 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve-Refine-Calibrate: A Framework for Complex Claim Fact-Checking
Jan 23, 2026Fact-checking aims to verify the truthfulness of a claim based on the retrieved evidence. Existing methods typically follow a decomposition paradigm, in which a claim is broken down into sub-claims that are individually verified. However, the decomposition paradigm may introduce noise to the verification process due to irrelevant entities or evidence, ultimately degrading verification accuracy. To address this problem, we propose a Retrieve-Refine-Calibrate (RRC) framework based on large language models (LLMs). Specifically, the framework first identifies the entities mentioned in the claim and retrieves evidence relevant to them. Then, it refines the retrieved evidence based on the claim to reduce irrelevant information. Finally, it calibrates the verification process by re-evaluating low-confidence predictions. Experiments on two popular fact-checking datasets (HOVER and FEVEROUS-S) demonstrate that our framework achieves superior performance compared with competitive baselines.
LADB: Latent Aligned Diffusion Bridges for Semi-Supervised Domain Translation
Sep 10, 2025Diffusion models excel at generating high-quality outputs but face challenges in data-scarce domains, where exhaustive retraining or costly paired data are often required. To address these limitations, we propose Latent Aligned Diffusion Bridges (LADB), a semi-supervised framework for sample-to-sample translation that effectively bridges domain gaps using partially paired data. By aligning source and target distributions within a shared latent space, LADB seamlessly integrates pretrained source-domain diffusion models with a target-domain Latent Aligned Diffusion Model (LADM), trained on partially paired latent representations. This approach enables deterministic domain mapping without the need for full supervision. Compared to unpaired methods, which often lack controllability, and fully paired approaches that require large, domain-specific datasets, LADB strikes a balance between fidelity and diversity by leveraging a mixture of paired and unpaired latent-target couplings. Our experimental results demonstrate superior performance in depth-to-image translation under partial supervision. Furthermore, we extend LADB to handle multi-source translation (from depth maps and segmentation masks) and multi-target translation in a class-conditioned style transfer task, showcasing its versatility in handling diverse and heterogeneous use cases. Ultimately, we present LADB as a scalable and versatile solution for real-world domain translation, particularly in scenarios where data annotation is costly or incomplete.
Learning Social Graph for Inactive User Recommendation
May 08, 2024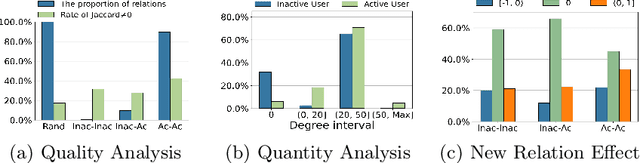

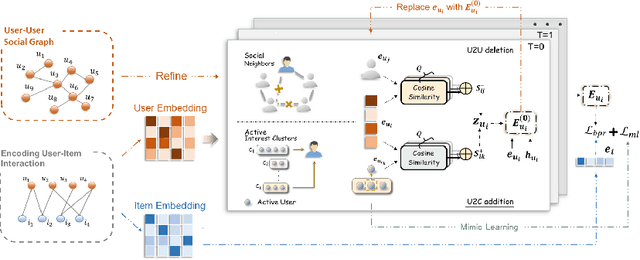
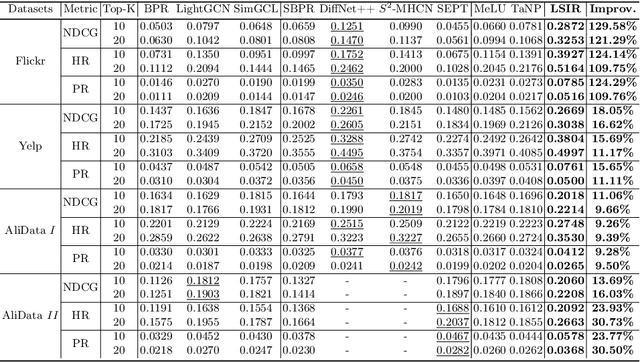
Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024



Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
FViT: A Focal Vision Transformer with Gabor Filter
