 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding
May 05, 2026The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph tasks. As a widely recognized paradigm, Graph-Tokenizing LLMs (GTokenLLMs) compress complex graph data into graph tokens and treat them as prefix tokens for querying LLMs, leading many to believe that LLMs can understand graphs more effectively and efficiently. In this paper, we challenge this belief: \textit{Do GTokenLLMs fully understand graph tokens in the natural-language embedding space?} Motivated by this question, we formalize a unified framework for GTokenLLMs and propose an evaluation pipeline, \textbf{GTEval}, to assess graph-token understanding via instruction transformations at the format and content levels. We conduct extensive experiments on 6 representative GTokenLLMs with GTEval. The primary findings are as follows: (1) Existing GTokenLLMs do not fully understand graph tokens. They exhibit over-sensitivity or over-insensitivity to instruction changes, and rely heavily on text for reasoning; (2) Although graph tokens preserve task-relevant graph information and receive attention across LLM layers, their utilization varies across models and instruction variants; (3) Additional instruction tuning can improve performance on the original and seen instructions, but it does not fully address the challenge of graph-token understanding, calling for further improvement.
Toward Graph-Tokenizing Large Language Models with Reconstructive Graph Instruction Tuning
Mar 02, 2026The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph-related tasks, with the ultimate goal of developing a graph foundation model that generalizes diverse scenarios. The key challenge is to align graph data with language spaces so that LLMs can better comprehend graphs. As a popular paradigm, Graph-Tokenizing LLMs (GTokenLLMs) encode complex structures and lengthy texts into a graph token sequence, and then align them with text tokens via language instructions tuning. Despite their initial success, our information-theoretic analysis reveals that existing GTokenLLMs rely solely on text supervision from language instructions, which achieve only implicit graph-text alignment, resulting in a text-dominant bias that underutilizes graph context. To overcome this limitation, we first prove that the alignment objective is upper-bounded by the mutual information between the input graphs and their hidden representations in the LLM, which motivates us to improve this upper bound to achieve better alignment. To this end, we further propose a reconstructive graph instruction tuning pipeline, RGLM. Our key idea is to reconstruct the graph information from the LLM's graph token outputs, explicitly incorporating graph supervision to constrain the alignment process. Technically, we embody RGLM by exploring three distinct variants from two complementary perspectives: RGLM-Decoder from the input space; RGLM-Similarizer and RGLM-Denoiser from the latent space. Additionally, we theoretically analyze the alignment effectiveness of each variant. Extensive experiments on various benchmarks and task scenarios validate the effectiveness of the proposed RGLM, paving the way for new directions in GTokenLLMs' alignment research.
Data-centric Federated Graph Learning with Large Language Models
Mar 25, 2025In federated graph learning (FGL), a complete graph is divided into multiple subgraphs stored in each client due to privacy concerns, and all clients jointly train a global graph model by only transmitting model parameters. A pain point of FGL is the heterogeneity problem, where nodes or structures present non-IID properties among clients (e.g., different node label distributions), dramatically undermining the convergence and performance of FGL. To address this, existing efforts focus on design strategies at the model level, i.e., they design models to extract common knowledge to mitigate heterogeneity. However, these model-level strategies fail to fundamentally address the heterogeneity problem as the model needs to be designed from scratch when transferring to other tasks. Motivated by large language models (LLMs) having achieved remarkable success, we aim to utilize LLMs to fully understand and augment local text-attributed graphs, to address data heterogeneity at the data level. In this paper, we propose a general framework LLM4FGL that innovatively decomposes the task of LLM for FGL into two sub-tasks theoretically. Specifically, for each client, it first utilizes the LLM to generate missing neighbors and then infers connections between generated nodes and raw nodes. To improve the quality of generated nodes, we design a novel federated generation-and-reflection mechanism for LLMs, without the need to modify the parameters of the LLM but relying solely on the collective feedback from all clients. After neighbor generation, all the clients utilize a pre-trained edge predictor to infer the missing edges. Furthermore, our framework can seamlessly integrate as a plug-in with existing FGL methods. Experiments on three real-world datasets demonstrate the superiority of our method compared to advanced baselines.
