 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoMemBench: Benchmarking Agent Memory from a Self-Evolving Perspective
May 18, 2026Recent benchmarks for Large Language Model (LLM) agents mainly evaluate reasoning, planning, and execution. However, memory is also essential for agents, as it enables them to store, update, and retrieve information over time. This ability remains under-evaluated, largely because existing benchmarks do not provide a systematic way to assess memory mechanisms. In this paper, we study agent memory from a self-evolving perspective and introduce EvoMemBench, a unified benchmark organized along two axes: memory scope (in-episode vs. cross-episode) and memory content (knowledge-oriented vs. execution-oriented). We compare 15 representative memory methods with strong long-context baselines under a standardized protocol. Results show that current memory systems are still far from a general solution: long-context baselines remain highly competitive, memory helps most when the current context is insufficient or tasks are difficult, and no single memory form works consistently across all settings. Retrieval-based methods remain strong for knowledge-intensive settings, whereas procedural and long-term memory methods are more effective for execution-oriented tasks when their stored experience matches the task structure. We hope EvoMemBench facilitates future research on more effective memory systems for LLM-based agents. Our code is available at https://github.com/DSAIL-Memory/EvoMemBench.
Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding
May 05, 2026The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph tasks. As a widely recognized paradigm, Graph-Tokenizing LLMs (GTokenLLMs) compress complex graph data into graph tokens and treat them as prefix tokens for querying LLMs, leading many to believe that LLMs can understand graphs more effectively and efficiently. In this paper, we challenge this belief: \textit{Do GTokenLLMs fully understand graph tokens in the natural-language embedding space?} Motivated by this question, we formalize a unified framework for GTokenLLMs and propose an evaluation pipeline, \textbf{GTEval}, to assess graph-token understanding via instruction transformations at the format and content levels. We conduct extensive experiments on 6 representative GTokenLLMs with GTEval. The primary findings are as follows: (1) Existing GTokenLLMs do not fully understand graph tokens. They exhibit over-sensitivity or over-insensitivity to instruction changes, and rely heavily on text for reasoning; (2) Although graph tokens preserve task-relevant graph information and receive attention across LLM layers, their utilization varies across models and instruction variants; (3) Additional instruction tuning can improve performance on the original and seen instructions, but it does not fully address the challenge of graph-token understanding, calling for further improvement.
Toward Graph-Tokenizing Large Language Models with Reconstructive Graph Instruction Tuning
Mar 02, 2026The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph-related tasks, with the ultimate goal of developing a graph foundation model that generalizes diverse scenarios. The key challenge is to align graph data with language spaces so that LLMs can better comprehend graphs. As a popular paradigm, Graph-Tokenizing LLMs (GTokenLLMs) encode complex structures and lengthy texts into a graph token sequence, and then align them with text tokens via language instructions tuning. Despite their initial success, our information-theoretic analysis reveals that existing GTokenLLMs rely solely on text supervision from language instructions, which achieve only implicit graph-text alignment, resulting in a text-dominant bias that underutilizes graph context. To overcome this limitation, we first prove that the alignment objective is upper-bounded by the mutual information between the input graphs and their hidden representations in the LLM, which motivates us to improve this upper bound to achieve better alignment. To this end, we further propose a reconstructive graph instruction tuning pipeline, RGLM. Our key idea is to reconstruct the graph information from the LLM's graph token outputs, explicitly incorporating graph supervision to constrain the alignment process. Technically, we embody RGLM by exploring three distinct variants from two complementary perspectives: RGLM-Decoder from the input space; RGLM-Similarizer and RGLM-Denoiser from the latent space. Additionally, we theoretically analyze the alignment effectiveness of each variant. Extensive experiments on various benchmarks and task scenarios validate the effectiveness of the proposed RGLM, paving the way for new directions in GTokenLLMs' alignment research.