Feb 27, 2024Vision transformers have achieved encouraging progress in various computer vision tasks. A common belief is that this is attributed to the competence of self-attention in modeling the global dependencies among feature tokens. Unfortunately, self-attention still faces some challenges in dense prediction tasks, such as the high computational complexity and absence of desirable inductive bias. To address these issues, we revisit the potential benefits of integrating vision transformer with Gabor filter, and propose a Learnable Gabor Filter (LGF) by using convolution. As an alternative to self-attention, we employ LGF to simulate the response of simple cells in the biological visual system to input images, prompting models to focus on discriminative feature representations of targets from various scales and orientations. Additionally, we design a Bionic Focal Vision (BFV) block based on the LGF. This block draws inspiration from neuroscience and introduces a Multi-Path Feed Forward Network (MPFFN) to emulate the working way of biological visual cortex processing information in parallel. Furthermore, we develop a unified and efficient pyramid backbone network family called Focal Vision Transformers (FViTs) by stacking BFV blocks. Experimental results show that FViTs exhibit highly competitive performance in various vision tasks. Especially in terms of computational efficiency and scalability, FViTs show significant advantages compared with other counterparts. Code is available at https://github.com/nkusyl/FViT
EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
Oct 22, 2023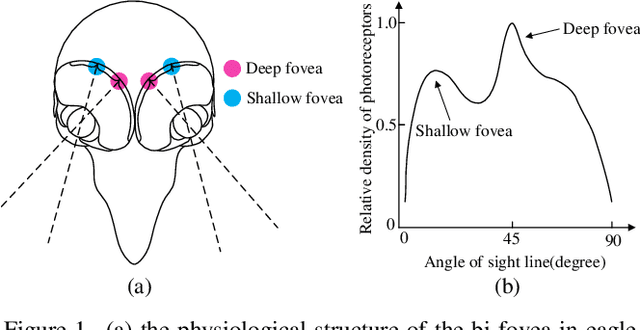
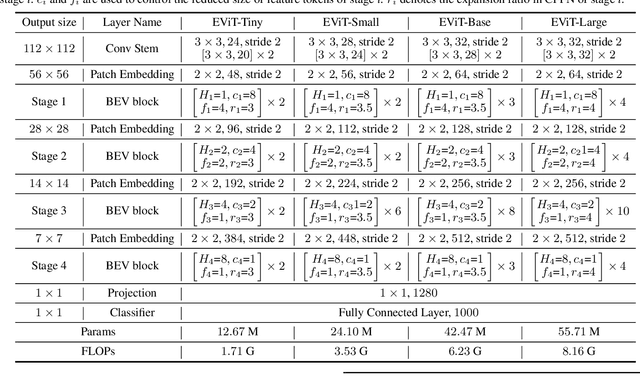
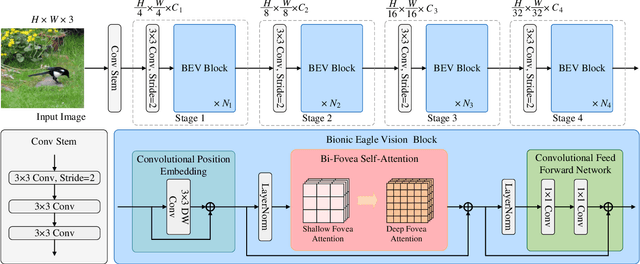
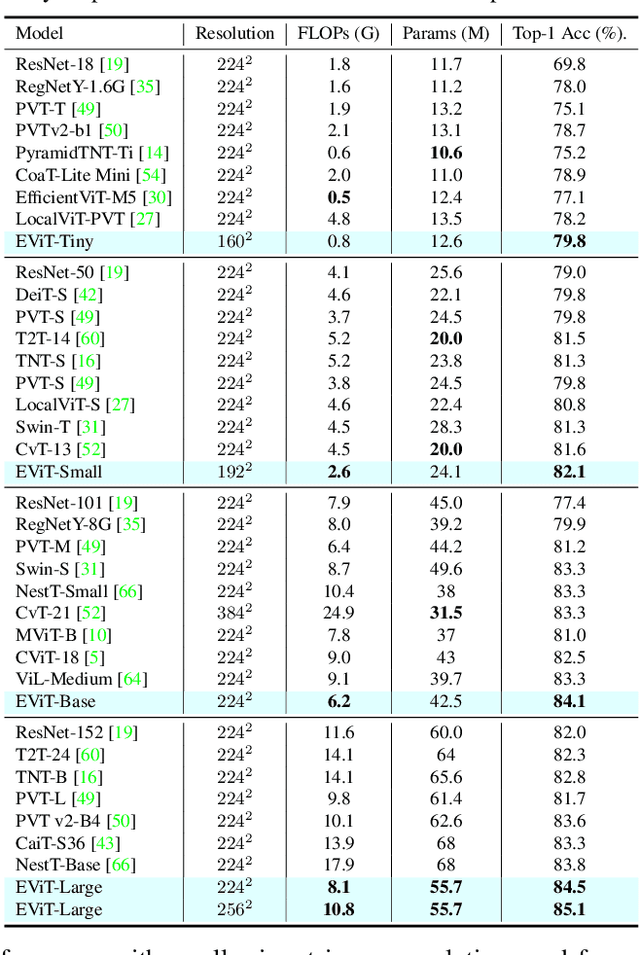
Thanks to the advancement of deep learning technology, vision transformer has demonstrated competitive performance in various computer vision tasks. Unfortunately, vision transformer still faces some challenges such as high computational complexity and absence of desirable inductive bias. To alleviate these problems, a novel Bi-Fovea Self-Attention (BFSA) is proposed, inspired by the physiological structure and characteristics of bi-fovea vision in eagle eyes. This BFSA can simulate the shallow fovea and deep fovea functions of eagle vision, enable the network to extract feature representations of targets from coarse to fine, facilitate the interaction of multi-scale feature representations. Additionally, a Bionic Eagle Vision (BEV) block based on BFSA is designed in this study. It combines the advantages of CNNs and Vision Transformers to enhance the ability of global and local feature representations of networks. Furthermore, a unified and efficient general pyramid backbone network family is developed by stacking the BEV blocks in this study, called Eagle Vision Transformers (EViTs). Experimental results on various computer vision tasks including image classification, object detection, instance segmentation and other transfer learning tasks show that the proposed EViTs perform effectively by comparing with the baselines under same model size and exhibit higher speed on graphics processing unit than other models. Code is available at https://github.com/nkusyl/EViT.
