 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving with DINO: Vision Foundation Features as a Unified Bridge for Sim-to-Real Generation in Autonomous Driving
Feb 09, 2026Driven by the emergence of Controllable Video Diffusion, existing Sim2Real methods for autonomous driving video generation typically rely on explicit intermediate representations to bridge the domain gap. However, these modalities face a fundamental Consistency-Realism Dilemma. Low-level signals (e.g., edges, blurred images) ensure precise control but compromise realism by "baking in" synthetic artifacts, whereas high-level priors (e.g., depth, semantics, HDMaps) facilitate photorealism but lack the structural detail required for consistent guidance. In this work, we present Driving with DINO (DwD), a novel framework that leverages Vision Foundation Module (VFM) features as a unified bridge between the simulation and real-world domains. We first identify that these features encode a spectrum of information, from high-level semantics to fine-grained structure. To effectively utilize this, we employ Principal Subspace Projection to discard the high-frequency elements responsible for "texture baking," while concurrently introducing Random Channel Tail Drop to mitigate the structural loss inherent in rigid dimensionality reduction, thereby reconciling realism with control consistency. Furthermore, to fully leverage DINOv3's high-resolution capabilities for enhancing control precision, we introduce a learnable Spatial Alignment Module that adapts these high-resolution features to the diffusion backbone. Finally, we propose a Causal Temporal Aggregator employing causal convolutions to explicitly preserve historical motion context when integrating frame-wise DINO features, which effectively mitigates motion blur and guarantees temporal stability. Project page: https://albertchen98.github.io/DwD-project/
HierLoc: Hyperbolic Entity Embeddings for Hierarchical Visual Geolocation
Jan 30, 2026Visual geolocalization, the task of predicting where an image was taken, remains challenging due to global scale, visual ambiguity, and the inherently hierarchical structure of geography. Existing paradigms rely on either large-scale retrieval, which requires storing a large number of image embeddings, grid-based classifiers that ignore geographic continuity, or generative models that diffuse over space but struggle with fine detail. We introduce an entity-centric formulation of geolocation that replaces image-to-image retrieval with a compact hierarchy of geographic entities embedded in Hyperbolic space. Images are aligned directly to country, region, subregion, and city entities through Geo-Weighted Hyperbolic contrastive learning by directly incorporating haversine distance into the contrastive objective. This hierarchical design enables interpretable predictions and efficient inference with 240k entity embeddings instead of over 5 million image embeddings on the OSV5M benchmark, on which our method establishes a new state-of-the-art performance. Compared to the current methods in the literature, it reduces mean geodesic error by 19.5\%, while improving the fine-grained subregion accuracy by 43%. These results demonstrate that geometry-aware hierarchical embeddings provide a scalable and conceptually new alternative for global image geolocation.
A Deep Dive into OpenStreetMap Research Since its Inception (2008-2024): Contributors, Topics, and Future Trends
Jan 14, 2026OpenStreetMap (OSM) has transitioned from a pioneering volunteered geographic information (VGI) project into a global, multi-disciplinary research nexus. This study presents a bibliometric and systematic analysis of the OSM research landscape, examining its development trajectory and key driving forces. By evaluating 1,926 publications from the Web of Science (WoS) Core Collection and 782 State of the Map (SotM) presentations up to June 2024, we quantify publication growth, collaboration patterns, and thematic evolution. Results demonstrate simultaneous consolidation and diversification within the field. While a stable core of contributors continues to anchor OSM research, themes have shifted from initial concerns over data production and quality toward advanced analytical and applied uses. Comparative analysis of OSM-related research in WoS and SotM reveals distinct but complementary agendas between scholars and the OSM community. Building on these findings, we identify six emerging research directions and discuss how evolving partnerships among academia, the OSM community, and industry are poised to shape the future of OSM research. This study establishes a structured reference for understanding the state of OSM studies and offers strategic pathways for navigating its future trajectory.The data and code are available at https://github.com/ya0-sun/OSMbib.