Data-centric Federated Graph Learning with Large Language Models
Mar 25, 2025In federated graph learning (FGL), a complete graph is divided into multiple subgraphs stored in each client due to privacy concerns, and all clients jointly train a global graph model by only transmitting model parameters. A pain point of FGL is the heterogeneity problem, where nodes or structures present non-IID properties among clients (e.g., different node label distributions), dramatically undermining the convergence and performance of FGL. To address this, existing efforts focus on design strategies at the model level, i.e., they design models to extract common knowledge to mitigate heterogeneity. However, these model-level strategies fail to fundamentally address the heterogeneity problem as the model needs to be designed from scratch when transferring to other tasks. Motivated by large language models (LLMs) having achieved remarkable success, we aim to utilize LLMs to fully understand and augment local text-attributed graphs, to address data heterogeneity at the data level. In this paper, we propose a general framework LLM4FGL that innovatively decomposes the task of LLM for FGL into two sub-tasks theoretically. Specifically, for each client, it first utilizes the LLM to generate missing neighbors and then infers connections between generated nodes and raw nodes. To improve the quality of generated nodes, we design a novel federated generation-and-reflection mechanism for LLMs, without the need to modify the parameters of the LLM but relying solely on the collective feedback from all clients. After neighbor generation, all the clients utilize a pre-trained edge predictor to infer the missing edges. Furthermore, our framework can seamlessly integrate as a plug-in with existing FGL methods. Experiments on three real-world datasets demonstrate the superiority of our method compared to advanced baselines.
Rethinking Byzantine Robustness in Federated Recommendation from Sparse Aggregation Perspective
Jan 08, 2025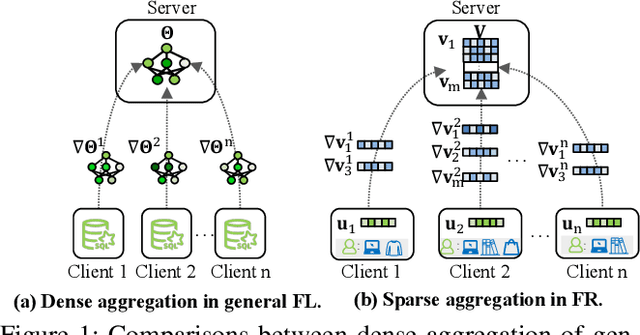

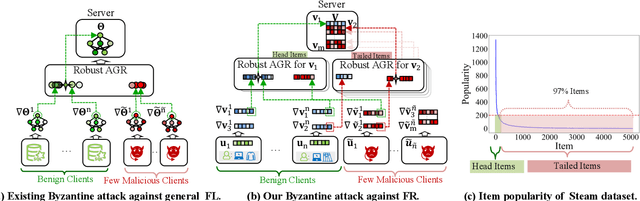
To preserve user privacy in recommender systems, federated recommendation (FR) based on federated learning (FL) emerges, keeping the personal data on the local client and updating a model collaboratively. Unlike FL, FR has a unique sparse aggregation mechanism, where the embedding of each item is updated by only partial clients, instead of full clients in a dense aggregation of general FL. Recently, as an essential principle of FL, model security has received increasing attention, especially for Byzantine attacks, where malicious clients can send arbitrary updates. The problem of exploring the Byzantine robustness of FR is particularly critical since in the domains applying FR, e.g., e-commerce, malicious clients can be injected easily by registering new accounts. However, existing Byzantine works neglect the unique sparse aggregation of FR, making them unsuitable for our problem. Thus, we make the first effort to investigate Byzantine attacks on FR from the perspective of sparse aggregation, which is non-trivial: it is not clear how to define Byzantine robustness under sparse aggregations and design Byzantine attacks under limited knowledge/capability. In this paper, we reformulate the Byzantine robustness under sparse aggregation by defining the aggregation for a single item as the smallest execution unit. Then we propose a family of effective attack strategies, named Spattack, which exploit the vulnerability in sparse aggregation and are categorized along the adversary's knowledge and capability. Extensive experimental results demonstrate that Spattack can effectively prevent convergence and even break down defenses under a few malicious clients, raising alarms for securing FR systems.
