 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing 3D Geometry Reconstruction from Implicit Neural Representations
Oct 16, 2024



Implicit neural representations have emerged as a powerful tool in learning 3D geometry, offering unparalleled advantages over conventional representations like mesh-based methods. A common type of INR implicitly encodes a shape's boundary as the zero-level set of the learned continuous function and learns a mapping from a low-dimensional latent space to the space of all possible shapes represented by its signed distance function. However, most INRs struggle to retain high-frequency details, which are crucial for accurate geometric depiction, and they are computationally expensive. To address these limitations, we present a novel approach that both reduces computational expenses and enhances the capture of fine details. Our method integrates periodic activation functions, positional encodings, and normals into the neural network architecture. This integration significantly enhances the model's ability to learn the entire space of 3D shapes while preserving intricate details and sharp features, areas where conventional representations often fall short.
Learning Social Graph for Inactive User Recommendation
May 08, 2024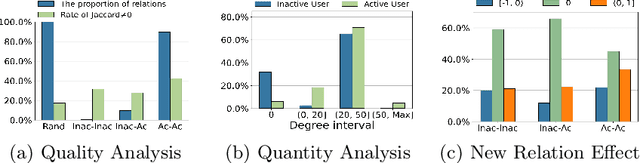

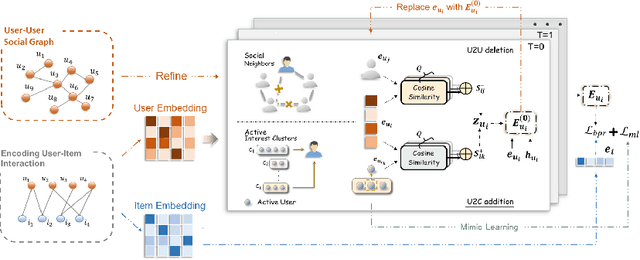
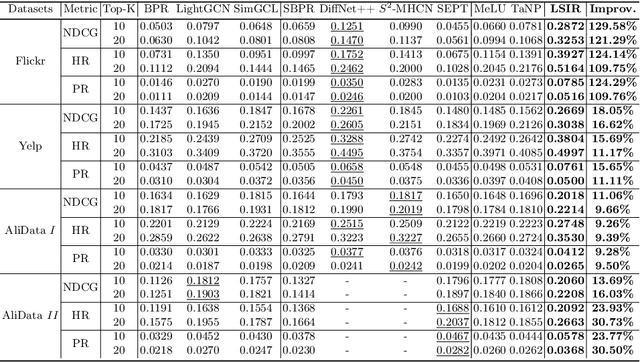
Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024



Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
Estimating Coronal Mass Ejection Mass and Kinetic Energy by Fusion of Multiple Deep-learning Models
Dec 04, 2023Coronal mass ejections (CMEs) are massive solar eruptions, which have a significant impact on Earth. In this paper, we propose a new method, called DeepCME, to estimate two properties of CMEs, namely, CME mass and kinetic energy. Being able to estimate these properties helps better understand CME dynamics. Our study is based on the CME catalog maintained at the Coordinated Data Analysis Workshops (CDAW) Data Center, which contains all CMEs manually identified since 1996 using the Large Angle and Spectrometric Coronagraph (LASCO) on board the Solar and Heliospheric Observatory (SOHO). We use LASCO C2 data in the period between January 1996 and December 2020 to train, validate and test DeepCME through 10-fold cross validation. The DeepCME method is a fusion of three deep learning models, including ResNet, InceptionNet, and InceptionResNet. Our fusion model extracts features from LASCO C2 images, effectively combining the learning capabilities of the three component models to jointly estimate the mass and kinetic energy of CMEs. Experimental results show that the fusion model yields a mean relative error (MRE) of 0.013 (0.009, respectively) compared to the MRE of 0.019 (0.017, respectively) of the best component model InceptionResNet (InceptionNet, respectively) in estimating the CME mass (kinetic energy, respectively). To our knowledge, this is the first time that deep learning has been used for CME mass and kinetic energy estimations.
* 10 pages, 7 figures
Experience Augmentation: Boosting and Accelerating Off-Policy Multi-Agent Reinforcement Learning
May 20, 2020



Exploration of the high-dimensional state action space is one of the biggest challenges in Reinforcement Learning (RL), especially in multi-agent domain. We present a novel technique called Experience Augmentation, which enables a time-efficient and boosted learning based on a fast, fair and thorough exploration to the environment. It can be combined with arbitrary off-policy MARL algorithms and is applicable to either homogeneous or heterogeneous environments. We demonstrate our approach by combining it with MADDPG and verifing the performance in two homogeneous and one heterogeneous environments. In the best performing scenario, the MADDPG with experience augmentation reaches to the convergence reward of vanilla MADDPG with 1/4 realistic time, and its convergence beats the original model by a significant margin. Our ablation studies show that experience augmentation is a crucial ingredient which accelerates the training process and boosts the convergence.