MeSS: City Mesh-Guided Outdoor Scene Generation with Cross-View Consistent Diffusion
Aug 21, 2025Mesh models have become increasingly accessible for numerous cities; however, the lack of realistic textures restricts their application in virtual urban navigation and autonomous driving. To address this, this paper proposes MeSS (Meshbased Scene Synthesis) for generating high-quality, styleconsistent outdoor scenes with city mesh models serving as the geometric prior. While image and video diffusion models can leverage spatial layouts (such as depth maps or HD maps) as control conditions to generate street-level perspective views, they are not directly applicable to 3D scene generation. Video diffusion models excel at synthesizing consistent view sequences that depict scenes but often struggle to adhere to predefined camera paths or align accurately with rendered control videos. In contrast, image diffusion models, though unable to guarantee cross-view visual consistency, can produce more geometry-aligned results when combined with ControlNet. Building on this insight, our approach enhances image diffusion models by improving cross-view consistency. The pipeline comprises three key stages: first, we generate geometrically consistent sparse views using Cascaded Outpainting ControlNets; second, we propagate denser intermediate views via a component dubbed AGInpaint; and third, we globally eliminate visual inconsistencies (e.g., varying exposure) using the GCAlign module. Concurrently with generation, a 3D Gaussian Splatting (3DGS) scene is reconstructed by initializing Gaussian balls on the mesh surface. Our method outperforms existing approaches in both geometric alignment and generation quality. Once synthesized, the scene can be rendered in diverse styles through relighting and style transfer techniques.
Towards a Barrier-free GeoQA Portal: Natural Language Interaction with Geospatial Data Using Multi-Agent LLMs and Semantic Search
Mar 18, 2025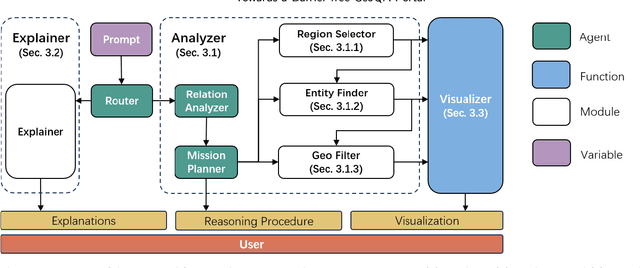
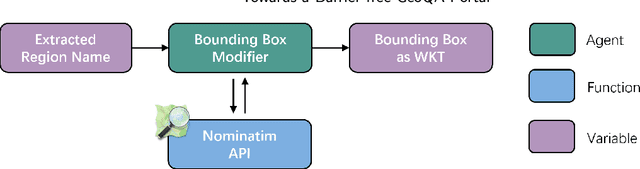

A Barrier-Free GeoQA Portal: Enhancing Geospatial Data Accessibility with a Multi-Agent LLM Framework Geoportals are vital for accessing and analyzing geospatial data, promoting open spatial data sharing and online geo-information management. Designed with GIS-like interaction and layered visualization, they often challenge non-expert users with complex functionalities and overlapping layers that obscure spatial relationships. We propose a GeoQA Portal using a multi-agent Large Language Model framework for seamless natural language interaction with geospatial data. Complex queries are broken into subtasks handled by specialized agents, retrieving relevant geographic data efficiently. Task plans are shown to users, boosting transparency. The portal supports default and custom data inputs for flexibility. Semantic search via word vector similarity aids data retrieval despite imperfect terms. Case studies, evaluations, and user tests confirm its effectiveness for non-experts, bridging GIS complexity and public access, and offering an intuitive solution for future geoportals.
