 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDODGE: Ontology-Aware Risk Assessment via Object-Oriented Disruption Graphs
Dec 18, 2024When considering risky events or actions, we must not downplay the role of involved objects: a charged battery in our phone averts the risk of being stranded in the desert after a flat tyre, and a functional firewall mitigates the risk of a hacker intruding the network. The Common Ontology of Value and Risk (COVER) highlights how the role of objects and their relationships remains pivotal to performing transparent, complete and accountable risk assessment. In this paper, we operationalize some of the notions proposed by COVER -- such as parthood between objects and participation of objects in events/actions -- by presenting a new framework for risk assessment: DODGE. DODGE enriches the expressivity of vetted formal models for risk -- i.e., fault trees and attack trees -- by bridging the disciplines of ontology and formal methods into an ontology-aware formal framework composed by a more expressive modelling formalism, Object-Oriented Disruption Graphs (ODGs), logic (ODGLog) and an intermediate query language (ODGLang). With these, DODGE allows risk assessors to pose questions about disruption propagation, disruption likelihood and risk levels, keeping the fundamental role of objects at risk always in sight.
Mining Frequent Structures in Conceptual Models
Jun 11, 2024



The problem of using structured methods to represent knowledge is well-known in conceptual modeling and has been studied for many years. It has been proven that adopting modeling patterns represents an effective structural method. Patterns are, indeed, generalizable recurrent structures that can be exploited as solutions to design problems. They aid in understanding and improving the process of creating models. The undeniable value of using patterns in conceptual modeling was demonstrated in several experimental studies. However, discovering patterns in conceptual models is widely recognized as a highly complex task and a systematic solution to pattern identification is currently lacking. In this paper, we propose a general approach to the problem of discovering frequent structures, as they occur in conceptual modeling languages. As proof of concept for our scientific contribution, we provide an implementation of the approach, by focusing on UML class diagrams, in particular OntoUML models. This implementation comprises an exploratory tool, which, through the combination of a frequent subgraph mining algorithm and graph manipulation techniques, can process multiple conceptual models and discover recurrent structures according to multiple criteria. The primary objective is to offer a support facility for language engineers. This can be employed to leverage both good and bad modeling practices, to evolve and maintain the conceptual modeling language, and to promote the reuse of encoded experience in designing better models with the given language.
