 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-task Prompt Tuning for Recommendation
Aug 30, 2024



With the expansion of business scenarios, real recommender systems are facing challenges in dealing with the constantly emerging new tasks in multi-task learning frameworks. In this paper, we attempt to improve the generalization ability of multi-task recommendations when dealing with new tasks. We find that joint training will enhance the performance of the new task but always negatively impact existing tasks in most multi-task learning methods. Besides, such a re-training mechanism with new tasks increases the training costs, limiting the generalization ability of multi-task recommendation models. Based on this consideration, we aim to design a suitable sharing mechanism among different tasks while maintaining joint optimization efficiency in new task learning. A novel two-stage prompt-tuning MTL framework (MPT-Rec) is proposed to address task irrelevance and training efficiency problems in multi-task recommender systems. Specifically, we disentangle the task-specific and task-sharing information in the multi-task pre-training stage, then use task-aware prompts to transfer knowledge from other tasks to the new task effectively. By freezing parameters in the pre-training tasks, MPT-Rec solves the negative impacts that may be brought by the new task and greatly reduces the training costs. Extensive experiments on three real-world datasets show the effectiveness of our proposed multi-task learning framework. MPT-Rec achieves the best performance compared to the SOTA multi-task learning method. Besides, it maintains comparable model performance but vastly improves the training efficiency (i.e., with up to 10% parameters in the full training way) in the new task learning.
Dynamic data sampler for cross-language transfer learning in large language models
May 17, 2024Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
Weight-Inherited Distillation for Task-Agnostic BERT Compression
May 16, 2023Knowledge Distillation (KD) is a predominant approach for BERT compression. Previous KD-based methods focus on designing extra alignment losses for the student model to mimic the behavior of the teacher model. These methods transfer the knowledge in an indirect way. In this paper, we propose a novel Weight-Inherited Distillation (WID), which directly transfers knowledge from the teacher. WID does not require any additional alignment loss and trains a compact student by inheriting the weights, showing a new perspective of knowledge distillation. Specifically, we design the row compactors and column compactors as mappings and then compress the weights via structural re-parameterization. Experimental results on the GLUE and SQuAD benchmarks show that WID outperforms previous state-of-the-art KD-based baselines. Further analysis indicates that WID can also learn the attention patterns from the teacher model without any alignment loss on attention distributions.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022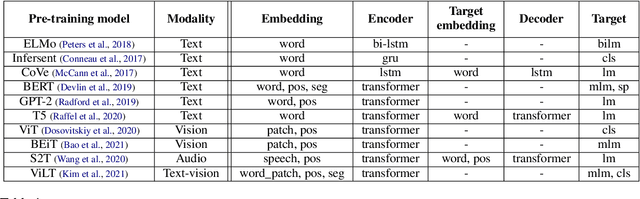
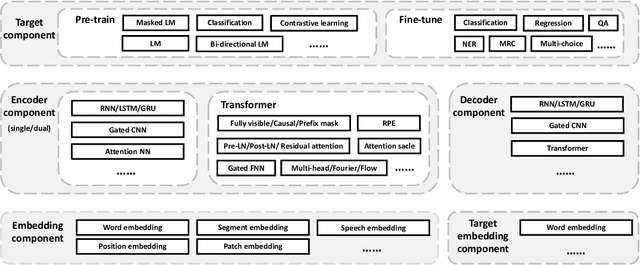
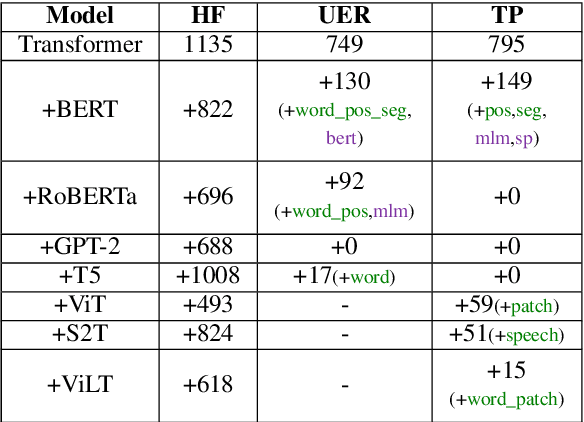
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.