Interpreting core forms of urban morphology linked to urban functions with explainable graph neural network
Feb 22, 2025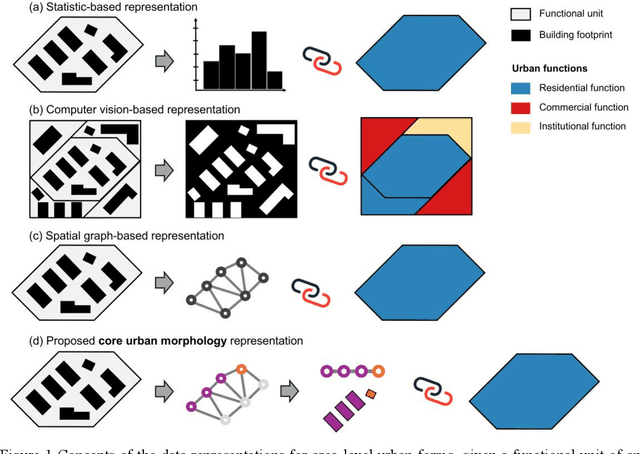

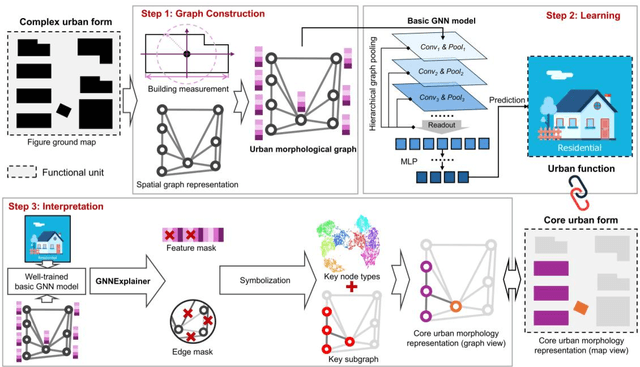
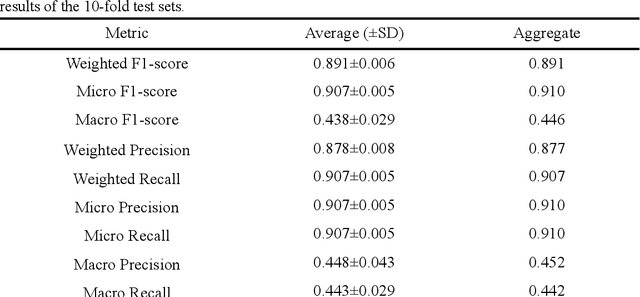
Understanding the high-order relationship between urban form and function is essential for modeling the underlying mechanisms of sustainable urban systems. Nevertheless, it is challenging to establish an accurate data representation for complex urban forms that are readily explicable in human terms. This study proposed the concept of core urban morphology representation and developed an explainable deep learning framework for explicably symbolizing complex urban forms into the novel representation, which we call CoMo. By interpretating the well-trained deep learning model with a stable weighted F1-score of 89.14%, CoMo presents a promising approach for revealing links between urban function and urban form in terms of core urban morphology representation. Using Boston as a study area, we analyzed the core urban forms at the individual-building, block, and neighborhood level that are important to corresponding urban functions. The residential core forms follow a gradual morphological pattern along the urban spine, which is consistent with a center-urban-suburban transition. Furthermore, we prove that urban morphology directly affects land use efficiency, which has a significantly strong correlation with the location (R2=0.721, p<0.001). Overall, CoMo can explicably symbolize urban forms, provide evidence for the classic urban location theory, and offer mechanistic insights for digital twins.
GeoConformal prediction: a model-agnostic framework of measuring the uncertainty of spatial prediction
Dec 05, 2024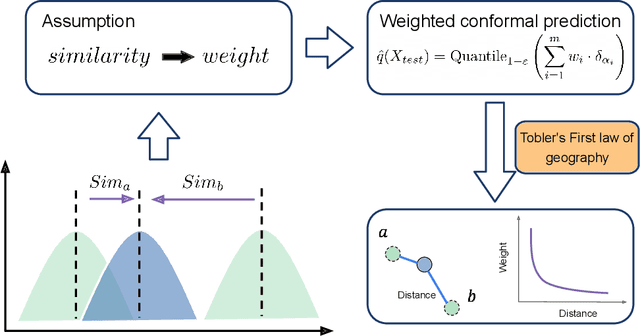

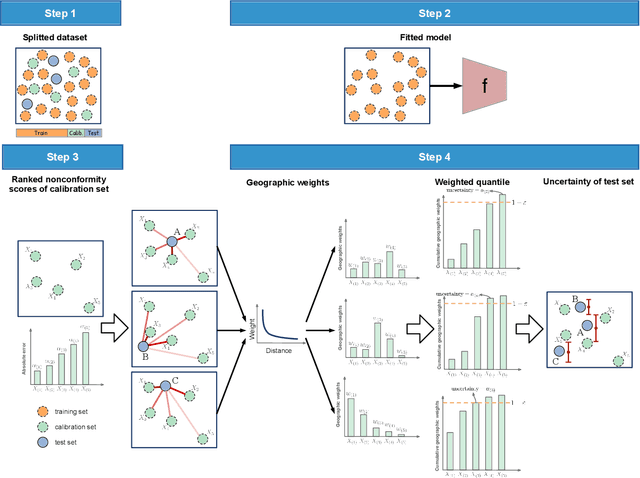
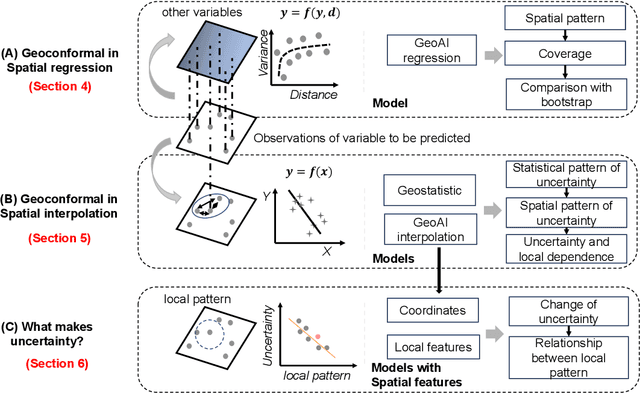
Spatial prediction is a fundamental task in geography. In recent years, with advances in geospatial artificial intelligence (GeoAI), numerous models have been developed to improve the accuracy of geographic variable predictions. Beyond achieving higher accuracy, it is equally important to obtain predictions with uncertainty measures to enhance model credibility and support