Rethinking Byzantine Robustness in Federated Recommendation from Sparse Aggregation Perspective
Jan 08, 2025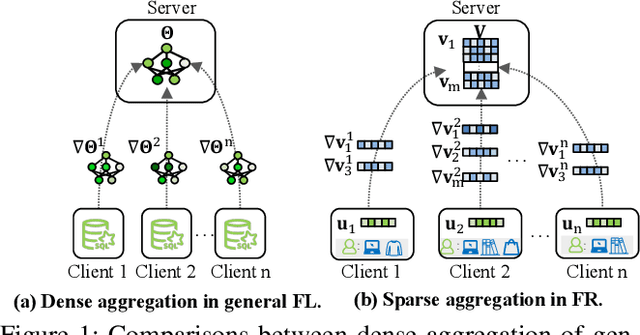

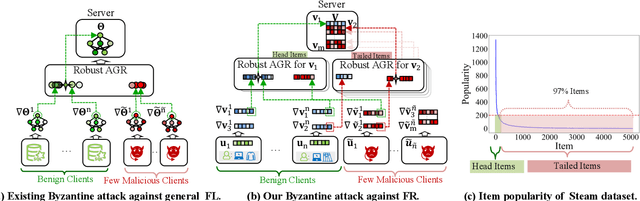
To preserve user privacy in recommender systems, federated recommendation (FR) based on federated learning (FL) emerges, keeping the personal data on the local client and updating a model collaboratively. Unlike FL, FR has a unique sparse aggregation mechanism, where the embedding of each item is updated by only partial clients, instead of full clients in a dense aggregation of general FL. Recently, as an essential principle of FL, model security has received increasing attention, especially for Byzantine attacks, where malicious clients can send arbitrary updates. The problem of exploring the Byzantine robustness of FR is particularly critical since in the domains applying FR, e.g., e-commerce, malicious clients can be injected easily by registering new accounts. However, existing Byzantine works neglect the unique sparse aggregation of FR, making them unsuitable for our problem. Thus, we make the first effort to investigate Byzantine attacks on FR from the perspective of sparse aggregation, which is non-trivial: it is not clear how to define Byzantine robustness under sparse aggregations and design Byzantine attacks under limited knowledge/capability. In this paper, we reformulate the Byzantine robustness under sparse aggregation by defining the aggregation for a single item as the smallest execution unit. Then we propose a family of effective attack strategies, named Spattack, which exploit the vulnerability in sparse aggregation and are categorized along the adversary's knowledge and capability. Extensive experimental results demonstrate that Spattack can effectively prevent convergence and even break down defenses under a few malicious clients, raising alarms for securing FR systems.
FineMolTex: Towards Fine-grained Molecular Graph-Text Pre-training
Sep 21, 2024
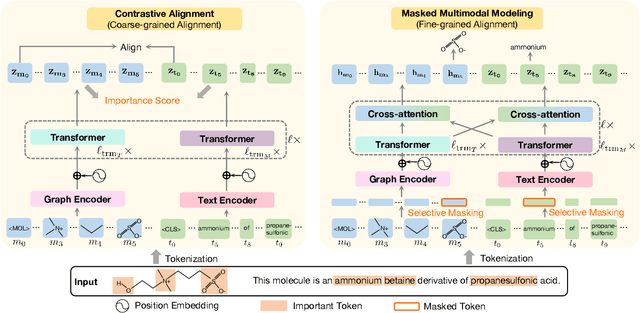

Understanding molecular structure and related knowledge is crucial for scientific research. Recent studies integrate molecular graphs with their textual descriptions to enhance molecular representation learning. However, they focus on the whole molecular graph and neglect frequently occurring subgraphs, known as motifs,which are essential for determining molecular properties. Without such fine-grained knowledge, these models struggle to generalize to unseen molecules and tasks that require motif-level insights. To bridge this gap, we propose FineMolTex, a novel Fine-grained Molecular graph-Text pre-training framework to jointly learn coarse-grained molecule-level knowledge and fine-grained motif-level knowledge. Specifically, FineMolTex consists of two pre-training tasks: a contrastive alignment task for coarse-grained matching and a masked multi-modal modeling task for fine-grained matching. In particular, the latter predicts the labels of masked motifs and words, leveraging insights from each other, thereby enabling FineMolTex to understand the fine-grained matching between motifs and words. Finally, we conduct extensive experiments across three downstream tasks, achieving up to 230% improvement in the text-based molecule editing task. Additionally, our case studies reveal that FineMolTex successfully captures fine-grained knowledge, potentially offering valuable insights for drug discovery and catalyst design.
Can Large Language Models Improve the Adversarial Robustness of Graph Neural Networks?
