 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
Jan 31, 2026Recent large language models (LLMs) achieve near-saturation accuracy on many established mathematical reasoning benchmarks, raising concerns about their ability to diagnose genuine reasoning competence. This saturation largely stems from the dominance of template-based computation and shallow arithmetic decomposition in existing datasets, which underrepresent reasoning skills such as multi-constraint coordination, constructive logical synthesis, and spatial inference. To address this gap, we introduce ReasoningMath-Plus, a benchmark of 150 carefully curated problems explicitly designed to evaluate structural reasoning. Each problem emphasizes reasoning under interacting constraints, constructive solution formation, or non-trivial structural insight, and is annotated with a minimal reasoning skeleton to support fine-grained process-level evaluation. Alongside the dataset, we introduce HCRS (Hazard-aware Chain-based Rule Score), a deterministic step-level scoring function, and train a Process Reward Model (PRM) on the annotated reasoning traces. Empirically, while leading models attain relatively high final-answer accuracy (up to 5.8/10), HCRS-based holistic evaluation yields substantially lower scores (average 4.36/10, best 5.14/10), showing that answer-only metrics can overestimate reasoning robustness.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Learning Social Graph for Inactive User Recommendation
May 08, 2024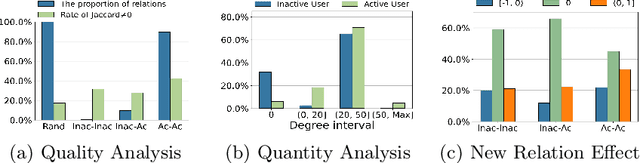

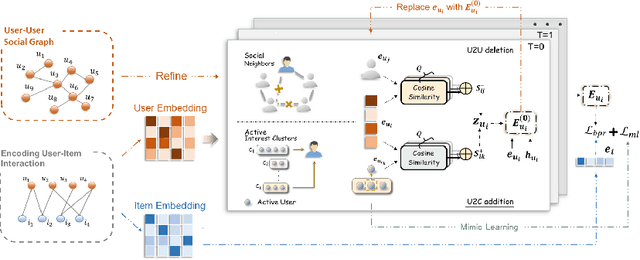
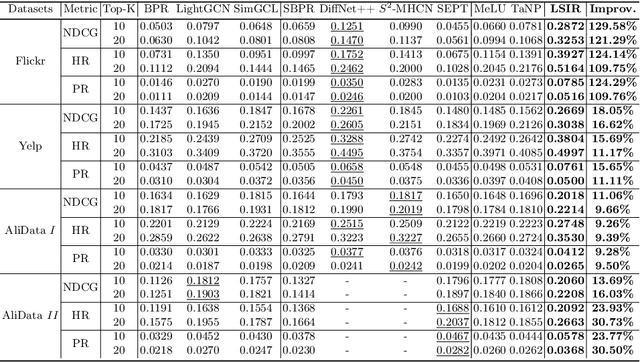
Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024



Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
Graph Contrastive Invariant Learning from the Causal Perspective
Jan 23, 2024



Graph contrastive learning (GCL), learning the node representation by contrasting two augmented graphs in a self-supervised way, has attracted considerable attention. GCL is usually believed to learn the invariant representation. However, does this understanding always hold in practice? In this paper, we first study GCL from the perspective of causality. By analyzing GCL with the structural causal model (SCM), we discover that traditional GCL may not well learn the invariant representations due to the non-causal information contained in the graph. How can we fix it and encourage the current GCL to learn better invariant representations? The SCM offers two requirements and motives us to propose a novel GCL method. Particularly, we introduce the spectral graph augmentation to simulate the intervention upon non-causal factors. Then we design the invariance objective and independence objective to better capture the causal factors. Specifically, (i) the invariance objective encourages the encoder to capture the invariant information contained in causal variables, and (ii) the independence objective aims to reduce the influence of confounders on the causal variables. Experimental results demonstrate the effectiveness of our approach on node classification tasks.
Debiasing Graph Neural Networks via Learning Disentangled Causal Substructure
Sep 28, 2022
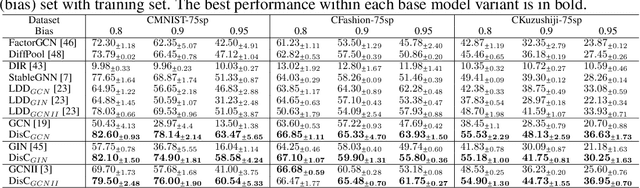
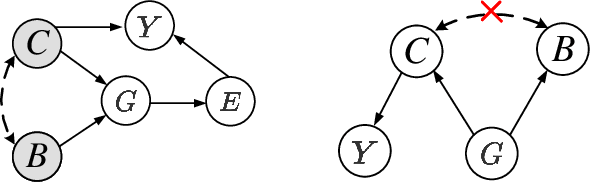
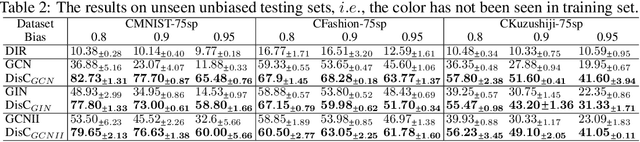
Most Graph Neural Networks (GNNs) predict the labels of unseen graphs by learning the correlation between the input graphs and labels. However, by presenting a graph classification investigation on the training graphs with severe bias, surprisingly, we discover that GNNs always tend to explore the spurious correlations to make decision, even if the causal correlation always exists. This implies that existing GNNs trained on such biased datasets will suffer from poor generalization capability. By analyzing this problem in a causal view, we find that disentangling and decorrelating the causal and bias latent variables from the biased graphs are both crucial for debiasing. Inspiring by this, we propose a general disentangled GNN framework to learn the causal substructure and bias substructure, respectively. Particularly, we design a parameterized edge mask generator to explicitly split the input graph into causal and bias subgraphs. Then two GNN modules supervised by causal/bias-aware loss functions respectively are trained to encode causal and bias subgraphs into their corresponding representations. With the disentangled representations, we synthesize the counterfactual unbiased training samples to further decorrelate causal and bias variables. Moreover, to better benchmark the severe bias problem, we construct three new graph datasets, which have controllable bias degrees and are easier to visualize and explain. Experimental results well demonstrate that our approach achieves superior generalization performance over existing baselines. Furthermore, owing to the learned edge mask, the proposed model has appealing interpretability and transferability. Code and data are available at: https://github.com/googlebaba/DisC.