responsible spatial prediction. Although geostatistic methods like Kriging offer some level of uncertainty assessment, such as Kriging variance, these measurements are not always accurate and lack general applicability to other spatial models. To address this issue, we propose a model-agnostic uncertainty assessment method called GeoConformal Prediction, which incorporates geographical weighting into conformal prediction. We applied it to two classic spatial prediction cases, spatial regression and spatial interpolation, to evaluate its reliability. First, in the spatial regression case, we used XGBoost to predict housing prices, followed by GeoConformal to calculate uncertainty. Our results show that GeoConformal achieved a coverage rate of 93.67%, while Bootstrap methods only reached a maximum coverage of 68.33% after 2000 runs. Next, we applied GeoConformal to spatial interpolation models. We found that the uncertainty obtained from GeoConformal aligned closely with the variance in Kriging. Finally, using GeoConformal, we analyzed the sources of uncertainty in spatial prediction. We found that explicitly including local features in AI models can significantly reduce prediction uncertainty, especially in areas with strong local dependence. Our findings suggest that GeoConformal holds potential not only for geographic knowledge discovery but also for guiding the design of future GeoAI models, paving the way for more reliable and interpretable spatial prediction frameworks.
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
Box2Poly: Memory-Efficient Polygon Prediction of Arbitrarily Shaped and Rotated Text
Sep 20, 2023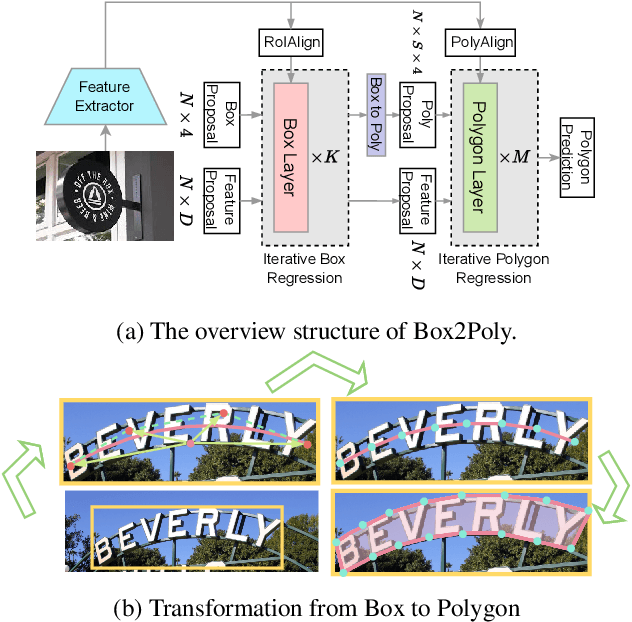

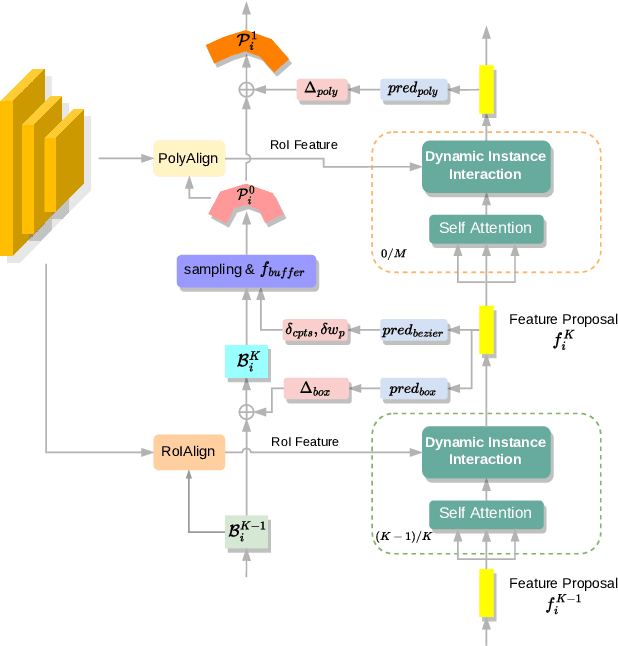

Recently, Transformer-based text detection techniques have sought to predict polygons by encoding the coordinates of individual boundary vertices using distinct query features. However, this approach incurs a significant memory overhead and struggles to effectively capture the intricate relationships between vertices belonging to the same instance. Consequently, irregular text layouts often lead to the prediction of outlined vertices, diminishing the quality of results. To address these challenges, we present an innovative approach