 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Primitive Transformer for Long-Term 4D Point Cloud Video Understanding
Jul 30, 2022

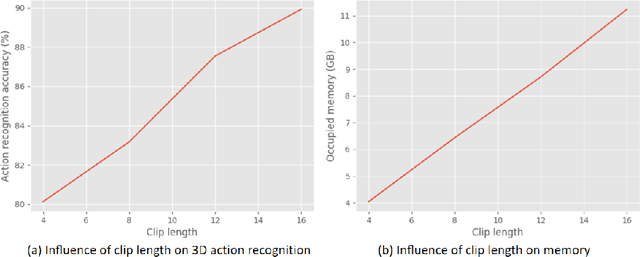

This paper proposes a 4D backbone for long-term point cloud video understanding. A typical way to capture spatial-temporal context is using 4Dconv or transformer without hierarchy. However, those methods are neither effective nor efficient enough due to camera motion, scene changes, sampling patterns, and the complexity of 4D data. To address those issues, we leverage the primitive plane as a mid-level representation to capture the long-term spatial-temporal context in 4D point cloud videos and propose a novel hierarchical backbone named Point Primitive Transformer(PPTr), which is mainly composed of intra-primitive point transformers and primitive transformers. Extensive experiments show that PPTr outperforms the previous state of the arts on different tasks
MVLayoutNet:3D layout reconstruction with multi-view panoramas
Dec 12, 2021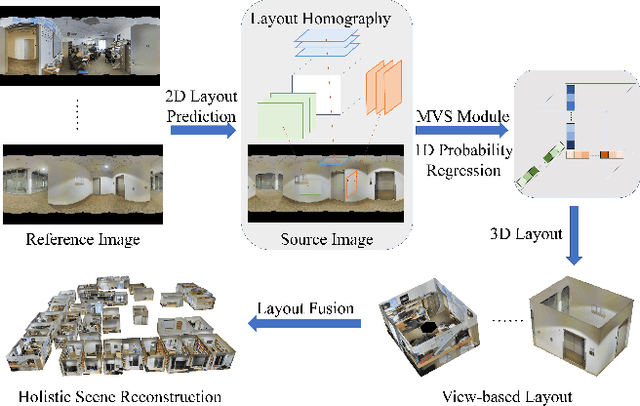
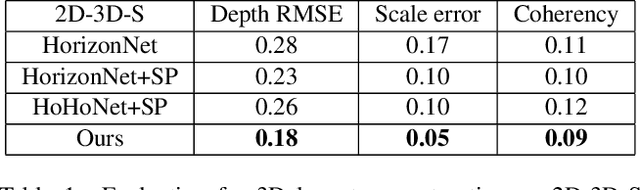
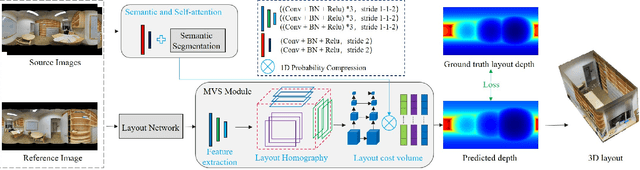

We present MVLayoutNet, an end-to-end network for holistic 3D reconstruction from multi-view panoramas. Our core contribution is to seamlessly combine learned monocular layout estimation and multi-view stereo (MVS) for accurate layout reconstruction in both 3D and image space. We jointly train a layout module to produce an initial layout and a novel MVS module to obtain accurate layout geometry. Unlike standard MVSNet [33], our MVS module takes a newly-proposed layout cost volume, which aggregates multi-view costs at the same depth layer into corresponding layout elements. We additionally provide an attention-based scheme that guides the MVS module to focus on structural regions. Such a design considers both local pixel-level costs and global holistic information for better reconstruction. Experiments show that our method outperforms state-of-the-arts in terms of depth rmse by 21.7% and 20.6% on the 2D-3D-S [1] and ZInD [5] datasets. Finally, our method leads to coherent layout geometry that enables the reconstruction of an entire scene.