Box2Poly: Memory-Efficient Polygon Prediction of Arbitrarily Shaped and Rotated Text
Sep 20, 2023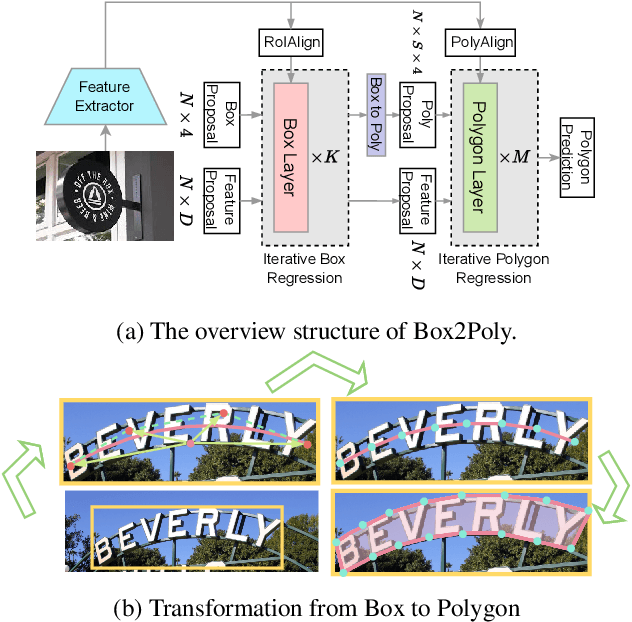

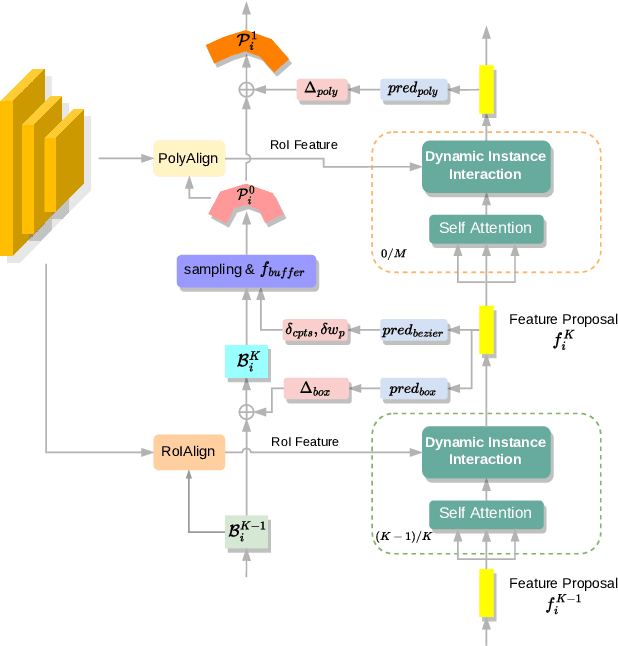

Recently, Transformer-based text detection techniques have sought to predict polygons by encoding the coordinates of individual boundary vertices using distinct query features. However, this approach incurs a significant memory overhead and struggles to effectively capture the intricate relationships between vertices belonging to the same instance. Consequently, irregular text layouts often lead to the prediction of outlined vertices, diminishing the quality of results. To address these challenges, we present an innovative approach rooted in Sparse R-CNN: a cascade decoding pipeline for polygon prediction. Our method ensures precision by iteratively refining polygon predictions, considering both the scale and location of preceding results. Leveraging this stabilized regression pipeline, even employing just a single feature vector to guide polygon instance regression yields promising detection results. Simultaneously, the leverage of instance-level feature proposal substantially enhances memory efficiency (>50% less vs. the state-of-the-art method DPText-DETR) and reduces inference speed (>40% less vs. DPText-DETR) with minor performance drop on benchmarks.