Can Large Language Models Improve the Adversarial Robustness of Graph Neural Networks?
Aug 16, 2024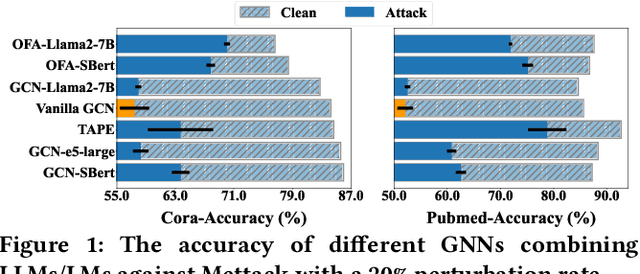
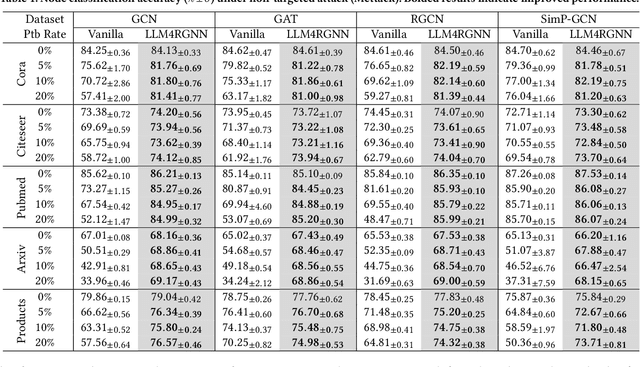
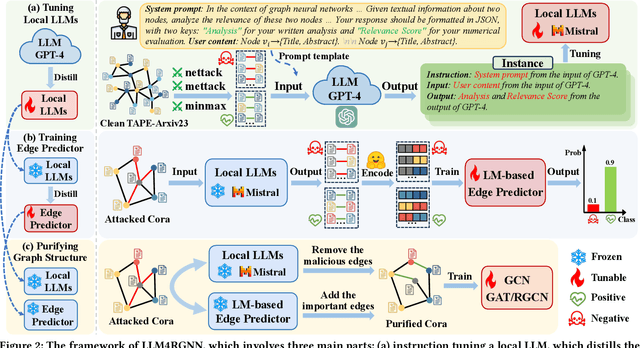
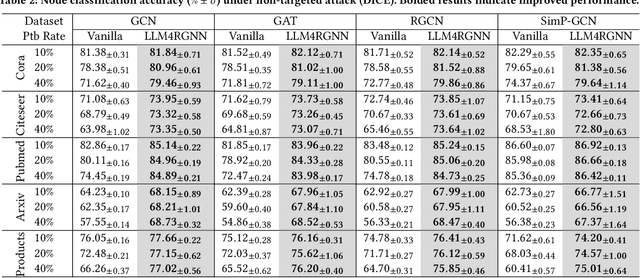
Graph neural networks (GNNs) are vulnerable to adversarial perturbations, especially for topology attacks, and many methods that improve the robustness of GNNs have received considerable attention. Recently, we have witnessed the significant success of large language models (LLMs), leading many to explore the great potential of LLMs on GNNs. However, they mainly focus on improving the performance of GNNs by utilizing LLMs to enhance the node features. Therefore, we ask: Will the robustness of GNNs also be enhanced with the powerful understanding and inference capabilities of LLMs? By presenting the empirical results, we find that despite that LLMs can improve the robustness of GNNs, there is still an average decrease of 23.1% in accuracy, implying that the GNNs remain extremely vulnerable against topology attack. Therefore, another question is how to extend the capabilities of LLMs on graph adversarial robustness. In this paper, we propose an LLM-based robust graph structure inference framework, LLM4RGNN, which distills the inference capabilities of GPT-4 into a local LLM for identifying malicious edges and an LM-based edge predictor for finding missing important edges, so as to recover a robust graph structure. Extensive experiments demonstrate that LLM4RGNN consistently improves the robustness across various GNNs. Even in some cases where the perturbation ratio increases to 40%, the accuracy of GNNs is still better than that on the clean graph.