Towards a Gateway for Knowledge Graph Schemas Collection, Analysis, and Embedding
Nov 21, 2023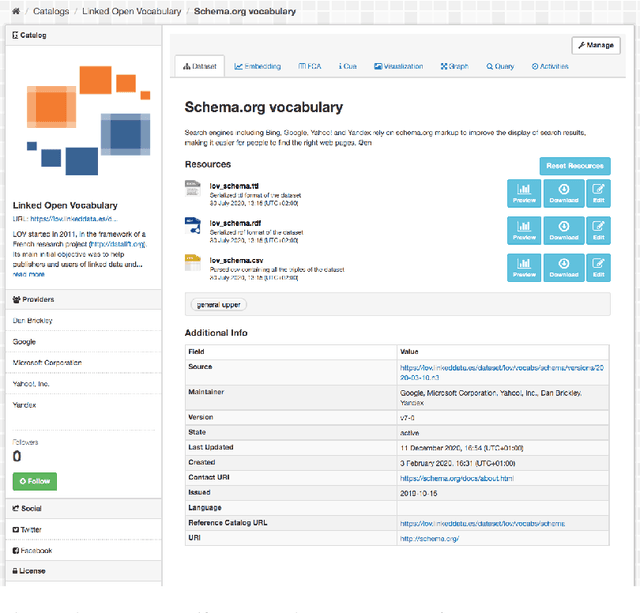
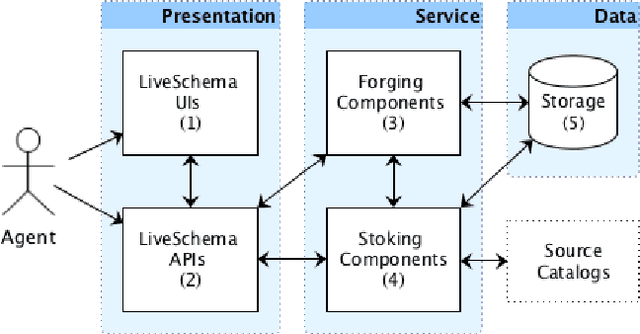
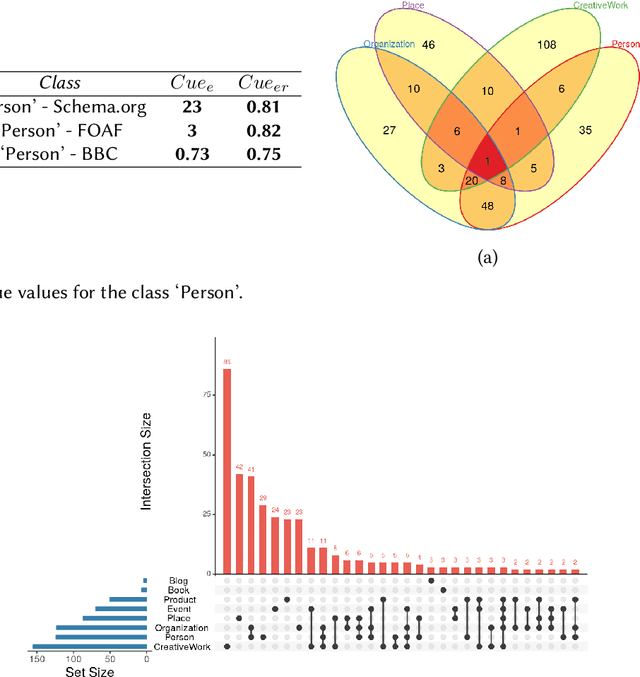
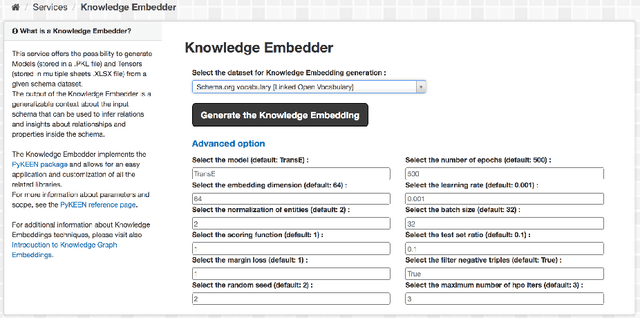
One of the significant barriers to the training of statistical models on knowledge graphs is the difficulty that scientists have in finding the best input data to address their prediction goal. In addition to this, a key challenge is to determine how to manipulate these relational data, which are often in the form of particular triples (i.e., subject, predicate, object), to enable the learning process. Currently, many high-quality catalogs of knowledge graphs, are available. However, their primary goal is the re-usability of these resources, and their interconnection, in the context of the Semantic Web. This paper describes the LiveSchema initiative, namely, a first version of a gateway that has the main scope of leveraging the gold mine of data collected by many existing catalogs collecting relational data like ontologies and knowledge graphs. At the current state, LiveSchema contains - 1000 datasets from 4 main sources and offers some key facilities, which allow to: i) evolving LiveSchema, by aggregating other source catalogs and repositories as input sources; ii) querying all the collected resources; iii) transforming each given dataset into formal concept analysis matrices that enable analysis and visualization services; iv) generating models and tensors from each given dataset.
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
Towards Ranking Schemas by Focus
Feb 27, 2023The main goal of this paper is to evaluate knowledge base schemas, modeled as a set of entity types, each such type being associated with a set of properties, according to their focus. We intuitively model the notion of focus as ''the state or quality of being relevant in storing and retrieving information''. This definition of focus is adapted from the notion of ''categorization purpose'', as first defined in cognitive psychology, thus giving us a high level of understandability on the side of users. In turn, this notion is formalized based on a set of knowledge metrics that, for any given focus, rank knowledge base schemas according to their quality. We apply the proposed methodology to more than 200 state-of-the-art knowledge base schemas. The experimental results show the utility of our approach
Popularity Driven Data Integration
Sep 28, 2022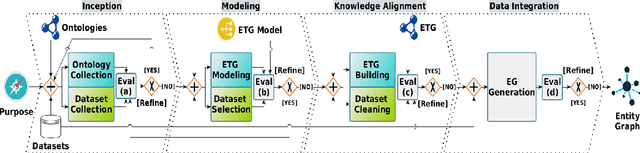