Primitive Graph Learning for Unified Vector Mapping
Jun 28, 2022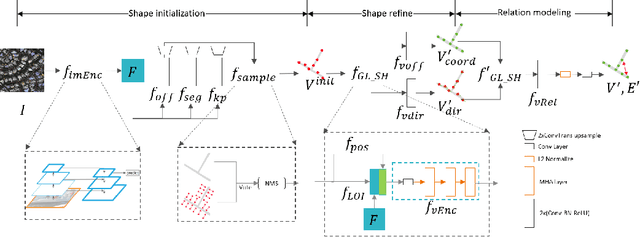


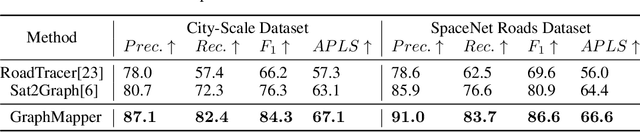
Large-scale vector mapping is important for transportation, city planning, and survey and census. We propose GraphMapper, a unified framework for end-to-end vector map extraction from satellite images. Our key idea is a novel unified representation of shapes of different topologies named "primitive graph", which is a set of shape primitives and their pairwise relationship matrix. Then, we convert vector shape prediction, regularization, and topology reconstruction into a unique primitive graph learning problem. Specifically, GraphMapper is a generic primitive graph learning network based on global shape context modelling through multi-head-attention. An embedding space sorting method is developed for accurate primitive relationship modelling. We empirically demonstrate the effectiveness of GraphMapper on two challenging mapping tasks, building footprint regularization and road network topology reconstruction. Our model outperforms state-of-the-art methods by 8-10% in both tasks on public benchmarks. All code will be publicly available.
MVLayoutNet:3D layout reconstruction with multi-view panoramas
Dec 12, 2021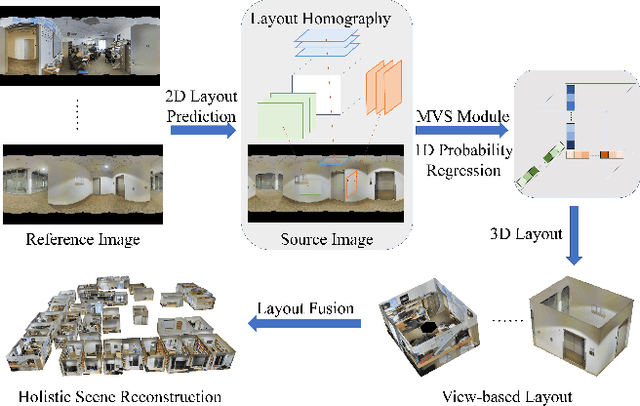
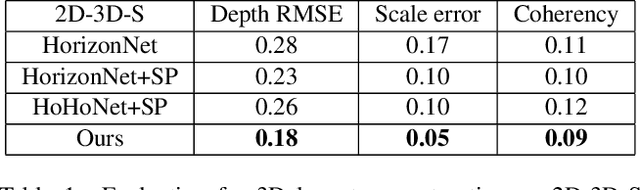
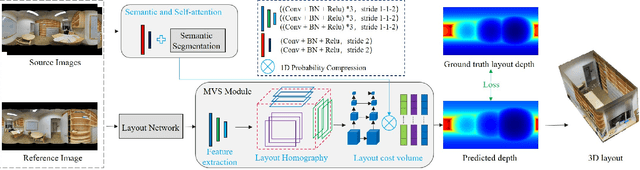

We present MVLayoutNet, an end-to-end network for holistic 3D reconstruction from multi-view panoramas. Our core contribution is to seamlessly combine learned monocular layout estimation and multi-view stereo (MVS) for accurate layout reconstruction in both 3D and image space. We jointly train a layout module to produce an initial layout and a novel MVS module to obtain accurate layout geometry. Unlike standard MVSNet [33], our MVS module takes a newly-proposed layout cost volume, which aggregates multi-view costs at the same depth layer into corresponding layout elements. We additionally provide an attention-based scheme that guides the MVS module to focus on structural regions. Such a design considers both local pixel-level costs and global holistic information for better reconstruction. Experiments show that our method outperforms state-of-the-arts in terms of depth rmse by 21.7% and 20.6% on the 2D-3D-S [1] and ZInD [5] datasets. Finally, our method leads to coherent layout geometry that enables the reconstruction of an entire scene.