Endowing Pre-trained Graph Models with Provable Fairness
Feb 20, 2024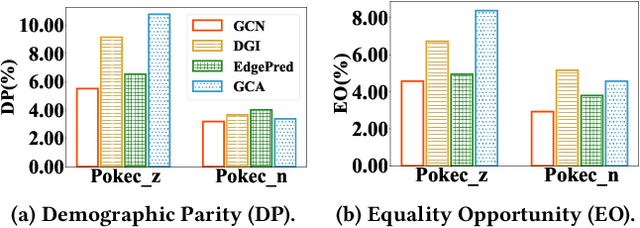
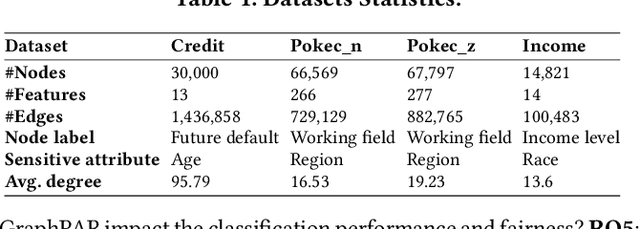
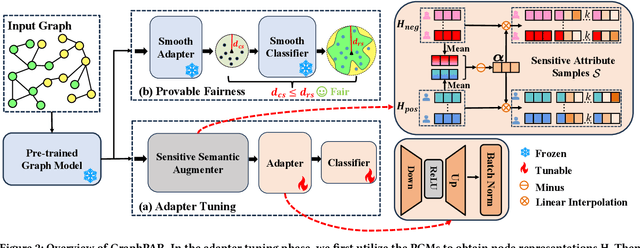
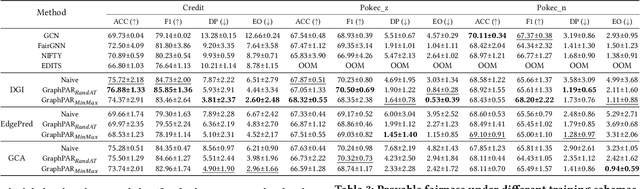
Pre-trained graph models (PGMs) aim to capture transferable inherent structural properties and apply them to different downstream tasks. Similar to pre-trained language models, PGMs also inherit biases from human society, resulting in discriminatory behavior in downstream applications. The debiasing process of existing fair methods is generally coupled with parameter optimization of GNNs. However, different downstream tasks may be associated with different sensitive attributes in reality, directly employing existing methods to improve the fairness of PGMs is inflexible and inefficient. Moreover, most of them lack a theoretical guarantee, i.e., provable lower bounds on the fairness of model predictions, which directly provides assurance in a practical scenario. To overcome these limitations, we propose a novel adapter-tuning framework that endows pre-trained graph models with provable fairness (called GraphPAR). GraphPAR freezes the parameters of PGMs and trains a parameter-efficient adapter to flexibly improve the fairness of PGMs in downstream tasks. Specifically, we design a sensitive semantic augmenter on node representations, to extend the node representations with different sensitive attribute semantics for each node. The extended representations will be used to further train an adapter, to prevent the propagation of sensitive attribute semantics from PGMs to task predictions. Furthermore, with GraphPAR, we quantify whether the fairness of each node is provable, i.e., predictions are always fair within a certain range of sensitive attribute semantics. Experimental evaluations on real-world datasets demonstrate that GraphPAR achieves state-of-the-art prediction performance and fairness on node classification task. Furthermore, based on our GraphPAR, around 90\% nodes have provable fairness.