topics. Unlike previous approaches, CWIBTD uses co-occurrence word networks to model the topic distribution of each word, which improves the semantic density of the data space and ensures its sensitivity in identify-ing rare topics by improving the way node activity is calculated and normal-izing scarce topics and large topics to some extent. In addition, using the same Gibbs sampling as LDA makes CWIBTD easy to be extended to vari-ous application scenarios. Extensive experimental validation in the unbal-anced short text dataset confirms the superiority of CWIBTD over the base-line approach in discovering rare topics. Our model can be used for early and accurate discovery of emerging topics or unexpected events on social platforms.