 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images
Mar 07, 2024This paper introduces CN-RMA, a novel approach for 3D indoor object detection from multi-view images. We observe the key challenge as the ambiguity of image and 3D correspondence without explicit geometry to provide occlusion information. To address this issue, CN-RMA leverages the synergy of 3D reconstruction networks and 3D object detection networks, where the reconstruction network provides a rough Truncated Signed Distance Function (TSDF) and guides image features to vote to 3D space correctly in an end-to-end manner. Specifically, we associate weights to sampled points of each ray through ray marching, representing the contribution of a pixel in an image to corresponding 3D locations. Such weights are determined by the predicted signed distances so that image features vote only to regions near the reconstructed surface. Our method achieves state-of-the-art performance in 3D object detection from multi-view images, as measured by mAP@0.25 and mAP@0.5 on the ScanNet and ARKitScenes datasets. The code and models are released at https://github.com/SerCharles/CN-RMA.
MVLayoutNet:3D layout reconstruction with multi-view panoramas
Dec 12, 2021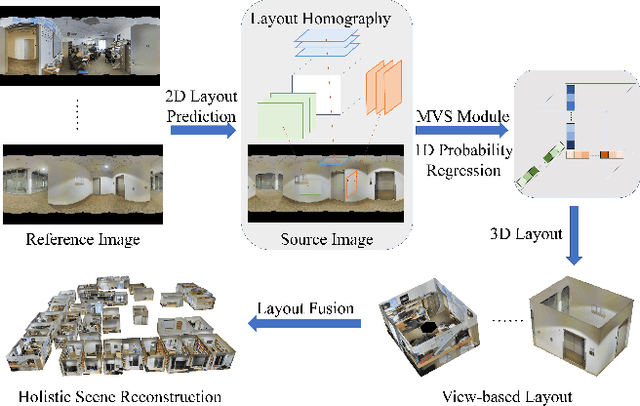
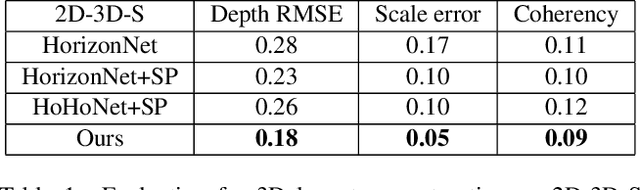
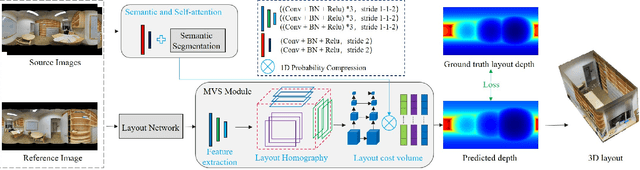

We present MVLayoutNet, an end-to-end network for holistic 3D reconstruction from multi-view panoramas. Our core contribution is to seamlessly combine learned monocular layout estimation and multi-view stereo (MVS) for accurate layout reconstruction in both 3D and image space. We jointly train a layout module to produce an initial layout and a novel MVS module to obtain accurate layout geometry. Unlike standard MVSNet [33], our MVS module takes a newly-proposed layout cost volume, which aggregates multi-view costs at the same depth layer into corresponding layout elements. We additionally provide an attention-based scheme that guides the MVS module to focus on structural regions. Such a design considers both local pixel-level costs and global holistic information for better reconstruction. Experiments show that our method outperforms state-of-the-arts in terms of depth rmse by 21.7% and 20.6% on the 2D-3D-S [1] and ZInD [5] datasets. Finally, our method leads to coherent layout geometry that enables the reconstruction of an entire scene.