rooted in Sparse R-CNN: a cascade decoding pipeline for polygon prediction. Our method ensures precision by iteratively refining polygon predictions, considering both the scale and location of preceding results. Leveraging this stabilized regression pipeline, even employing just a single feature vector to guide polygon instance regression yields promising detection results. Simultaneously, the leverage of instance-level feature proposal substantially enhances memory efficiency (>50% less vs. the state-of-the-art method DPText-DETR) and reduces inference speed (>40% less vs. DPText-DETR) with minor performance drop on benchmarks.
Towards Large-scale Building Attribute Mapping using Crowdsourced Images: Scene Text Recognition on Flickr and Problems to be Solved
Sep 14, 2023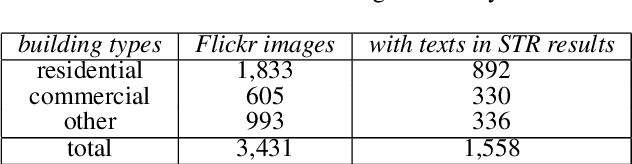

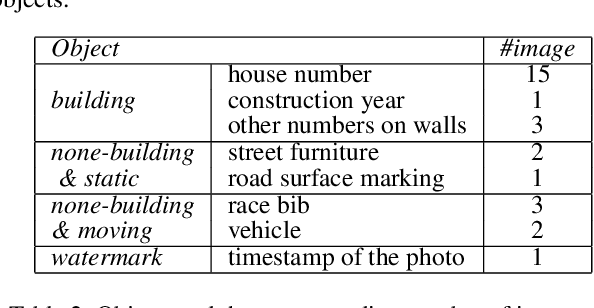

Crowdsourced platforms provide huge amounts of street-view images that contain valuable building information. This work addresses the challenges in applying Scene Text Recognition (STR) in crowdsourced street-view images for building attribute mapping. We use Flickr images, particularly examining texts on building facades. A Berlin Flickr dataset is created, and pre-trained STR models are used for text detection and recognition. Manual checking on a subset of STR-recognized images demonstrates high accuracy. We examined the correlation between STR results and building functions, and analysed instances where texts were recognized on residential buildings but not on commercial ones. Further investigation revealed significant challenges associated with this task, including small text regions in street-view images, the absence of ground truth labels, and mismatches in buildings in Flickr images and building footprints in OpenStreetMap (OSM). To develop city-wide mapping beyond urban hotspot locations, we suggest differentiating the scenarios where STR proves effective while developing appropriate algorithms or bringing in additional data for handling other cases. Furthermore, interdisciplinary collaboration should be undertaken to understand the motivation behind building photography and labeling. The STR-on-Flickr results are publicly available at https://github.com/ya0-sun/STR-Berlin.