More and more, with the growing focus on large scale analytics, we are confronted with the need of integrating data from multiple sources. The problem is that these data are impossible to reuse as-is. The net result is high cost, with the further drawback that the resulting integrated data will again be hardly reusable as-is. iTelos is a general purpose methodology aiming at minimizing the effects of this process. The intuition is that data will be treated differently based on their popularity: the more a certain set of data have been reused, the more they will be reused and the less they will be changed across reuses, thus decreasing the overall data preprocessing costs, while increasing backward compatibility and future sharing
LiveSchema: A Gateway Towards Learning on Knowledge Graph Schemas
Jul 13, 2022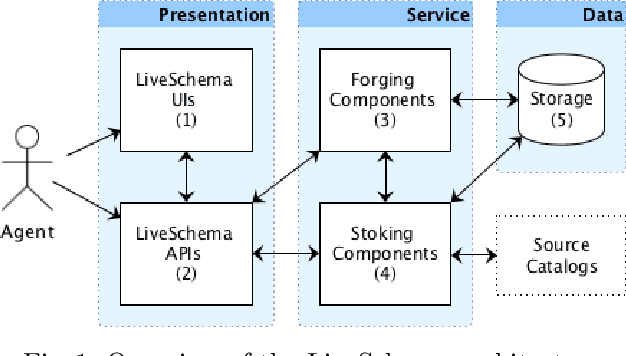
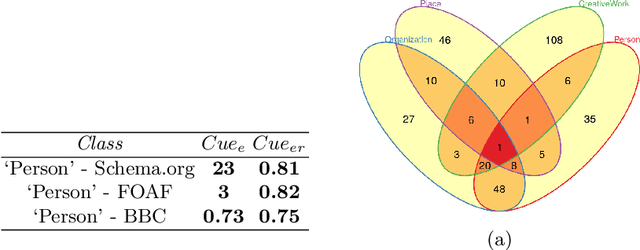
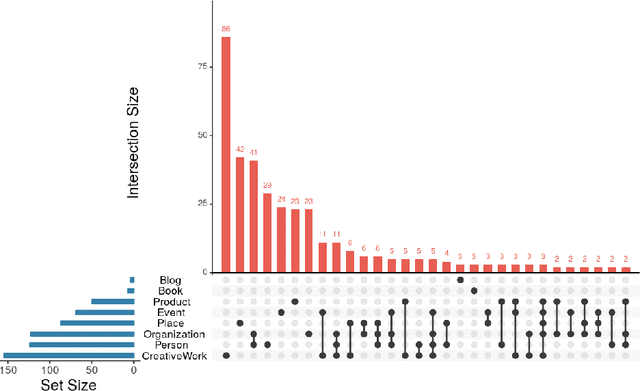
One of the major barriers to the training of algorithms on knowledge graph schemas, such as vocabularies or ontologies, is the difficulty that scientists have in finding the best input resource to address the target prediction tasks. In addition to this, a key challenge is to determine how to manipulate (and embed) these data, which are often in the form of particular triples (i.e., subject, predicate, object), to enable the learning process. In this paper, we describe the LiveSchema initiative, namely a gateway that offers a family of services to easily access, analyze, transform and exploit knowledge graph schemas, with the main goal of facilitating the reuse of these resources in machine learning use cases. As an early implementation of the initiative, we also advance an online catalog, which relies on more than 800 resources, with the first set of example services.
iTelos- Building reusable knowledge graphs
May 19, 2021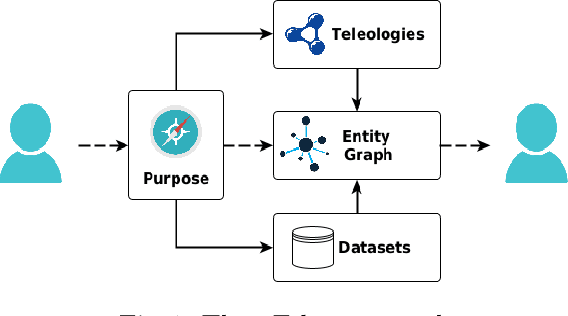

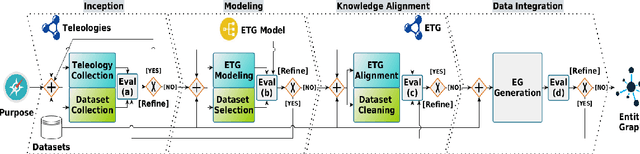

It is a fact that, when developing a new application, it is virtually impossible to reuse, as-is, existing datasets. This difficulty is the cause of additional costs, with the further drawback that the resulting application will again be hardly reusable. It is a negative loop which consistently reinforces itself and for which there seems to be no way out. iTelos is a general purpose methodology designed to break this loop. Its main goal is to generate reusable Knowledge Graphs (KGs), built reusing, as much as possible, already existing data. The key assumption is that the design of a KG should be done middle-out meaning by this that the design should take into consideration, in all phases of the development: (i) the purpose to be served, that we formalize as a set of competency queries, (ii) a set of pre-existing datasets, possibly extracted from existing KGs, and (iii) a set of pre-existing reference schemas, whose goal is to facilitate sharability. We call these reference schemas, teleologies, as distinct from ontologies, meaning by this that, while having a similar purpose, they are designed to be easily adapted, thus becoming a key enabler of itelos.