Aug 16, 2024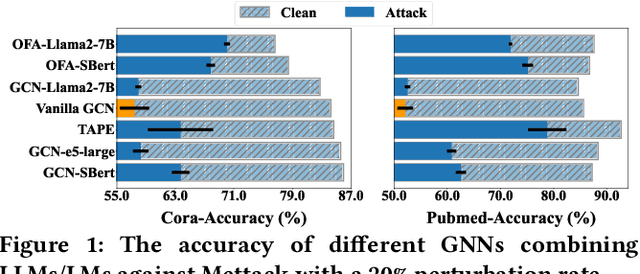
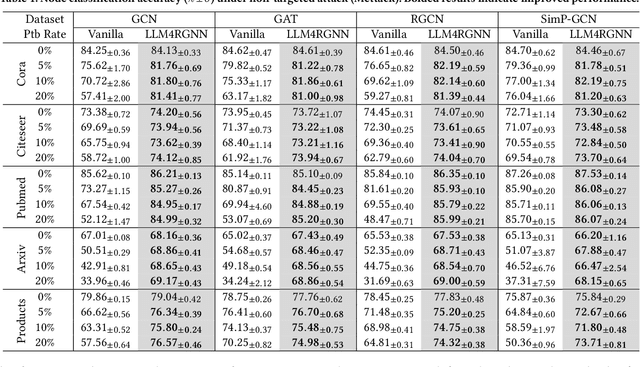
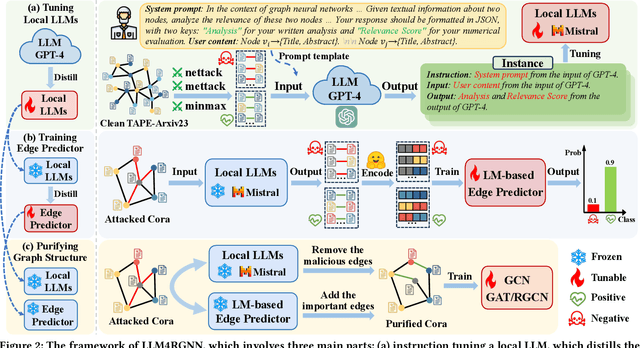
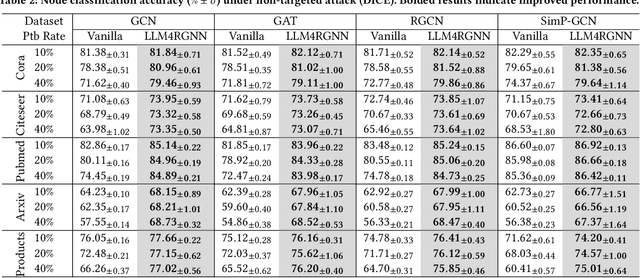
Graph neural networks (GNNs) are vulnerable to adversarial perturbations, especially for topology attacks, and many methods that improve the robustness of GNNs have received considerable attention. Recently, we have witnessed the significant success of large language models (LLMs), leading many to explore the great potential of LLMs on GNNs. However, they mainly focus on improving the performance of GNNs by utilizing LLMs to enhance the node features. Therefore, we ask: Will the robustness of GNNs also be enhanced with the powerful understanding and inference capabilities of LLMs? By presenting the empirical results, we find that despite that LLMs can improve the robustness of GNNs, there is still an average decrease of 23.1% in accuracy, implying that the GNNs remain extremely vulnerable against topology attack. Therefore, another question is how to extend the capabilities of LLMs on graph adversarial robustness. In this paper, we propose an LLM-based robust graph structure inference framework, LLM4RGNN, which distills the inference capabilities of GPT-4 into a local LLM for identifying malicious edges and an LM-based edge predictor for finding missing important edges, so as to recover a robust graph structure. Extensive experiments demonstrate that LLM4RGNN consistently improves the robustness across various GNNs. Even in some cases where the perturbation ratio increases to 40%, the accuracy of GNNs is still better than that on the clean graph.
Minimum Topology Attacks for Graph Neural Networks
Mar 05, 2024



With the great popularity of Graph Neural Networks (GNNs), their robustness to adversarial topology attacks has received significant attention. Although many attack methods have been proposed, they mainly focus on fixed-budget attacks, aiming at finding the most adversarial perturbations within a fixed budget for target node. However, considering the varied robustness of each node, there is an inevitable dilemma caused by the fixed budget, i.e., no successful perturbation is found when the budget is relatively small, while if it is too large, the yielding redundant perturbations will hurt the invisibility. To break this dilemma, we propose a new type of topology attack, named minimum-budget topology attack, aiming to adaptively find the minimum perturbation sufficient for a successful attack on each node. To this end, we propose an attack model, named MiBTack, based on a dynamic projected gradient descent algorithm, which can effectively solve the involving non-convex constraint optimization on discrete topology. Extensive results on three GNNs and four real-world datasets show that MiBTack can successfully lead all target nodes misclassified with the minimum perturbation edges. Moreover, the obtained minimum budget can be used to measure node robustness, so we can explore the relationships of robustness, topology, and uncertainty for nodes, which is beyond what the current fixed-budget topology attacks can offer.
