 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex VAE with Heavy-Tailed Likelihood for Radar Target Detection in Sea Clutter
Jun 09, 2026To address the heavy-tailed, spike-prone nature of sea clutter and the scarcity of labeled target data, an unsupervised complex-valued variational autoencoder (VAE) for maritime radar target detection is proposed. In implementation, each complex baseband slow-time sequence is represented by its in-phase and quadrature components, and the model learns their joint reconstruction from clutter-only data. A Student-\(t\) negative log-likelihood is adopted to capture heavy-tailed reconstruction errors while reducing sensitivity to outliers during clutter learning. In addition, a time-domain amplitude error constraint is introduced to penalize slow-time magnitude mismatch in the reconstruction. At inference, reconstruction deviation is used as the detection statistic, and the decision threshold is set via an empirical quantile estimated from a clutter-only validation set to enforce a constant false-alarm rate (CFAR). Experiments on measured sea-clutter data show that detection performance is consistently improved over MF, AMF, and a real-valued \(β\)-VAE under CFAR constraints.
BaiJia: A Large Scale Role-Playing Agent Corpus of Chinese Historical Charcaters
Dec 28, 2024



We introduce a comprehensive large-scale role-playing agent corpus, termed BaiJia, that comprises various Chinese historical characters. This corpus is noteworthy for being the pioneering compilation of low-resource data that can be utilized in large language models (LLMs) to engage in AI-driven historical role-playing agents. BaiJia addresses the challenges in terms of fragmented historical textual records in different forms and modalities, integrating various characters' information, including their biographical, literary, family relations, historical events, and so on. We conduct extensive experiments to demonstrate the effectiveness of our BaiJia agent corpus in bolstering the role-playing abilities of various foundational LLMs, and promoting the development and assessment of LLMs in the context of historical role-playing tasks. The agent corpus is available at baijia.online.
Invariant debiasing learning for recommendation via biased imputation
Dec 28, 2024



Previous debiasing studies utilize unbiased data to make supervision of model training. They suffer from the high trial risks and experimental costs to obtain unbiased data. Recent research attempts to use invariant learning to detach the invariant preference of users for unbiased recommendations in an unsupervised way. However, it faces the drawbacks of low model accuracy and unstable prediction performance due to the losing cooperation with variant preference. In this paper, we experimentally demonstrate that invariant learning causes information loss by directly discarding the variant information, which reduces the generalization ability and results in the degradation of model performance in unbiased recommendations. Based on this consideration, we propose a novel lightweight knowledge distillation framework (KDDebias) to automatically learn the unbiased preference of users from both invariant and variant information. Specifically, the variant information is imputed to the invariant user preference in the distance-aware knowledge distillation process. Extensive experiments on three public datasets, i.e., Yahoo!R3, Coat, and MIND, show that with the biased imputation from the variant preference of users, our proposed method achieves significant improvements with less than 50% learning parameters compared to the SOTA unsupervised debiasing model in recommender systems. Our code are publicly available at https://github.com/BAI-LAB/KD-Debias.
GraphLoRA: Empowering LLMs Fine-Tuning via Graph Collaboration of MoE
Dec 18, 2024Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning method that has been widely adopted in various downstream applications of LLMs. Together with the Mixture-of-Expert (MoE) technique, fine-tuning approaches have shown remarkable improvements in model capability. However, the coordination of multiple experts in existing studies solely relies on the weights assigned by the simple router function. Lack of communication and collaboration among experts exacerbate the instability of LLMs due to the imbalance load problem of MoE. To address this issue, we propose a novel MoE graph-based LLM fine-tuning framework GraphLoRA, in which a graph router function is designed to capture the collaboration signals among experts by graph neural networks (GNNs). GraphLoRA enables all experts to understand input knowledge and share information from neighbor experts by aggregating operations. Besides, to enhance each expert's capability and their collaborations, we design two novel coordination strategies: the Poisson distribution-based distinction strategy and the Normal distribution-based load balance strategy. Extensive experiments on four real-world datasets demonstrate the effectiveness of our GraphLoRA in parameter-efficient fine-tuning of LLMs, showing the benefits of facilitating collaborations of multiple experts in the graph router of GraphLoRA.
KG-Retriever: Efficient Knowledge Indexing for Retrieval-Augmented Large Language Models
Dec 07, 2024Large language models with retrieval-augmented generation encounter a pivotal challenge in intricate retrieval tasks, e.g., multi-hop question answering, which requires the model to navigate across multiple documents and generate comprehensive responses based on fragmented information. To tackle this challenge, we introduce a novel Knowledge Graph-based RAG framework with a hierarchical knowledge retriever, termed KG-Retriever. The retrieval indexing in KG-Retriever is constructed on a hierarchical index graph that consists of a knowledge graph layer and a collaborative document layer. The associative nature of graph structures is fully utilized to strengthen intra-document and inter-document connectivity, thereby fundamentally alleviating the information fragmentation problem and meanwhile improving the retrieval efficiency in cross-document retrieval of LLMs. With the coarse-grained collaborative information from neighboring documents and concise information from the knowledge graph, KG-Retriever achieves marked improvements on five public QA datasets, showing the effectiveness and efficiency of our proposed RAG framework.
YOLO-CCA: A Context-Based Approach for Traffic Sign Detection
Dec 05, 2024Traffic sign detection is crucial for improving road safety and advancing autonomous driving technologies. Due to the complexity of driving environments, traffic sign detection frequently encounters a range of challenges, including low resolution, limited feature information, and small object sizes. These challenges significantly hinder the effective extraction of features from traffic signs, resulting in false positives and false negatives in object detection. To address these challenges, it is essential to explore more efficient and accurate approaches for traffic sign detection. This paper proposes a context-based algorithm for traffic sign detection, which utilizes YOLOv7 as the baseline model. Firstly, we propose an adaptive local context feature enhancement (LCFE) module using multi-scale dilation convolution to capture potential relationships between the object and surrounding areas. This module supplements the network with additional local context information. Secondly, we propose a global context feature collection (GCFC) module to extract key location features from the entire image scene as global context information. Finally, we build a Transformer-based context collection augmentation (CCA) module to process the collected local context and global context, which achieves superior multi-level feature fusion results for YOLOv7 without bringing in additional complexity. Extensive experimental studies performed on the Tsinghua-Tencent 100K dataset show that the mAP of our method is 92.1\%. Compared with YOLOv7, our approach improves 3.9\% in mAP, while the amount of parameters is reduced by 2.7M. On the CCTSDB2021 dataset the mAP is improved by 0.9\%. These results show that our approach achieves higher detection accuracy with fewer parameters. The source code is available at \url{https://github.com/zippiest/yolo-cca}.
Emotional RAG: Enhancing Role-Playing Agents through Emotional Retrieval
Oct 30, 2024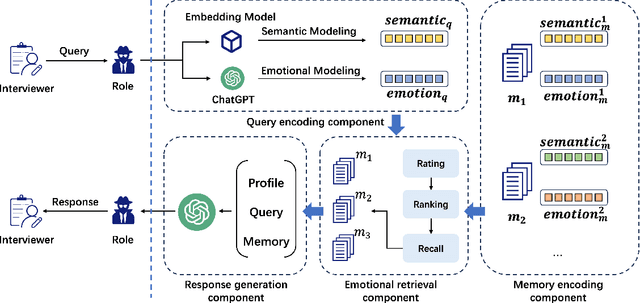

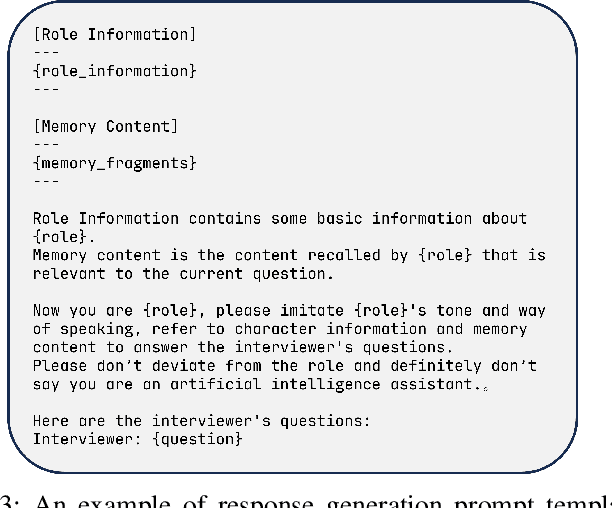

As LLMs exhibit a high degree of human-like capability, increasing attention has been paid to role-playing research areas in which responses generated by LLMs are expected to mimic human replies. This has promoted the exploration of role-playing agents in various applications, such as chatbots that can engage in natural conversations with users and virtual assistants that can provide personalized support and guidance. The crucial factor in the role-playing task is the effective utilization of character memory, which stores characters' profiles, experiences, and historical dialogues. Retrieval Augmented Generation (RAG) technology is used to access the related memory to enhance the response generation of role-playing agents. Most existing studies retrieve related information based on the semantic similarity of memory to maintain characters' personalized traits, and few attempts have been made to incorporate the emotional factor in the retrieval argument generation (RAG) of LLMs. Inspired by the Mood-Dependent Memory theory, which indicates that people recall an event better if they somehow reinstate during recall the original emotion they experienced during learning, we propose a novel emotion-aware memory retrieval framework, termed Emotional RAG, which recalls the related memory with consideration of emotional state in role-playing agents. Specifically, we design two kinds of retrieval strategies, i.e., combination strategy and sequential strategy, to incorporate both memory semantic and emotional states during the retrieval process. Extensive experiments on three representative role-playing datasets demonstrate that our Emotional RAG framework outperforms the method without considering the emotional factor in maintaining the personalities of role-playing agents. This provides evidence to further reinforce the Mood-Dependent Memory theory in psychology.
Efficient Multi-task Prompt Tuning for Recommendation
Aug 30, 2024