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024



Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
Endowing Pre-trained Graph Models with Provable Fairness
Feb 20, 2024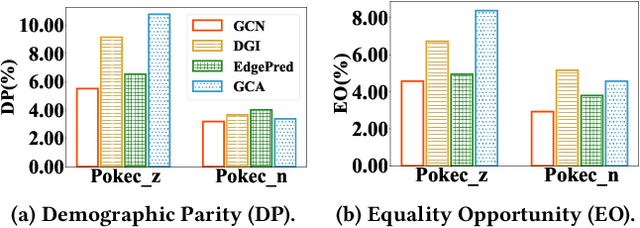
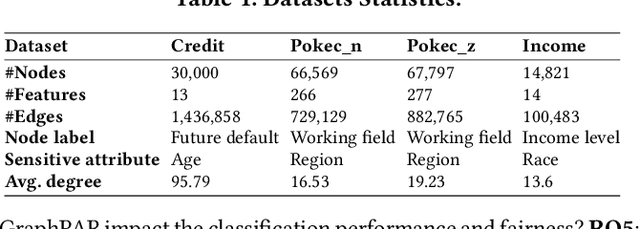
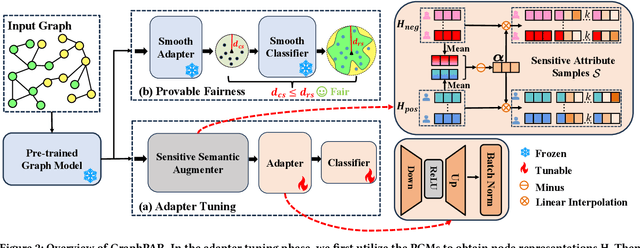
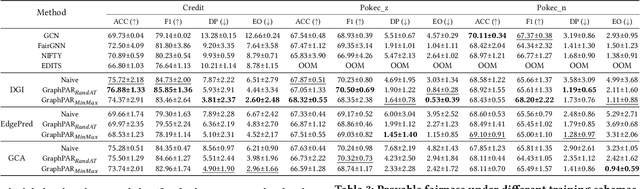
Pre-trained graph models (PGMs) aim to capture transferable inherent structural properties and apply them to different downstream tasks. Similar to pre-trained language models, PGMs also inherit biases from human society, resulting in discriminatory behavior in downstream applications. The debiasing process of existing fair methods is generally coupled with parameter optimization of GNNs. However, different downstream tasks may be associated with different sensitive attributes in reality, directly employing existing methods to improve the fairness of PGMs is inflexible and inefficient. Moreover, most of them lack a theoretical guarantee, i.e., provable lower bounds on the fairness of model predictions, which directly provides assurance in a practical scenario. To overcome these limitations, we propose a novel adapter-tuning framework that endows pre-trained graph models with provable fairness (called GraphPAR). GraphPAR freezes the parameters of PGMs and trains a parameter-efficient adapter to flexibly improve the fairness of PGMs in downstream tasks. Specifically, we design a sensitive semantic augmenter on node representations, to extend the node representations with different sensitive attribute semantics for each node. The extended representations will be used to further train an adapter, to prevent the propagation of sensitive attribute semantics from PGMs to task predictions. Furthermore, with GraphPAR, we quantify whether the fairness of each node is provable, i.e., predictions are always fair within a certain range of sensitive attribute semantics. Experimental evaluations on real-world datasets demonstrate that GraphPAR achieves state-of-the-art prediction performance and fairness on node classification task. Furthermore, based on our GraphPAR, around 90\% nodes have provable fairness.
Towards Graph Foundation Models: A Survey and Beyond
Oct 18, 2023Emerging as fundamental building blocks for diverse artificial intelligence applications, foundation models have achieved notable success across natural language processing and many other domains. Parallelly, graph machine learning has witnessed a transformative shift, with shallow methods giving way to deep learning approaches. The emergence and homogenization capabilities of foundation models have piqued the interest of graph machine learning researchers, sparking discussions about developing the next graph learning paradigm that is pre-trained on broad graph data and can be adapted to a wide range of downstream graph tasks. However, there is currently no clear definition and systematic analysis for this type of work. In this article, we propose the concept of graph foundation models (GFMs), and provide the first comprehensive elucidation on their key characteristics and technologies. Following that, we categorize existing works towards GFMs into three categories based on their reliance on graph neural networks and large language models. Beyond providing a comprehensive overview of the current landscape of graph foundation models, this article also discusses potential research directions for this evolving field.