With the expansion of business scenarios, real recommender systems are facing challenges in dealing with the constantly emerging new tasks in multi-task learning frameworks. In this paper, we attempt to improve the generalization ability of multi-task recommendations when dealing with new tasks. We find that joint training will enhance the performance of the new task but always negatively impact existing tasks in most multi-task learning methods. Besides, such a re-training mechanism with new tasks increases the training costs, limiting the generalization ability of multi-task recommendation models. Based on this consideration, we aim to design a suitable sharing mechanism among different tasks while maintaining joint optimization efficiency in new task learning. A novel two-stage prompt-tuning MTL framework (MPT-Rec) is proposed to address task irrelevance and training efficiency problems in multi-task recommender systems. Specifically, we disentangle the task-specific and task-sharing information in the multi-task pre-training stage, then use task-aware prompts to transfer knowledge from other tasks to the new task effectively. By freezing parameters in the pre-training tasks, MPT-Rec solves the negative impacts that may be brought by the new task and greatly reduces the training costs. Extensive experiments on three real-world datasets show the effectiveness of our proposed multi-task learning framework. MPT-Rec achieves the best performance compared to the SOTA multi-task learning method. Besides, it maintains comparable model performance but vastly improves the training efficiency (i.e., with up to 10% parameters in the full training way) in the new task learning.
Learning Social Graph for Inactive User Recommendation
May 08, 2024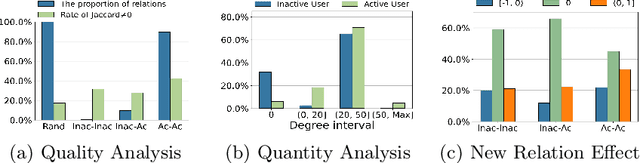

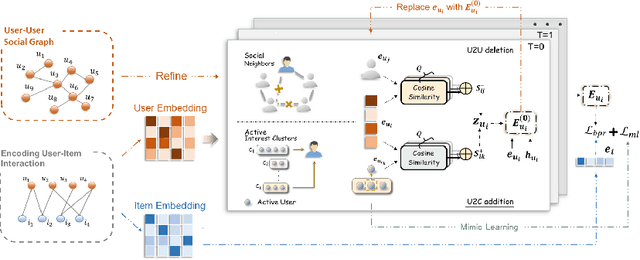
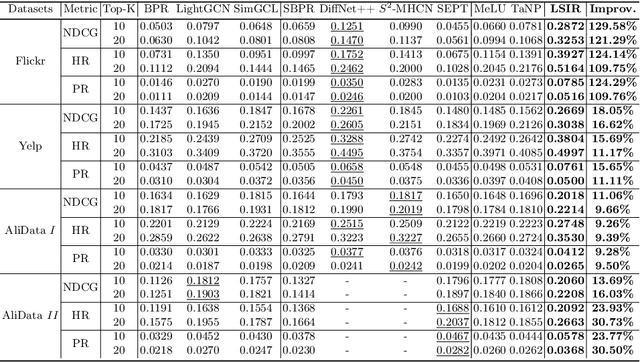
Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.
Towards Graph Foundation Models: A Survey and Beyond
Oct 18, 2023Emerging as fundamental building blocks for diverse artificial intelligence applications, foundation models have achieved notable success across natural language processing and many other domains. Parallelly, graph machine learning has witnessed a transformative shift, with shallow methods giving way to deep learning approaches. The emergence and homogenization capabilities of foundation models have piqued the interest of graph machine learning researchers, sparking discussions about developing the next graph learning paradigm that is pre-trained on broad graph data and can be adapted to a wide range of downstream graph tasks. However, there is currently no clear definition and systematic analysis for this type of work. In this article, we propose the concept of graph foundation models (GFMs), and provide the first comprehensive elucidation on their key characteristics and technologies. Following that, we categorize existing works towards GFMs into three categories based on their reliance on graph neural networks and large language models. Beyond providing a comprehensive overview of the current landscape of graph foundation models, this article also discusses potential research directions for this evolving field.